 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Variant of Gradient Descent Algorithm Based on Gradient Averaging
Paper and Code
Dec 10, 2020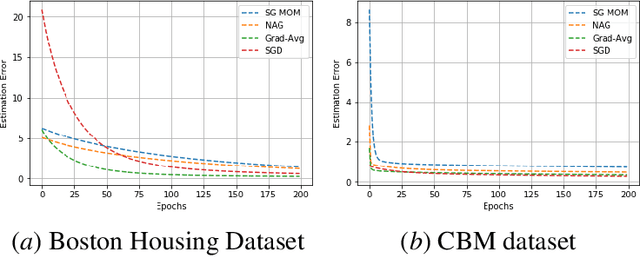

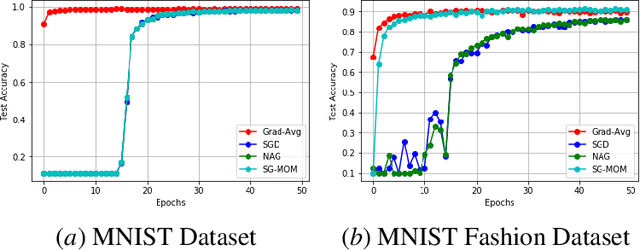

In this work, we study an optimizer, Grad-Avg to optimize error functions. We establish the convergence of the sequence of iterates of Grad-Avg mathematically to a minimizer (under boundedness assumption). We apply Grad-Avg along with some of the popular optimizers on regression as well as classification tasks. In regression tasks, it is observed that the behaviour of Grad-Avg is almost identical with Stochastic Gradient Descent (SGD). We present a mathematical justification of this fact. In case of classification tasks, it is observed that the performance of Grad-Avg can be enhanced by suitably scaling the parameters. Experimental results demonstrate that Grad-Avg converges faster than the other state-of-the-art optimizers for the classification task on two benchmark datasets.