 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAICD Bench: A Challenging Benchmark for AI-Generated Code Detection
Feb 02, 2026Large language models (LLMs) are increasingly capable of generating functional source code, raising concerns about authorship, accountability, and security. While detecting AI-generated code is critical, existing datasets and benchmarks are narrow, typically limited to binary human-machine classification under in-distribution settings. To bridge this gap, we introduce $\emph{AICD Bench}$, the most comprehensive benchmark for AI-generated code detection. It spans $\emph{2M examples}$, $\emph{77 models}$ across $\emph{11 families}$, and $\emph{9 programming languages}$, including recent reasoning models. Beyond scale, AICD Bench introduces three realistic detection tasks: ($\emph{i}$)~$\emph{Robust Binary Classification}$ under distribution shifts in language and domain, ($\emph{ii}$)~$\emph{Model Family Attribution}$, grouping generators by architectural lineage, and ($\emph{iii}$)~$\emph{Fine-Grained Human-Machine Classification}$ across human, machine, hybrid, and adversarial code. Extensive evaluation on neural and classical detectors shows that performance remains far below practical usability, particularly under distribution shift and for hybrid or adversarial code. We release AICD Bench as a $\emph{unified, challenging evaluation suite}$ to drive the next generation of robust approaches for AI-generated code detection. The data and the code are available at https://huggingface.co/AICD-bench}.
Aletheia: What Makes RLVR For Code Verifiers Tick?
Jan 17, 2026Multi-domain thinking verifiers trained via Reinforcement Learning from Verifiable Rewards (RLVR) are a prominent fixture of the Large Language Model (LLM) post-training pipeline, owing to their ability to robustly rate and rerank model outputs. However, the adoption of such verifiers towards code generation has been comparatively sparse, with execution feedback constituting the dominant signal. Nonetheless, code verifiers remain valuable toward judging model outputs in scenarios where execution feedback is hard to obtain and are a potentially powerful addition to the code generation post-training toolbox. To this end, we create and open-source Aletheia, a controlled testbed that enables execution-grounded evaluation of code verifiers' robustness across disparate policy models and covariate shifts. We examine components of the RLVR-based verifier training recipe widely credited for its success: (1) intermediate thinking traces, (2) learning from negative samples, and (3) on-policy training. While experiments show the optimality of RLVR, we uncover important opportunities to simplify the recipe. Particularly, despite code verification exhibiting positive training- and inference-time scaling, on-policy learning stands out as the key component at small verifier sizes, and thinking-based training emerges as the most important component at larger scales.
EMMA-500: Enhancing Massively Multilingual Adaptation of Large Language Models
Sep 26, 2024



In this work, we introduce EMMA-500, a large-scale multilingual language model continue-trained on texts across 546 languages designed for enhanced multilingual performance, focusing on improving language coverage for low-resource languages. To facilitate continual pre-training, we compile the MaLA corpus, a comprehensive multilingual dataset enriched with curated datasets across diverse domains. Leveraging this corpus, we conduct extensive continual pre-training of the Llama 2 7B model, resulting in EMMA-500, which demonstrates robust performance across a wide collection of benchmarks, including a comprehensive set of multilingual tasks and PolyWrite, an open-ended generation benchmark developed in this study. Our results highlight the effectiveness of continual pre-training in expanding large language models' language capacity, particularly for underrepresented languages, demonstrating significant gains in cross-lingual transfer, task generalization, and language adaptability.
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Jun 26, 2024



Automated software engineering has been greatly empowered by the recent advances in Large Language Models (LLMs) for programming. While current benchmarks have shown that LLMs can perform various software engineering tasks like human developers, the majority of their evaluations are limited to short and self-contained algorithmic tasks. Solving challenging and practical programming tasks requires the capability of utilizing diverse function calls as tools to efficiently implement functionalities like data analysis and web development. In addition, using multiple tools to solve a task needs compositional reasoning by accurately understanding complex instructions. Fulfilling both of these characteristics can pose a great challenge for LLMs. To assess how well LLMs can solve challenging and practical programming tasks, we introduce Bench, a benchmark that challenges LLMs to invoke multiple function calls as tools from 139 libraries and 7 domains for 1,140 fine-grained programming tasks. To evaluate LLMs rigorously, each programming task encompasses 5.6 test cases with an average branch coverage of 99%. In addition, we propose a natural-language-oriented variant of Bench, Benchi, that automatically transforms the original docstrings into short instructions only with essential information. Our extensive evaluation of 60 LLMs shows that LLMs are not yet capable of following complex instructions to use function calls precisely, with scores up to 60%, significantly lower than the human performance of 97%. The results underscore the need for further advancements in this area.
IRCoder: Intermediate Representations Make Language Models Robust Multilingual Code Generators
Mar 06, 2024Code understanding and generation have fast become some of the most popular applications of language models (LMs). Nonetheless, research on multilingual aspects of Code-LMs (i.e., LMs for code generation) such as cross-lingual transfer between different programming languages, language-specific data augmentation, and post-hoc LM adaptation, alongside exploitation of data sources other than the original textual content, has been much sparser than for their natural language counterparts. In particular, most mainstream Code-LMs have been pre-trained on source code files alone. In this work, we investigate the prospect of leveraging readily available compiler intermediate representations - shared across programming languages - to improve the multilingual capabilities of Code-LMs and facilitate cross-lingual transfer. To this end, we first compile SLTrans, a parallel dataset consisting of nearly 4M self-contained source code files coupled with respective intermediate representations. Next, starting from various base Code-LMs (ranging in size from 1.1B to 7.3B parameters), we carry out continued causal language modelling training on SLTrans, forcing the Code-LMs to (1) learn the IR language and (2) align the IR constructs with respective constructs of various programming languages. Our resulting models, dubbed IRCoder, display sizeable and consistent gains across a wide variety of code generation tasks and metrics, including prompt robustness, multilingual code completion, code understanding, and instruction following.
StarCoder 2 and The Stack v2: The Next Generation
Feb 29, 2024



