 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDALC: A Semi-Supervised Framework for Intent Detection and Active Learning based Correction
Nov 08, 2025



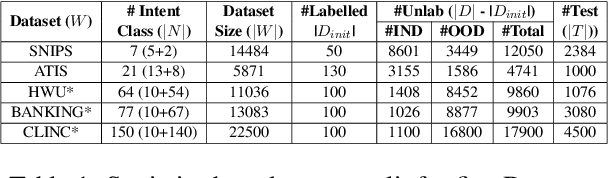
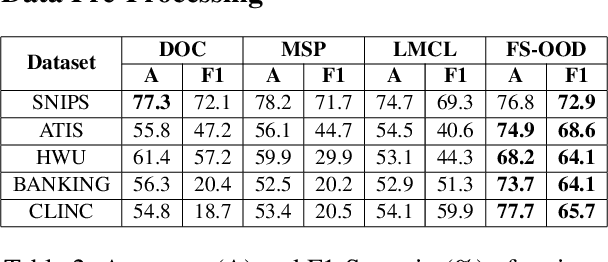
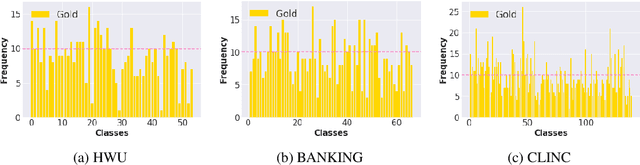
Voice-controlled dialog systems have become immensely popular due to their ability to perform a wide range of actions in response to diverse user queries. These agents possess a predefined set of skills or intents to fulfill specific user tasks. But every system has its own limitations. There are instances where, even for known intents, if any model exhibits low confidence, it results in rejection of utterances that necessitate manual annotation. Additionally, as time progresses, there may be a need to retrain these agents with new intents from the system-rejected queries to carry out additional tasks. Labeling all these emerging intents and rejected utterances over time is impractical, thus calling for an efficient mechanism to reduce annotation costs. In this paper, we introduce IDALC (Intent Detection and Active Learning based Correction), a semi-supervised framework designed to detect user intents and rectify system-rejected utterances while minimizing the need for human annotation. Empirical findings on various benchmark datasets demonstrate that our system surpasses baseline methods, achieving a 5-10% higher accuracy and a 4-8% improvement in macro-F1. Remarkably, we maintain the overall annotation cost at just 6-10% of the unlabelled data available to the system. The overall framework of IDALC is shown in Fig. 1
* Paper accepted in IEEE Transactions on Artificial Intelligence (October 2025)
Decision-Making with Deliberation: Meta-reviewing as a Document-grounded Dialogue
Aug 07, 2025Meta-reviewing is a pivotal stage in the peer-review process, serving as the final step in determining whether a paper is recommended for acceptance. Prior research on meta-reviewing has treated this as a summarization problem over review reports. However, complementary to this perspective, meta-reviewing is a decision-making process that requires weighing reviewer arguments and placing them within a broader context. Prior research has demonstrated that decision-makers can be effectively assisted in such scenarios via dialogue agents. In line with this framing, we explore the practical challenges for realizing dialog agents that can effectively assist meta-reviewers. Concretely, we first address the issue of data scarcity for training dialogue agents by generating synthetic data using Large Language Models (LLMs) based on a self-refinement strategy to improve the relevance of these dialogues to expert domains. Our experiments demonstrate that this method produces higher-quality synthetic data and can serve as a valuable resource towards training meta-reviewing assistants. Subsequently, we utilize this data to train dialogue agents tailored for meta-reviewing and find that these agents outperform \emph{off-the-shelf} LLM-based assistants for this task. Finally, we apply our agents in real-world meta-reviewing scenarios and confirm their effectiveness in enhancing the efficiency of meta-reviewing.\footnote{Code and Data: https://github.com/UKPLab/arxiv2025-meta-review-as-dialog
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025



Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
LazyReview A Dataset for Uncovering Lazy Thinking in NLP Peer Reviews
Apr 15, 2025Peer review is a cornerstone of quality control in scientific publishing. With the increasing workload, the unintended use of `quick' heuristics, referred to as lazy thinking, has emerged as a recurring issue compromising review quality. Automated methods to detect such heuristics can help improve the peer-reviewing process. However, there is limited NLP research on this issue, and no real-world dataset exists to support the development of detection tools. This work introduces LazyReview, a dataset of peer-review sentences annotated with fine-grained lazy thinking categories. Our analysis reveals that Large Language Models (LLMs) struggle to detect these instances in a zero-shot setting. However, instruction-based fine-tuning on our dataset significantly boosts performance by 10-20 performance points, highlighting the importance of high-quality training data. Furthermore, a controlled experiment demonstrates that reviews revised with lazy thinking feedback are more comprehensive and actionable than those written without such feedback. We will release our dataset and the enhanced guidelines that can be used to train junior reviewers in the community. (Code available here: https://github.com/UKPLab/arxiv2025-lazy-review)
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
Adapters: A Unified Library for Parameter-Efficient and Modular Transfer Learning
Nov 18, 2023We introduce Adapters, an open-source library that unifies parameter-efficient and modular transfer learning in large language models. By integrating 10 diverse adapter methods into a unified interface, Adapters offers ease of use and flexible configuration. Our library allows researchers and practitioners to leverage adapter modularity through composition blocks, enabling the design of complex adapter setups. We demonstrate the library's efficacy by evaluating its performance against full fine-tuning on various NLP tasks. Adapters provides a powerful tool for addressing the challenges of conventional fine-tuning paradigms and promoting more efficient and modular transfer learning. The library is available via https://adapterhub.ml/adapters.
