 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Active Learning for the Search of Small-molecule Protein Binders
May 02, 2024



Despite substantial progress in machine learning for scientific discovery in recent years, truly de novo design of small molecules which exhibit a property of interest remains a significant challenge. We introduce LambdaZero, a generative active learning approach to search for synthesizable molecules. Powered by deep reinforcement learning, LambdaZero learns to search over the vast space of molecules to discover candidates with a desired property. We apply LambdaZero with molecular docking to design novel small molecules that inhibit the enzyme soluble Epoxide Hydrolase 2 (sEH), while enforcing constraints on synthesizability and drug-likeliness. LambdaZero provides an exponential speedup in terms of the number of calls to the expensive molecular docking oracle, and LambdaZero de novo designed molecules reach docking scores that would otherwise require the virtual screening of a hundred billion molecules. Importantly, LambdaZero discovers novel scaffolds of synthesizable, drug-like inhibitors for sEH. In in vitro experimental validation, a series of ligands from a generated quinazoline-based scaffold were synthesized, and the lead inhibitor N-(4,6-di(pyrrolidin-1-yl)quinazolin-2-yl)-N-methylbenzamide (UM0152893) displayed sub-micromolar enzyme inhibition of sEH.
Semi-Supervised Deep Learning for Multiplex Networks
Oct 05, 2021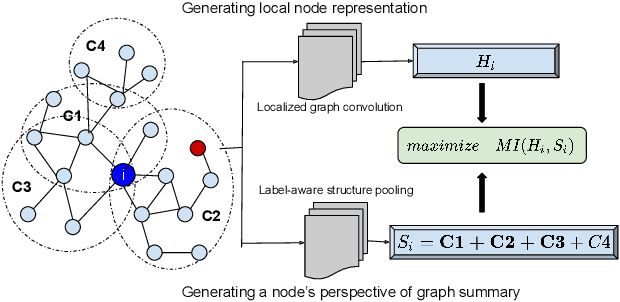
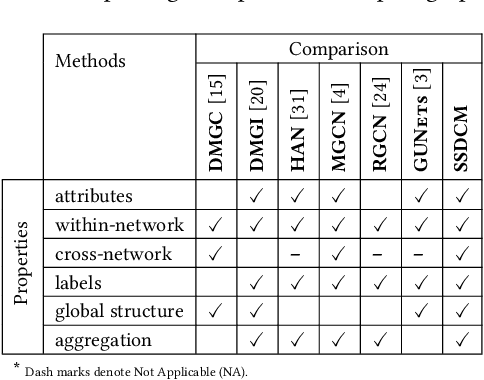
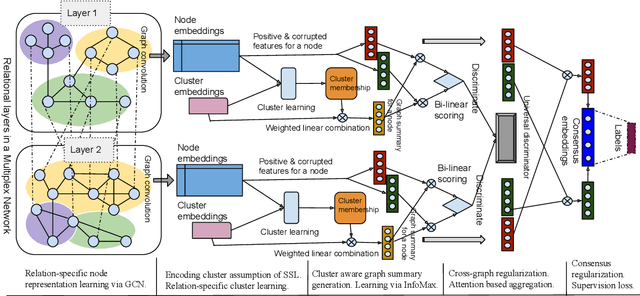
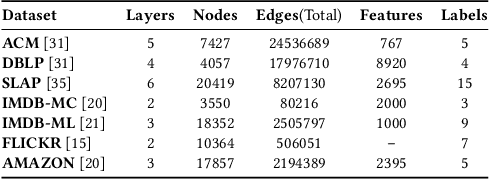
Multiplex networks are complex graph structures in which a set of entities are connected to each other via multiple types of relations, each relation representing a distinct layer. Such graphs are used to investigate many complex biological, social, and technological systems. In this work, we present a novel semi-supervised approach for structure-aware representation learning on multiplex networks. Our approach relies on maximizing the mutual information between local node-wise patch representations and label correlated structure-aware global graph representations to model the nodes and cluster structures jointly. Specifically, it leverages a novel cluster-aware, node-contextualized global graph summary generation strategy for effective joint-modeling of node and cluster representations across the layers of a multiplex network. Empirically, we demonstrate that the proposed architecture outperforms state-of-the-art methods in a range of tasks: classification, clustering, visualization, and similarity search on seven real-world multiplex networks for various experiment settings.
