 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality or Quantity? On Data Scale and Diversity in Adapting Large Language Models for Low-Resource Translation
Aug 23, 2024


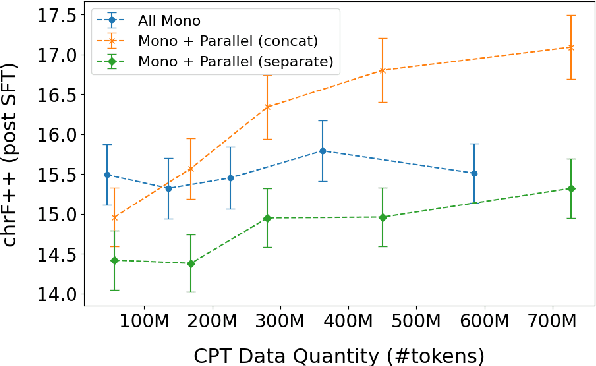
Despite the recent popularity of Large Language Models (LLMs) in Machine Translation (MT), their performance in low-resource translation still lags significantly behind Neural Machine Translation (NMT) models. In this paper, we explore what it would take to adapt LLMs for low-resource settings. In particular, we re-examine the role of two factors: a) the importance and application of parallel data, and b) diversity in Supervised Fine-Tuning (SFT). Recently, parallel data has been shown to be less important for MT using LLMs than in previous MT research. Similarly, diversity during SFT has been shown to promote significant transfer in LLMs across languages and tasks. However, for low-resource LLM-MT, we show that the opposite is true for both of these considerations: a) parallel data is critical during both pretraining and SFT, and b) diversity tends to cause interference, not transfer. Our experiments, conducted with 3 LLMs across 2 low-resourced language groups - indigenous American and North-East Indian - reveal consistent patterns in both cases, underscoring the generalizability of our findings. We believe these insights will be valuable for scaling to massively multilingual LLM-MT models that can effectively serve lower-resource languages.
UDApter -- Efficient Domain Adaptation Using Adapters
Feb 16, 2023We propose two methods to make unsupervised domain adaptation (UDA) more parameter efficient using adapters, small bottleneck layers interspersed with every layer of the large-scale pre-trained language model (PLM). The first method deconstructs UDA into a two-step process: first by adding a domain adapter to learn domain-invariant information and then by adding a task adapter that uses domain-invariant information to learn task representations in the source domain. The second method jointly learns a supervised classifier while reducing the divergence measure. Compared to strong baselines, our simple methods perform well in natural language inference (MNLI) and the cross-domain sentiment classification task. We even outperform unsupervised domain adaptation methods such as DANN and DSN in sentiment classification, and we are within 0.85% F1 for natural language inference task, by fine-tuning only a fraction of the full model parameters. We release our code at https://github.com/declare-lab/domadapter
Datasets: A Community Library for Natural Language Processing
Sep 07, 2021
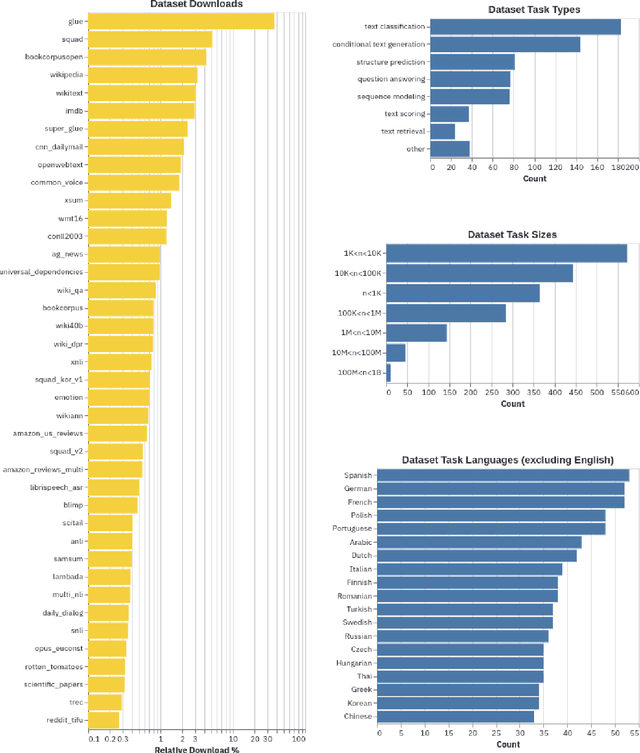
The scale, variety, and quantity of publicly-available NLP datasets has grown rapidly as researchers propose new tasks, larger models, and novel benchmarks. Datasets is a community library for contemporary NLP designed to support this ecosystem. Datasets aims to standardize end-user interfaces, versioning, and documentation, while providing a lightweight front-end that behaves similarly for small datasets as for internet-scale corpora. The design of the library incorporates a distributed, community-driven approach to adding datasets and documenting usage. After a year of development, the library now includes more than 650 unique datasets, has more than 250 contributors, and has helped support a variety of novel cross-dataset research projects and shared tasks. The library is available at https://github.com/huggingface/datasets.