 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
An Expanded Massive Multilingual Dataset for High-Performance Language Technologies
Mar 13, 2025


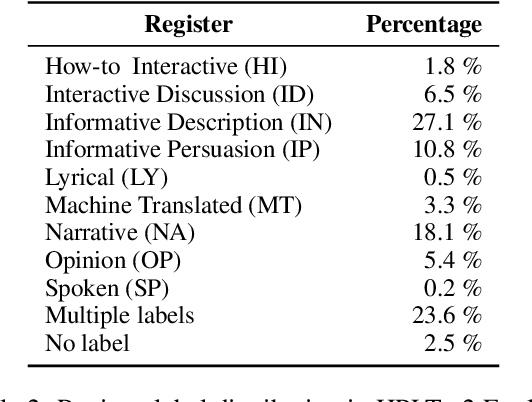
Training state-of-the-art large language models requires vast amounts of clean and diverse textual data. However, building suitable multilingual datasets remains a challenge. In this work, we present HPLT v2, a collection of high-quality multilingual monolingual and parallel corpora. The monolingual portion of the data contains 8T tokens covering 193 languages, while the parallel data contains 380M sentence pairs covering 51 languages. We document the entire data pipeline and release the code to reproduce it. We provide extensive analysis of the quality and characteristics of our data. Finally, we evaluate the performance of language models and machine translation systems trained on HPLT v2, demonstrating its value.
Context and System Fusion in Post-ASR Emotion Recognition with Large Language Models
Oct 04, 2024



Large language models (LLMs) have started to play a vital role in modelling speech and text. To explore the best use of context and multiple systems' outputs for post-ASR speech emotion prediction, we study LLM prompting on a recent task named GenSEC. Our techniques include ASR transcript ranking, variable conversation context, and system output fusion. We show that the conversation context has diminishing returns and the metric used to select the transcript for prediction is crucial. Finally, our best submission surpasses the provided baseline by 20% in absolute accuracy.
Quality or Quantity? On Data Scale and Diversity in Adapting Large Language Models for Low-Resource Translation
Aug 23, 2024


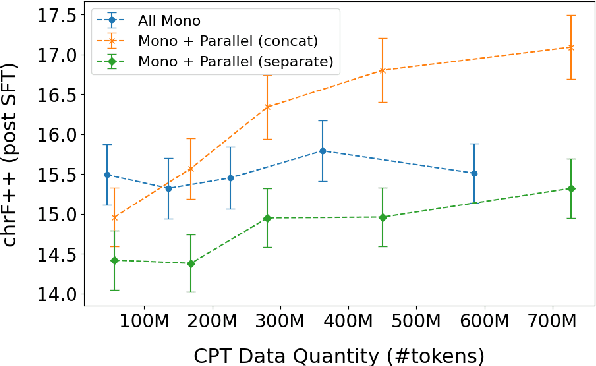
Despite the recent popularity of Large Language Models (LLMs) in Machine Translation (MT), their performance in low-resource translation still lags significantly behind Neural Machine Translation (NMT) models. In this paper, we explore what it would take to adapt LLMs for low-resource settings. In particular, we re-examine the role of two factors: a) the importance and application of parallel data, and b) diversity in Supervised Fine-Tuning (SFT). Recently, parallel data has been shown to be less important for MT using LLMs than in previous MT research. Similarly, diversity during SFT has been shown to promote significant transfer in LLMs across languages and tasks. However, for low-resource LLM-MT, we show that the opposite is true for both of these considerations: a) parallel data is critical during both pretraining and SFT, and b) diversity tends to cause interference, not transfer. Our experiments, conducted with 3 LLMs across 2 low-resourced language groups - indigenous American and North-East Indian - reveal consistent patterns in both cases, underscoring the generalizability of our findings. We believe these insights will be valuable for scaling to massively multilingual LLM-MT models that can effectively serve lower-resource languages.