 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approach to Build Zero-Shot Slot-Filling System for Industry-Grade Conversational Assistants
Jun 13, 2024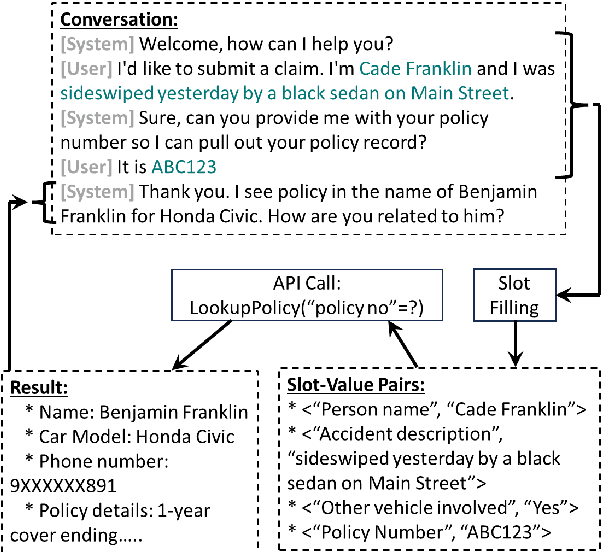
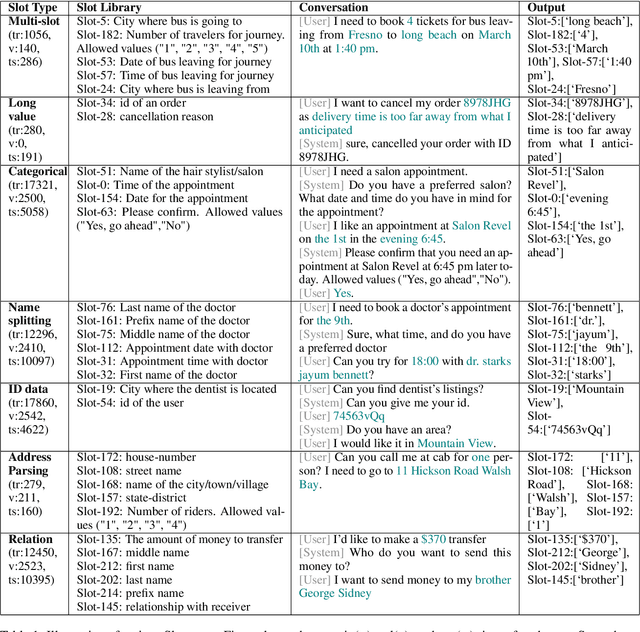
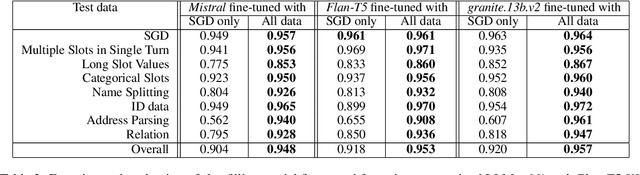

We present an approach to build Large Language Model (LLM) based slot-filling system to perform Dialogue State Tracking in conversational assistants serving across a wide variety of industry-grade applications. Key requirements of this system include: 1) usage of smaller-sized models to meet low latency requirements and to enable convenient and cost-effective cloud and customer premise deployments, and 2) zero-shot capabilities to serve across a wide variety of domains, slot types and conversational scenarios. We adopt a fine-tuning approach where a pre-trained LLM is fine-tuned into a slot-filling model using task specific data. The fine-tuning data is prepared carefully to cover a wide variety of slot-filling task scenarios that the model is expected to face across various domains. We give details of the data preparation and model building process. We also give a detailed analysis of the results of our experimental evaluations. Results show that our prescribed approach for slot-filling model building has resulted in 6.9% relative improvement of F1 metric over the best baseline on a realistic benchmark, while at the same time reducing the latency by 57%. More over, the data we prepared has helped improve F1 on an average by 4.2% relative across various slot-types.
