 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate Vehicle Behaviour Classification With Multi-Relational Graph Convolutional Networks
Paper and Code
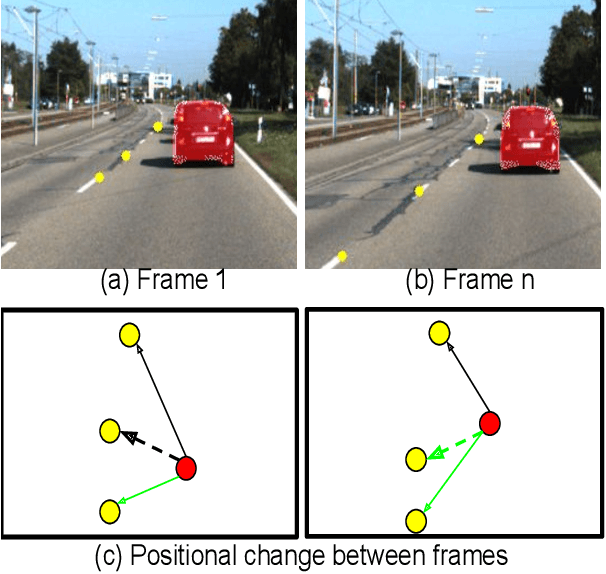
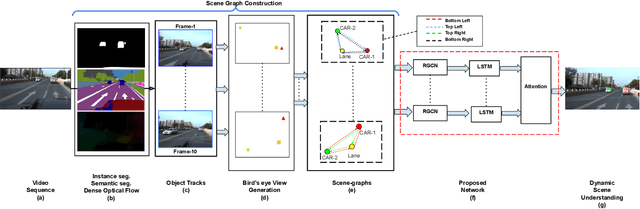


Understanding on-road vehicle behaviour from a temporal sequence of sensor data is gaining in popularity. In this paper, we propose a pipeline for understanding vehicle behaviour from a monocular image sequence or video. A monocular sequence along with scene semantics, optical flow and object labels are used to get spatial information about the object (vehicle) of interest and other objects (semantically contiguous set of locations) in the scene. This spatial information is encoded by a Multi-Relational Graph Convolutional Network (MR-GCN), and a temporal sequence of such encodings is fed to a recurrent network to label vehicle behaviours. The proposed framework can classify a variety of vehicle behaviours to high fidelity on datasets that are diverse and include European, Chinese and Indian on-road scenes. The framework also provides for seamless transfer of models across datasets without entailing re-annotation, retraining and even fine-tuning. We show comparative performance gain over baseline Spatio-temporal classifiers and detail a variety of ablations to showcase the efficacy of the framework.