Exploring Jiu-Jitsu Argumentation for Writing Peer Review Rebuttals
Nov 07, 2023



In many domains of argumentation, people's arguments are driven by so-called attitude roots, i.e., underlying beliefs and world views, and their corresponding attitude themes. Given the strength of these latent drivers of arguments, recent work in psychology suggests that instead of directly countering surface-level reasoning (e.g., falsifying given premises), one should follow an argumentation style inspired by the Jiu-Jitsu 'soft' combat system (Hornsey and Fielding, 2017): first, identify an arguer's attitude roots and themes, and then choose a prototypical rebuttal that is aligned with those drivers instead of invalidating those. In this work, we are the first to explore Jiu-Jitsu argumentation for peer review by proposing the novel task of attitude and theme-guided rebuttal generation. To this end, we enrich an existing dataset for discourse structure in peer reviews with attitude roots, attitude themes, and canonical rebuttals. To facilitate this process, we recast established annotation concepts from the domain of peer reviews (e.g., aspects a review sentence is relating to) and train domain-specific models. We then propose strong rebuttal generation strategies, which we benchmark on our novel dataset for the task of end-to-end attitude and theme-guided rebuttal generation and two subtasks.
Romanization-based Large-scale Adaptation of Multilingual Language Models
Apr 18, 2023



Large multilingual pretrained language models (mPLMs) have become the de facto state of the art for cross-lingual transfer in NLP. However, their large-scale deployment to many languages, besides pretraining data scarcity, is also hindered by the increase in vocabulary size and limitations in their parameter budget. In order to boost the capacity of mPLMs to deal with low-resource and unseen languages, we explore the potential of leveraging transliteration on a massive scale. In particular, we explore the UROMAN transliteration tool, which provides mappings from UTF-8 to Latin characters for all the writing systems, enabling inexpensive romanization for virtually any language. We first focus on establishing how UROMAN compares against other language-specific and manually curated transliterators for adapting multilingual PLMs. We then study and compare a plethora of data- and parameter-efficient strategies for adapting the mPLMs to romanized and non-romanized corpora of 14 diverse low-resource languages. Our results reveal that UROMAN-based transliteration can offer strong performance for many languages, with particular gains achieved in the most challenging setups: on languages with unseen scripts and with limited training data without any vocabulary augmentation. Further analyses reveal that an improved tokenizer based on romanized data can even outperform non-transliteration-based methods in the majority of languages.