Ego-GNNs: Exploiting Ego Structures in Graph Neural Networks
Jul 22, 2021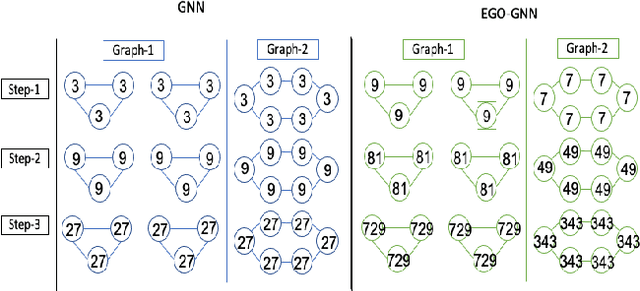

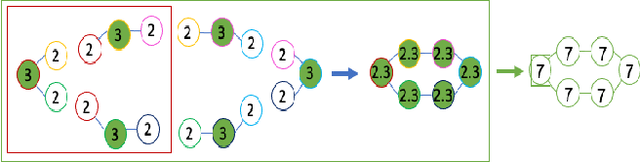
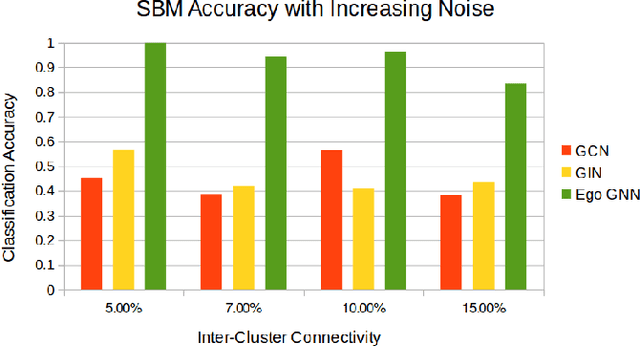
Graph neural networks (GNNs) have achieved remarkable success as a framework for deep learning on graph-structured data. However, GNNs are fundamentally limited by their tree-structured inductive bias: the WL-subtree kernel formulation bounds the representational capacity of GNNs, and polynomial-time GNNs are provably incapable of recognizing triangles in a graph. In this work, we propose to augment the GNN message-passing operations with information defined on ego graphs (i.e., the induced subgraph surrounding each node). We term these approaches Ego-GNNs and show that Ego-GNNs are provably more powerful than standard message-passing GNNs. In particular, we show that Ego-GNNs are capable of recognizing closed triangles, which is essential given the prominence of transitivity in real-world graphs. We also motivate our approach from the perspective of graph signal processing as a form of multiplex graph convolution. Experimental results on node classification using synthetic and real data highlight the achievable performance gains using this approach.
* Submitted to a special session of IEEE-ICASSP 2021
On Incorporating Structural Information to improve Dialogue Response Generation
May 28, 2020
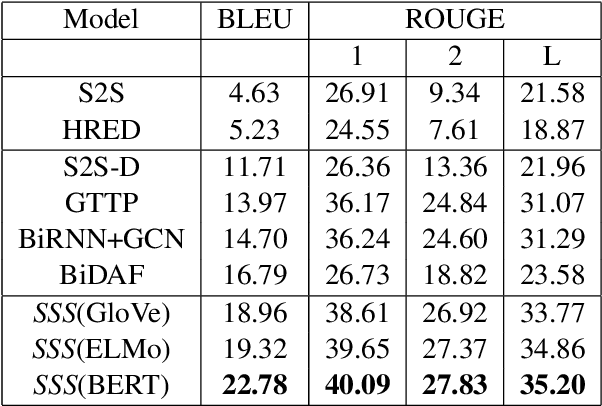
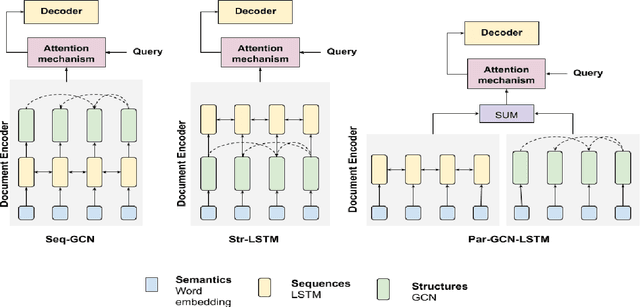
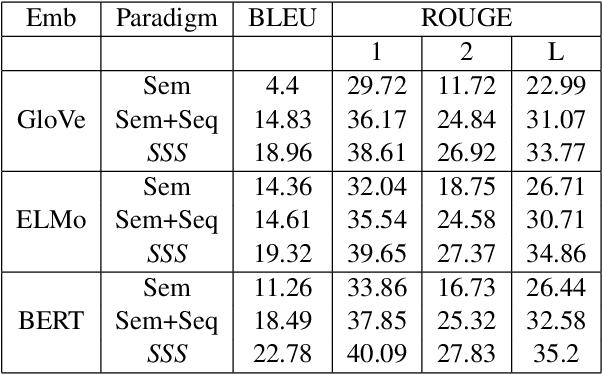
We consider the task of generating dialogue responses from background knowledge comprising of domain specific resources. Specifically, given a conversation around a movie, the task is to generate the next response based on background knowledge about the movie such as the plot, review, Reddit comments etc. This requires capturing structural, sequential and semantic information from the conversation context and the background resources. This is a new task and has not received much attention from the community. We propose a new architecture that uses the ability of BERT