The BigCode project, an open-scientific collaboration focused on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder2. In partnership with Software Heritage (SWH), we build The Stack v2 on top of the digital commons of their source code archive. Alongside the SWH repositories spanning 619 programming languages, we carefully select other high-quality data sources, such as GitHub pull requests, Kaggle notebooks, and code documentation. This results in a training set that is 4x larger than the first StarCoder dataset. We train StarCoder2 models with 3B, 7B, and 15B parameters on 3.3 to 4.3 trillion tokens and thoroughly evaluate them on a comprehensive set of Code LLM benchmarks. We find that our small model, StarCoder2-3B, outperforms other Code LLMs of similar size on most benchmarks, and also outperforms StarCoderBase-15B. Our large model, StarCoder2- 15B, significantly outperforms other models of comparable size. In addition, it matches or outperforms CodeLlama-34B, a model more than twice its size. Although DeepSeekCoder- 33B is the best-performing model at code completion for high-resource languages, we find that StarCoder2-15B outperforms it on math and code reasoning benchmarks, as well as several low-resource languages. We make the model weights available under an OpenRAIL license and ensure full transparency regarding the training data by releasing the SoftWare Heritage persistent IDentifiers (SWHIDs) of the source code data.
Adapters: A Unified Library for Parameter-Efficient and Modular Transfer Learning
Nov 18, 2023We introduce Adapters, an open-source library that unifies parameter-efficient and modular transfer learning in large language models. By integrating 10 diverse adapter methods into a unified interface, Adapters offers ease of use and flexible configuration. Our library allows researchers and practitioners to leverage adapter modularity through composition blocks, enabling the design of complex adapter setups. We demonstrate the library's efficacy by evaluating its performance against full fine-tuning on various NLP tasks. Adapters provides a powerful tool for addressing the challenges of conventional fine-tuning paradigms and promoting more efficient and modular transfer learning. The library is available via https://adapterhub.ml/adapters.
What sets Verified Users apart? Insights, Analysis and Prediction of Verified Users on Twitter
Mar 12, 2019

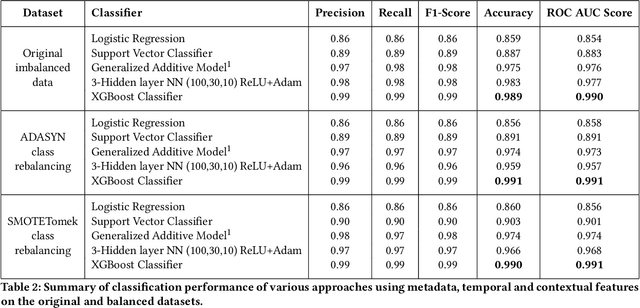
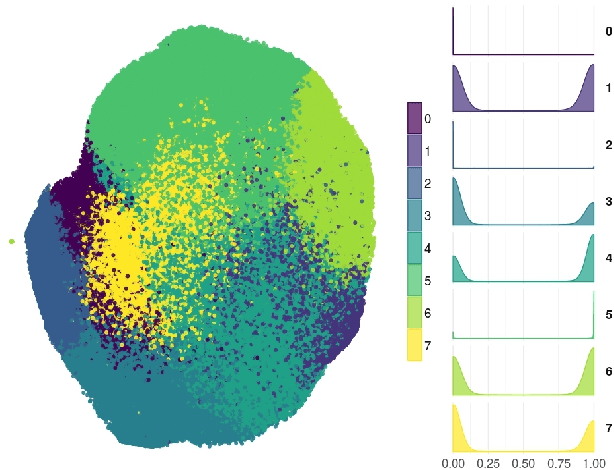
Social network and publishing platforms, such as Twitter, support the concept of a secret proprietary verification process, for handles they deem worthy of platform-wide public interest. In line with significant prior work which suggests that possessing such a status symbolizes enhanced credibility in the eyes of the platform audience, a verified badge is clearly coveted among public figures and brands. What are less obvious are the inner workings of the verification process and what being verified represents. This lack of clarity, coupled with the flak that Twitter received by extending aforementioned status to political extremists in 2017, backed Twitter into publicly admitting that the process and what the status represented needed to be rethought. With this in mind, we seek to unravel the aspects of a user's profile which likely engender or preclude verification. The aim of the paper is two-fold: First, we test if discerning the verification status of a handle from profile metadata and content features is feasible. Second, we unravel the features which have the greatest bearing on a handle's verification status. We collected a dataset consisting of profile metadata of all 231,235 verified English-speaking users (as of July 2018), a control sample of 175,930 non-verified English-speaking users and all their 494 million tweets over a one year collection period. Our proposed models are able to reliably identify verification status (Area under curve AUC > 99%). We show that number of public list memberships, presence of neutral sentiment in tweets and an authoritative language style are the most pertinent predictors of verification status. To the best of our knowledge, this work represents the first attempt at discerning and classifying verification worthy users on Twitter.