A Benchmark for Generalizable and Interpretable Temporal Question Answering over Knowledge Bases
Jan 15, 2022
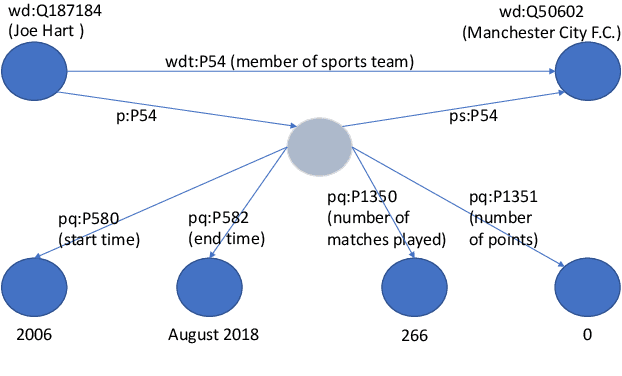


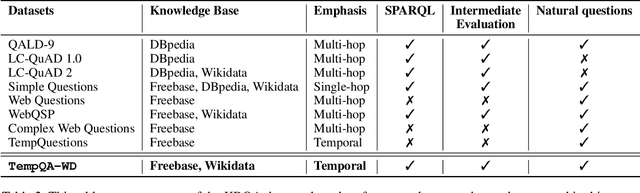
Knowledge Base Question Answering (KBQA) tasks that involve complex reasoning are emerging as an important research direction. However, most existing KBQA datasets focus primarily on generic multi-hop reasoning over explicit facts, largely ignoring other reasoning types such as temporal, spatial, and taxonomic reasoning. In this paper, we present a benchmark dataset for temporal reasoning, TempQA-WD, to encourage research in extending the present approaches to target a more challenging set of complex reasoning tasks. Specifically, our benchmark is a temporal question answering dataset with the following advantages: (a) it is based on Wikidata, which is the most frequently curated, openly available knowledge base, (b) it includes intermediate sparql queries to facilitate the evaluation of semantic parsing based approaches for KBQA, and (c) it generalizes to multiple knowledge bases: Freebase and Wikidata. The TempQA-WD dataset is available at https://github.com/IBM/tempqa-wd.
SYGMA: System for Generalizable Modular Question Answering OverKnowledge Bases
Sep 28, 2021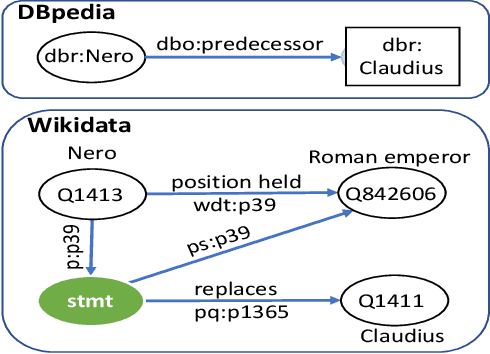


Knowledge Base Question Answering (KBQA) tasks that in-volve complex reasoning are emerging as an important re-search direction. However, most KBQA systems struggle withgeneralizability, particularly on two dimensions: (a) acrossmultiple reasoning types where both datasets and systems haveprimarily focused on multi-hop reasoning, and (b) across mul-tiple knowledge bases, where KBQA approaches are specif-ically tuned to a single knowledge base. In this paper, wepresent SYGMA, a modular approach facilitating general-izability across multiple knowledge bases and multiple rea-soning types. Specifically, SYGMA contains three high levelmodules: 1) KB-agnostic question understanding module thatis common across KBs 2) Rules to support additional reason-ing types and 3) KB-specific question mapping and answeringmodule to address the KB-specific aspects of the answer ex-traction. We demonstrate effectiveness of our system by evalu-ating on datasets belonging to two distinct knowledge bases,DBpedia and Wikidata. In addition, to demonstrate extensi-bility to additional reasoning types we evaluate on multi-hopreasoning datasets and a new Temporal KBQA benchmarkdataset on Wikidata, namedTempQA-WD1, introduced in thispaper. We show that our generalizable approach has bettercompetetive performance on multiple datasets on DBpediaand Wikidata that requires both multi-hop and temporal rea-soning