to capture deep contextualized representations in conjunction with explicit structure and sequence information. More specifically, we use (i) Graph Convolutional Networks (GCNs) to capture structural information, (ii) LSTMs to capture sequential information and (iii) BERT for the deep contextualized representations that capture semantic information. We analyze the proposed architecture extensively. To this end, we propose a plug-and-play Semantics-Sequences-Structures (SSS) framework which allows us to effectively combine such linguistic information. Through a series of experiments we make some interesting observations. First, we observe that the popular adaptation of the GCN model for NLP tasks where structural information (GCNs) was added on top of sequential information (LSTMs) performs poorly on our task. This leads us to explore interesting ways of combining semantic and structural information to improve the performance. Second, we observe that while BERT already outperforms other deep contextualized representations such as ELMo, it still benefits from the additional structural information explicitly added using GCNs. This is a bit surprising given the recent claims that BERT already captures structural information. Lastly, the proposed SSS framework gives an improvement of 7.95% over the baseline.
Understanding Dynamic Scenes using Graph Convolution Networks
May 15, 2020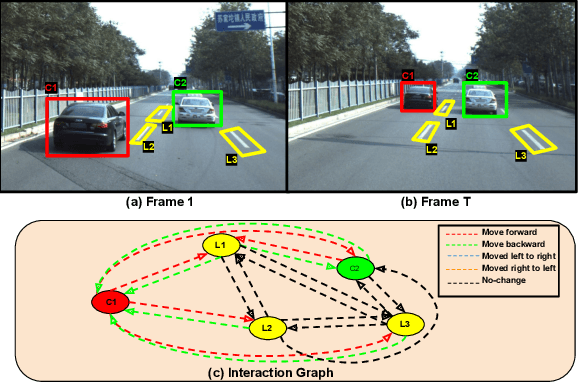
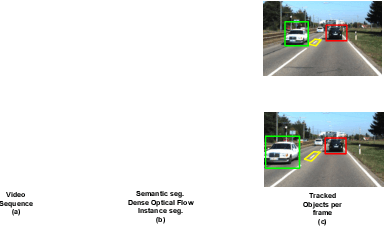
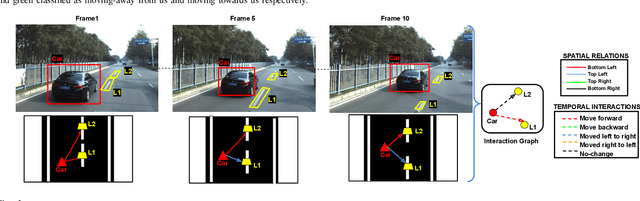
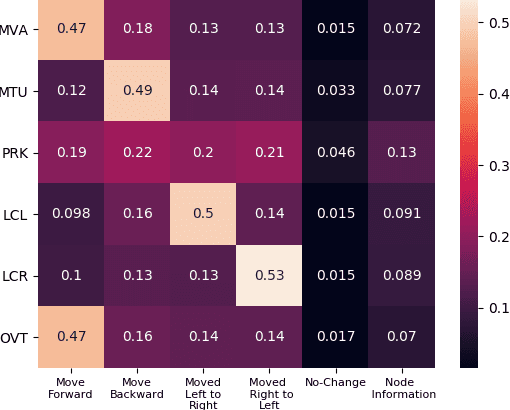
We present a novel Multi Relational Graph Convolutional Network (MRGCN) to model on-road vehicle behaviours from a sequence of temporally ordered frames as grabbed by a moving monocular camera. The input to MRGCN is a Multi Relational Graph (MRG) where the nodes of the graph represent the active and passive participants/agents in the scene while the bidrectional edges that connect every pair of nodes are encodings of the spatio-temporal relations. The bidirectional edges of the graph encode the temporal interactions between the agents