A Framework to Generate High-Quality Datapoints for Multiple Novel Intent Detection
May 04, 2022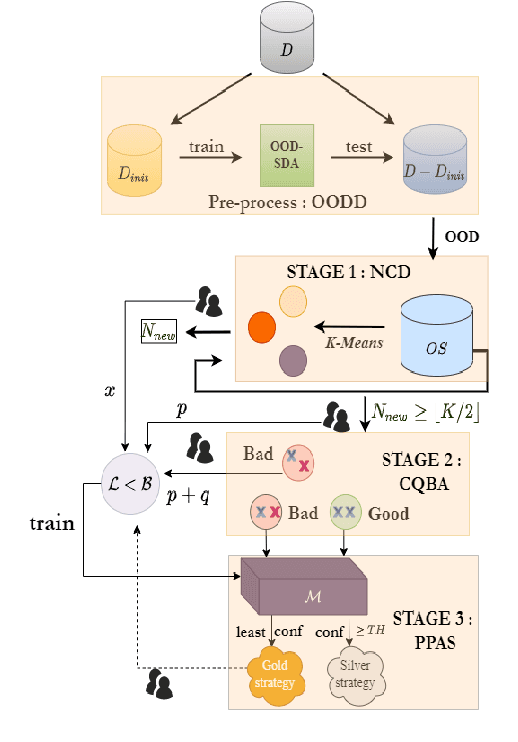
Systems like Voice-command based conversational agents are characterized by a pre-defined set of skills or intents to perform user specified tasks. In the course of time, newer intents may emerge requiring retraining. However, the newer intents may not be explicitly announced and need to be inferred dynamically. Thus, there are two important tasks at hand (a). identifying emerging new intents, (b). annotating data of the new intents so that the underlying classifier can be retrained efficiently. The tasks become specially challenging when a large number of new intents emerge simultaneously and there is a limited budget of manual annotation. In this paper, we propose MNID (Multiple Novel Intent Detection) which is a cluster based framework to detect multiple novel intents with budgeted human annotation cost. Empirical results on various benchmark datasets (of different sizes) demonstrate that MNID, by intelligently using the budget for annotation, outperforms the baseline methods in terms of accuracy and F1-score.
Knowledge Graph Question Answering via SPARQL Silhouette Generation
Sep 06, 2021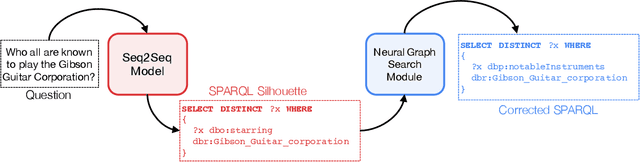
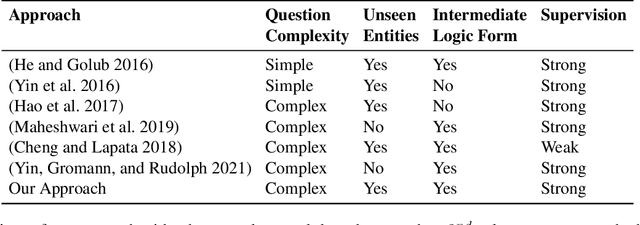
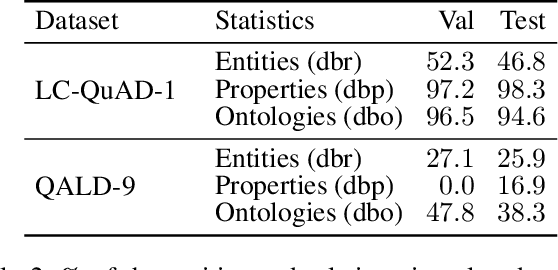
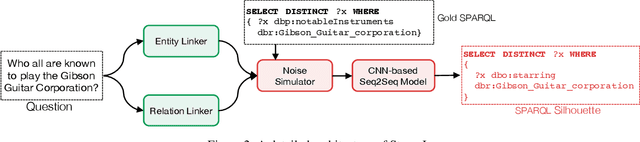
Knowledge Graph Question Answering (KGQA) has become a prominent area in natural language processing due to the emergence of large-scale Knowledge Graphs (KGs). Recently Neural Machine Translation based approaches are gaining momentum that translates natural language queries to structured query languages thereby solving the KGQA task. However, most of these methods struggle with out-of-vocabulary words where test entities and relations are not seen during training time. In this work, we propose a modular two-stage neural architecture to solve the KGQA task. The first stage generates a sketch of the target SPARQL called SPARQL silhouette for the input question. This comprises of (1) Noise simulator to facilitate out-of-vocabulary words and to reduce vocabulary size (2) seq2seq model for text to SPARQL silhouette generation. The second stage is a Neural Graph Search Module. SPARQL silhouette generated in the first stage is distilled in the second stage by substituting precise relation in the predicted structure. We simulate ideal and realistic scenarios by designing a noise simulator. Experimental results show that the quality of generated SPARQL silhouette in the first stage is outstanding for the ideal scenarios but for realistic scenarios (i.e. noisy linker), the quality of the resulting SPARQL silhouette drops drastically. However, our neural graph search module recovers it considerably. We show that our method can achieve reasonable performance improving the state-of-art by a margin of 3.72% F1 for the LC-QuAD-1 dataset. We believe, our proposed approach is novel and will lead to dynamic KGQA solutions that are suited for practical applications.