 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality or Quantity? On Data Scale and Diversity in Adapting Large Language Models for Low-Resource Translation
Paper and Code
Aug 23, 2024


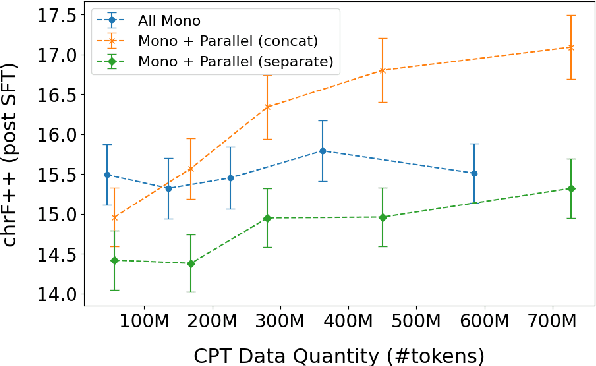
Despite the recent popularity of Large Language Models (LLMs) in Machine Translation (MT), their performance in low-resource translation still lags significantly behind Neural Machine Translation (NMT) models. In this paper, we explore what it would take to adapt LLMs for low-resource settings. In particular, we re-examine the role of two factors: a) the importance and application of parallel data, and b) diversity in Supervised Fine-Tuning (SFT). Recently, parallel data has been shown to be less important for MT using LLMs than in previous MT research. Similarly, diversity during SFT has been shown to promote significant transfer in LLMs across languages and tasks. However, for low-resource LLM-MT, we show that the opposite is true for both of these considerations: a) parallel data is critical during both pretraining and SFT, and b) diversity tends to cause interference, not transfer. Our experiments, conducted with 3 LLMs across 2 low-resourced language groups - indigenous American and North-East Indian - reveal consistent patterns in both cases, underscoring the generalizability of our findings. We believe these insights will be valuable for scaling to massively multilingual LLM-MT models that can effectively serve lower-resource languages.