that constitute the two nodes of the edge. The proposed method of obtaining his encoding is shown to be specifically suited for the problem at hand as it outperforms more complex end to end learning methods that do not use such intermediate representations of evolved spatio-temporal relations between agent pairs. We show significant performance gain in the form of behaviour classification accuracy on a variety of datasets from different parts of the globe over prior methods as well as show seamless transfer without any resort to fine-tuning across multiple datasets. Such behaviour prediction methods find immediate relevance in a variety of navigation tasks such as behaviour planning, state estimation as well as in applications relating to detection of traffic violations over videos.
Towards Accurate Vehicle Behaviour Classification With Multi-Relational Graph Convolutional Networks
Feb 03, 2020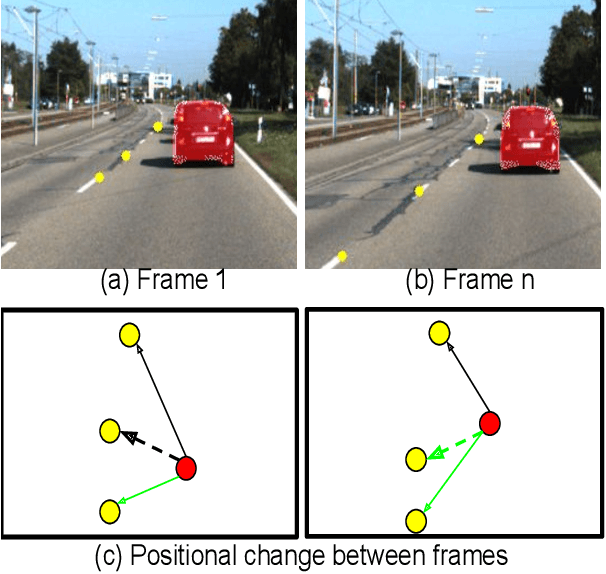
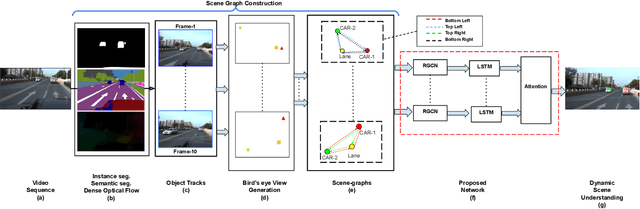


Understanding on-road vehicle behaviour from a temporal sequence of sensor data is gaining in popularity. In this paper, we propose a pipeline for understanding vehicle behaviour from a monocular image sequence or video. A monocular sequence along with scene semantics, optical flow and object labels are used to get spatial information about the object (vehicle) of interest and other objects (semantically contiguous set of locations) in the scene. This spatial information is encoded by a Multi-Relational Graph Convolutional Network (MR-GCN), and a temporal sequence of such encodings is fed to a recurrent network to label vehicle behaviours. The proposed framework can classify a variety of vehicle behaviours to high fidelity on datasets that are diverse and include European, Chinese and Indian on-road scenes. The framework also provides for seamless transfer of models across datasets without entailing re-annotation, retraining and even fine-tuning. We show comparative performance gain over baseline Spatio-temporal classifiers and detail a variety of ablations to showcase the efficacy of the framework.
