 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Dynamic Scenes using Graph Convolution Networks
May 15, 2020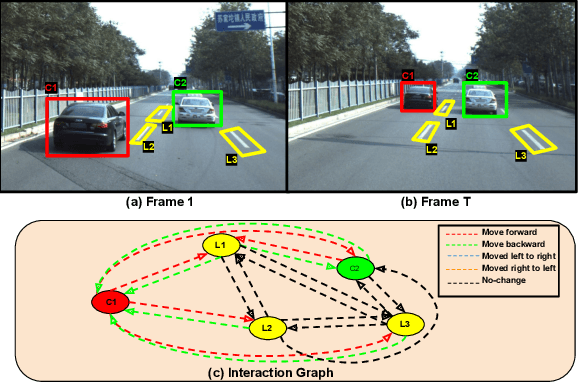
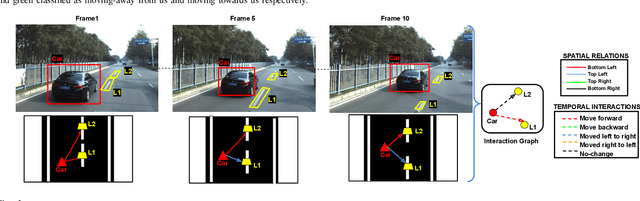
We present a novel Multi Relational Graph Convolutional Network (MRGCN) to model on-road vehicle behaviours from a sequence of temporally ordered frames as grabbed by a moving monocular camera. The input to MRGCN is a Multi Relational Graph (MRG) where the nodes of the graph represent the active and passive participants/agents in the scene while the bidrectional edges that connect every pair of nodes are encodings of the spatio-temporal relations. The bidirectional edges of the graph encode the temporal interactions between the agents that constitute the two nodes of the edge. The proposed method of obtaining his encoding is shown to be specifically suited for the problem at hand as it outperforms more complex end to end learning methods that do not use such intermediate representations of evolved spatio-temporal relations between agent pairs. We show significant performance gain in the form of behaviour classification accuracy on a variety of datasets from different parts of the globe over prior methods as well as show seamless transfer without any resort to fine-tuning across multiple datasets. Such behaviour prediction methods find immediate relevance in a variety of navigation tasks such as behaviour planning, state estimation as well as in applications relating to detection of traffic violations over videos.
Towards Accurate Vehicle Behaviour Classification With Multi-Relational Graph Convolutional Networks
Feb 03, 2020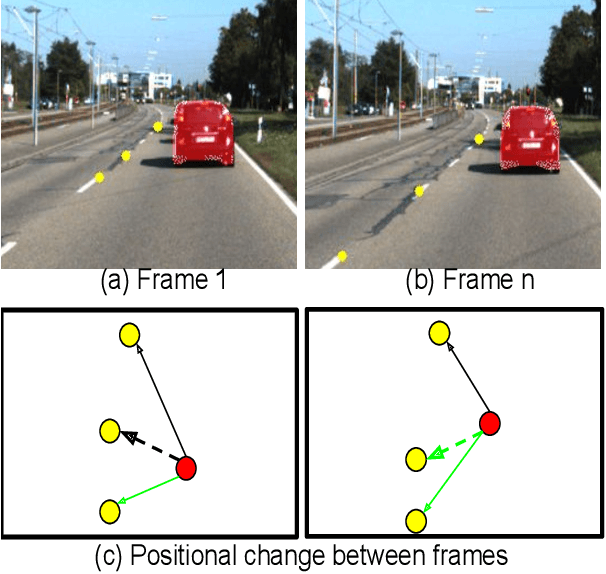
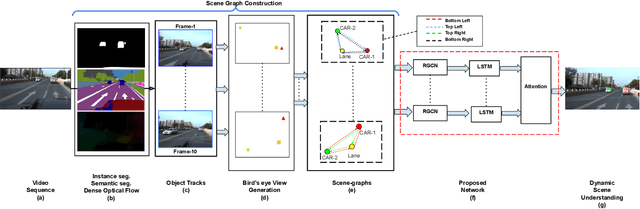


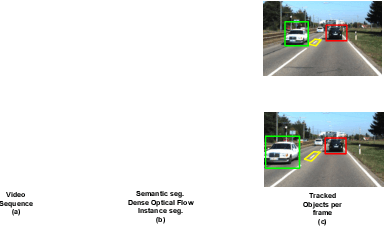
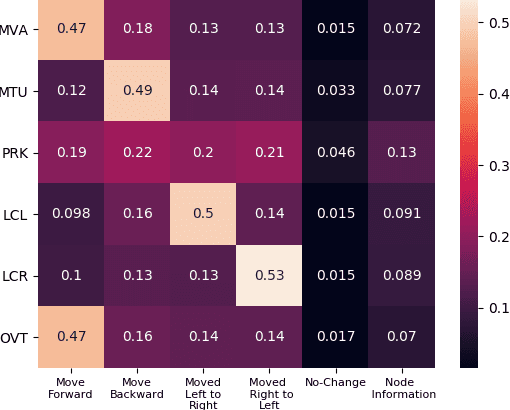
Understanding on-road vehicle behaviour from a temporal sequence of sensor data is gaining in popularity. In this paper, we propose a pipeline for understanding vehicle behaviour from a monocular image sequence or video. A monocular sequence along with scene semantics, optical flow and object labels are used to get spatial information about the object (vehicle) of interest and other objects (semantically contiguous set of locations) in the scene. This spatial information is encoded by a Multi-Relational Graph Convolutional Network (MR-GCN), and a temporal sequence of such encodings is fed to a recurrent network to label vehicle behaviours. The proposed framework can classify a variety of vehicle behaviours to high fidelity on datasets that are diverse and include European, Chinese and Indian on-road scenes. The framework also provides for seamless transfer of models across datasets without entailing re-annotation, retraining and even fine-tuning. We show comparative performance gain over baseline Spatio-temporal classifiers and detail a variety of ablations to showcase the efficacy of the framework.