Knowledge Graph Question Answering via SPARQL Silhouette Generation
Sep 06, 2021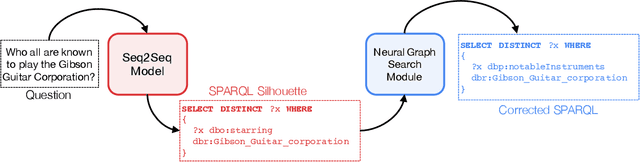
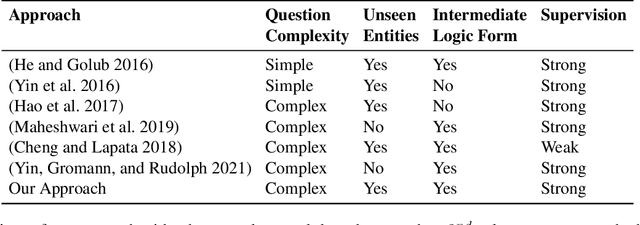
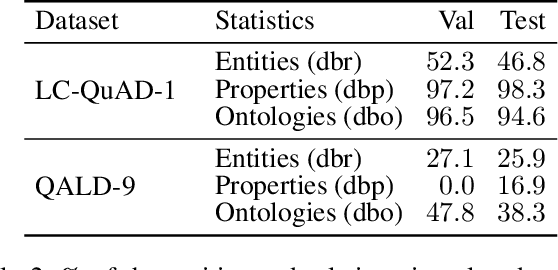
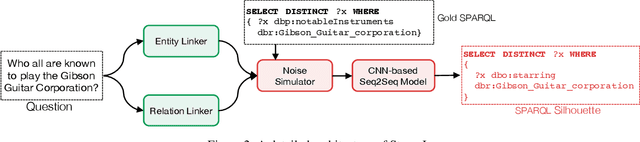
Knowledge Graph Question Answering (KGQA) has become a prominent area in natural language processing due to the emergence of large-scale Knowledge Graphs (KGs). Recently Neural Machine Translation based approaches are gaining momentum that translates natural language queries to structured query languages thereby solving the KGQA task. However, most of these methods struggle with out-of-vocabulary words where test entities and relations are not seen during training time. In this work, we propose a modular two-stage neural architecture to solve the KGQA task. The first stage generates a sketch of the target SPARQL called SPARQL silhouette for the input question. This comprises of (1) Noise simulator to facilitate out-of-vocabulary words and to reduce vocabulary size (2) seq2seq model for text to SPARQL silhouette generation. The second stage is a Neural Graph Search Module. SPARQL silhouette generated in the first stage is distilled in the second stage by substituting precise relation in the predicted structure. We simulate ideal and realistic scenarios by designing a noise simulator. Experimental results show that the quality of generated SPARQL silhouette in the first stage is outstanding for the ideal scenarios but for realistic scenarios (i.e. noisy linker), the quality of the resulting SPARQL silhouette drops drastically. However, our neural graph search module recovers it considerably. We show that our method can achieve reasonable performance improving the state-of-art by a margin of 3.72% F1 for the LC-QuAD-1 dataset. We believe, our proposed approach is novel and will lead to dynamic KGQA solutions that are suited for practical applications.
Question Answering over Knowledge Bases by Leveraging Semantic Parsing and Neuro-Symbolic Reasoning
Dec 03, 2020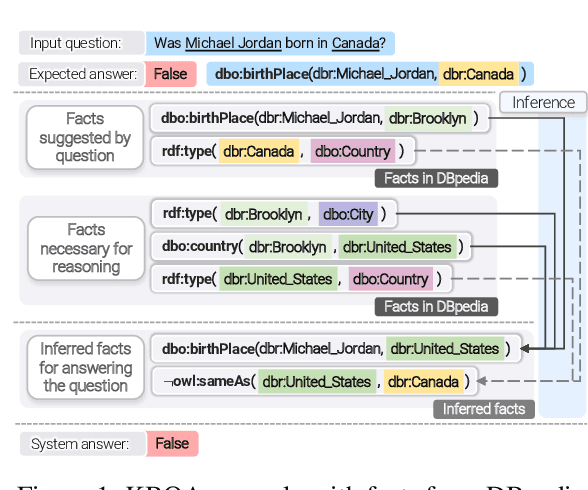
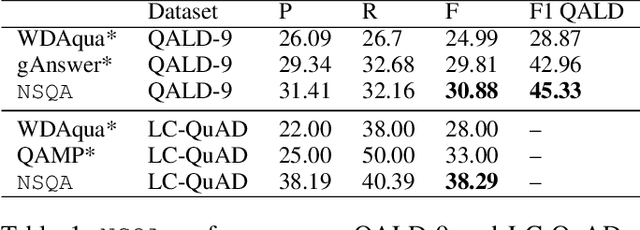
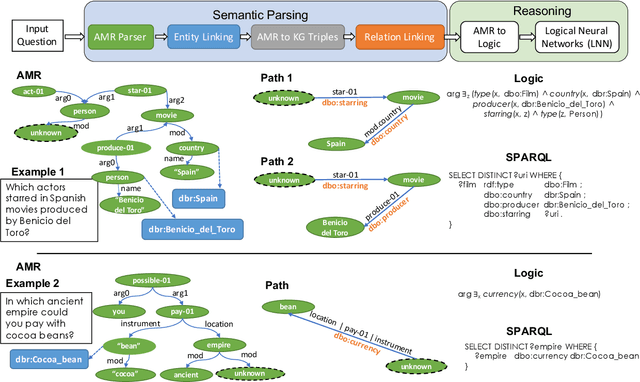