Learning policies for Social network discovery with Reinforcement learning
Jul 08, 2019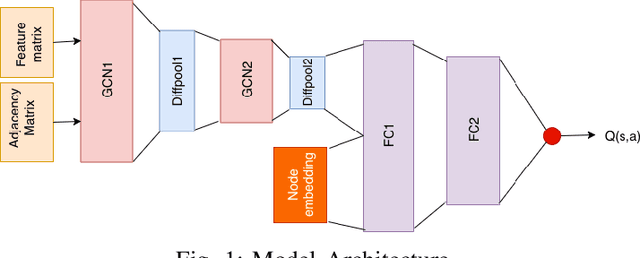

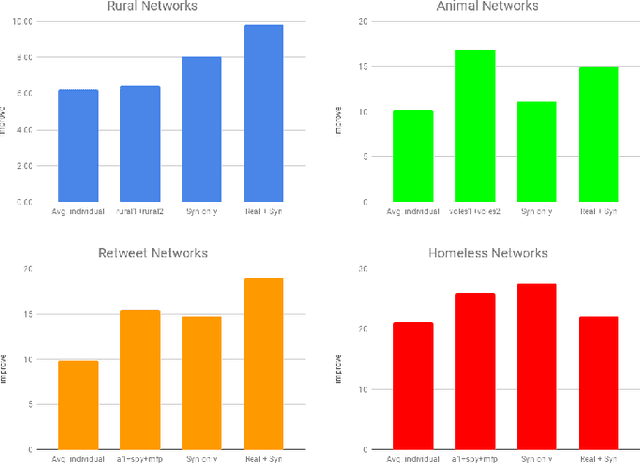
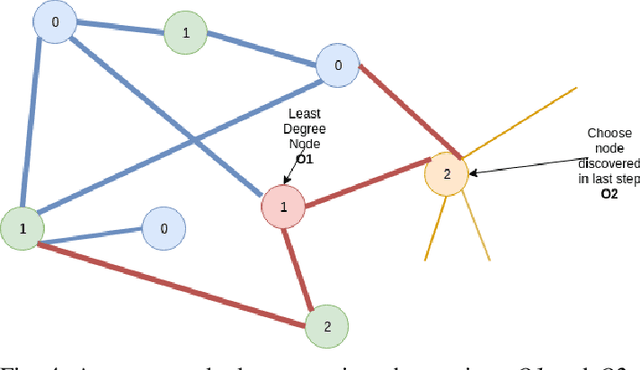
A serious challenge when finding influential actors in real-world social networks is the lack of knowledge about the structure of the underlying network. Current state-of-the-art methods rely on hand-crafted sampling algorithms; these methods sample nodes and their neighbours in a carefully constructed order and choose opinion leaders from this discovered network to maximize influence spread in the (unknown) complete network. In this work, we propose a reinforcement learning framework for network discovery that automatically learns useful node and graph representations that encode important structural properties of the network. At training time, the method identifies portions of the network such that the nodes selected from this sampled subgraph can effectively influence nodes in the complete network. The realization of such transferable network structure based adaptable policies is attributed to the meticulous design of the framework that encodes relevant node and graph signatures driven by an appropriate reward scheme. We experiment with real-world social networks from four different domains and show that the policies learned by our RL agent provide a 10-36% improvement over the current state-of-the-art method.
Network Representation Learning: Consolidation and Renewed Bearing
May 02, 2019
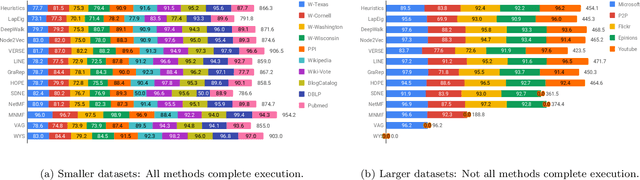
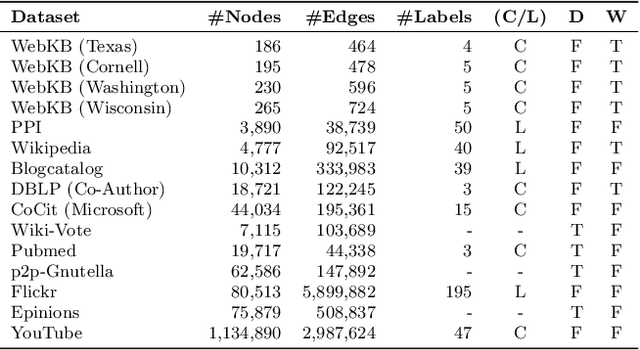
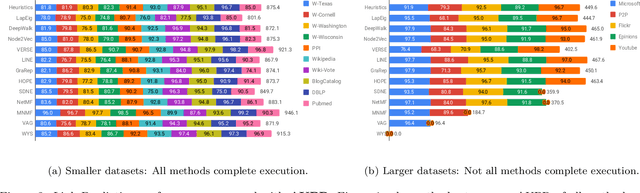
Graphs are a natural abstraction for many problems where nodes represent entities and edges represent a relationship across entities. An important area of research that has emerged over the last decade is the use of graphs as a vehicle for non-linear dimensionality reduction in a manner akin to previous efforts based on manifold learning with uses for downstream database processing, machine learning and visualization. In this systematic yet comprehensive experimental survey, we benchmark several popular network representation learning methods operating on two key tasks: link prediction and node classification. We examine the performance of 12 unsupervised embedding methods on 15 datasets. To the best of our knowledge, the scale of our study -- both in terms of the number of methods and number of datasets -- is the largest to date. Our results reveal several key insights about work-to-date in this space. First, we find that certain baseline methods (task-specific heuristics, as well as classic manifold methods) that have often been dismissed or are not considered by previous efforts can compete on certain types of datasets if they are tuned appropriately. Second, we find that recent methods based on matrix factorization offer a small but relatively consistent advantage over alternative methods (e.g., random-walk based methods) from a qualitative standpoint. Specifically, we find that MNMF, a community preserving embedding method, is the most competitive method for the link prediction task. While NetMF is the most competitive baseline for node classification. Third, no single method completely outperforms other embedding methods on both node classification and link prediction tasks. We also present several drill-down analysis that reveals settings under which certain algorithms perform well (e.g., the role of neighborhood context on performance) -- guiding the end-user.
HOPF: Higher Order Propagation Framework for Deep Collective Classification
Sep 21, 2018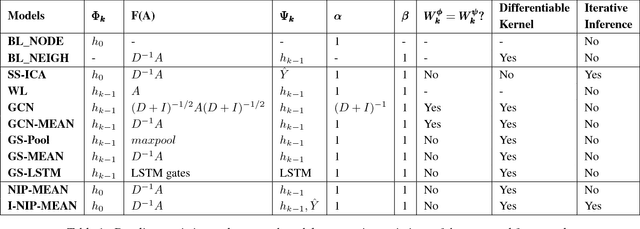
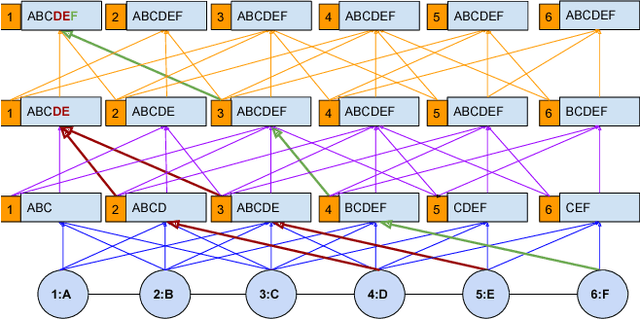
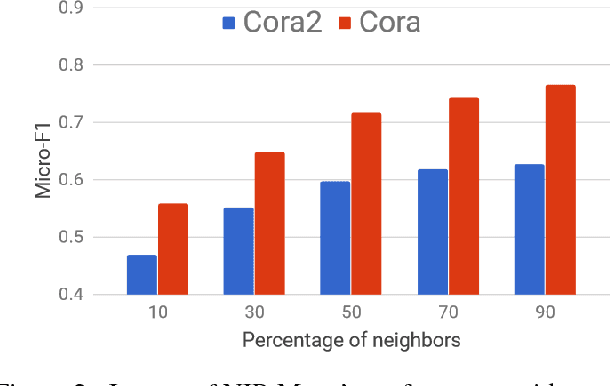
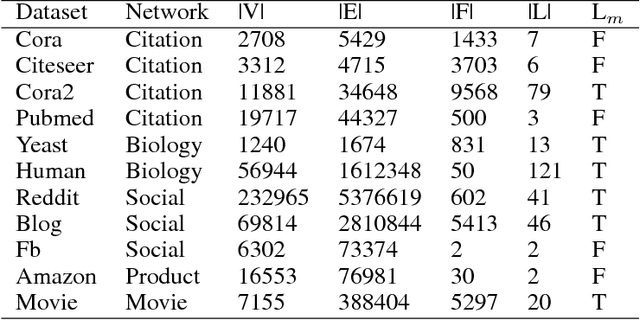