Knowledge base question answering (KBQA) is an important task in Natural Language Processing. Existing approaches face significant challenges including complex question understanding, necessity for reasoning, and lack of large training datasets. In this work, we propose a semantic parsing and reasoning-based Neuro-Symbolic Question Answering(NSQA) system, that leverages (1) Abstract Meaning Representation (AMR) parses for task-independent question under-standing; (2) a novel path-based approach to transform AMR parses into candidate logical queries that are aligned to the KB; (3) a neuro-symbolic reasoner called Logical Neural Net-work (LNN) that executes logical queries and reasons over KB facts to provide an answer; (4) system of systems approach,which integrates multiple, reusable modules that are trained specifically for their individual tasks (e.g. semantic parsing,entity linking, and relationship linking) and do not require end-to-end training data. NSQA achieves state-of-the-art performance on QALD-9 and LC-QuAD 1.0. NSQA's novelty lies in its modular neuro-symbolic architecture and its task-general approach to interpreting natural language questions.
Span Selection Pre-training for Question Answering
Sep 09, 2019
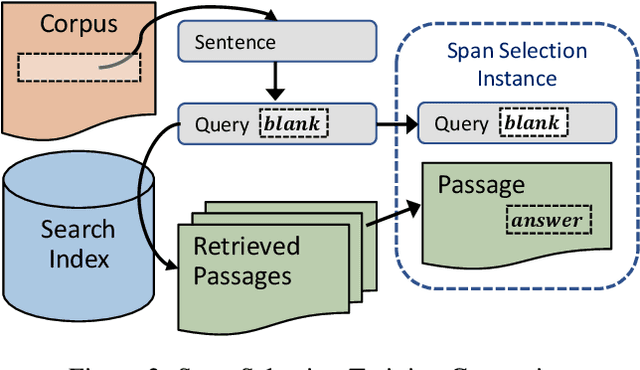

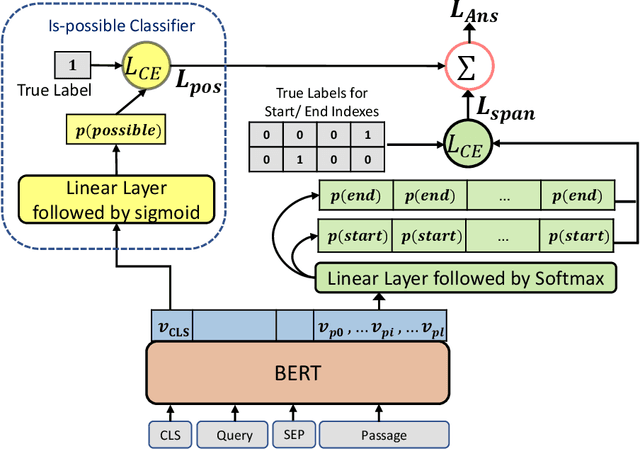
BERT (Bidirectional Encoder Representations from Transformers) and related pre-trained Transformers have provided large gains across many language understanding tasks, achieving a new state-of-the-art (SOTA). BERT is pre-trained on two auxiliary tasks: Masked Language Model and Next Sentence Prediction. In this paper we introduce a new pre-training task inspired by reading comprehension and an effort to avoid encoding general knowledge in the transformer network itself. We find significant and consistent improvements over both BERT-BASE and BERT-LARGE on multiple reading comprehension (MRC) and paraphrasing datasets. Specifically, our proposed model has strong empirical evidence as it obtains SOTA results on Natural Questions, a new benchmark MRC dataset, outperforming BERT-LARGE by 3 F1 points on short answer prediction. We also establish a new SOTA in HotpotQA, improving answer prediction F1 by 4 F1 points and supporting fact prediction by 1 F1 point. Moreover, we show that our pre-training approach is particularly effective when training data is limited, improving the learning curve by a large amount.