Given a graph where every node has certain attributes associated with it and some nodes have labels associated with them, Collective Classification (CC) is the task of assigning labels to every unlabeled node using information from the node as well as its neighbors. It is often the case that a node is not only influenced by its immediate neighbors but also by higher order neighbors, multiple hops away. Recent state-of-the-art models for CC learn end-to-end differentiable variations of Weisfeiler-Lehman (WL) kernels to aggregate multi-hop neighborhood information. In this work, we propose a Higher Order Propagation Framework, HOPF, which provides an iterative inference mechanism for these powerful differentiable kernels. Such a combination of classical iterative inference mechanism with recent differentiable kernels allows the framework to learn graph convolutional filters that simultaneously exploit the attribute and label information available in the neighborhood. Further, these iterative differentiable kernels can scale to larger hops beyond the memory limitations of existing differentiable kernels. We also show that existing WL kernel-based models suffer from the problem of Node Information Morphing where the information of the node is morphed or overwhelmed by the information of its neighbors when considering multiple hops. To address this, we propose a specific instantiation of HOPF, called the NIP models, which preserves the node information at every propagation step. The iterative formulation of NIP models further helps in incorporating distant hop information concisely as summaries of the inferred labels. We do an extensive evaluation across 11 datasets from different domains. We show that existing CC models do not provide consistent performance across datasets, while the proposed NIP model with iterative inference is more robust.
Fusion Graph Convolutional Networks
Sep 21, 2018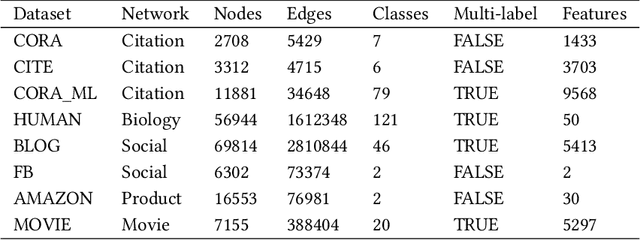
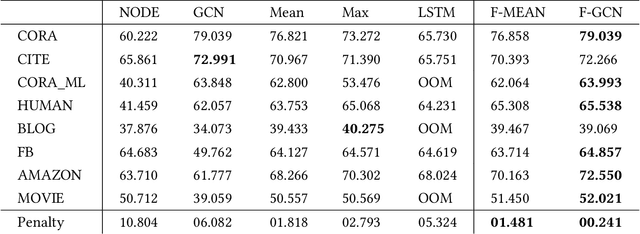
Semi-supervised node classification in attributed graphs, i.e., graphs with node features, involves learning to classify unlabeled nodes given a partially labeled graph. Label predictions are made by jointly modeling the node and its' neighborhood features. State-of-the-art models for node classification on such attributed graphs use differentiable recursive functions that enable aggregation and filtering of neighborhood information from multiple hops. In this work, we analyze the representation capacity of these models to regulate information from multiple hops independently. From our analysis, we conclude that these models despite being powerful, have limited representation capacity to capture multi-hop neighborhood information effectively. Further, we also propose a mathematically motivated, yet simple extension to existing graph convolutional networks (GCNs) which has improved representation capacity. We extensively evaluate the proposed model, F-GCN on eight popular datasets from different domains. F-GCN outperforms the state-of-the-art models for semi-supervised learning on six datasets while being extremely competitive on the other two.