 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning of Structured Data for Medical Foundation Models
Oct 17, 2024

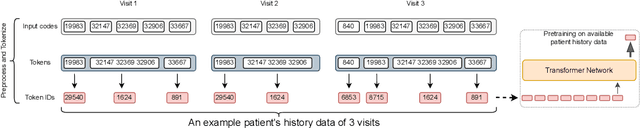
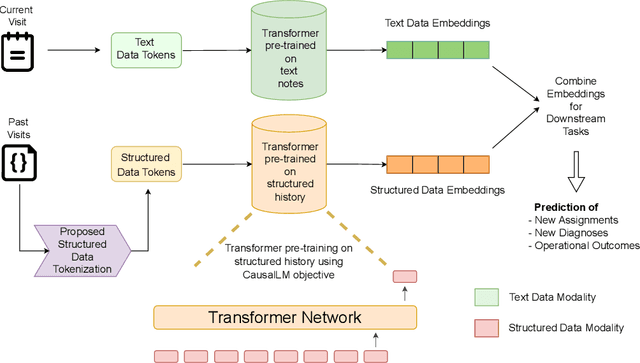
Large Language Models (LLMs) have demonstrated remarkable performance across various domains, including healthcare. However, their ability to effectively represent structured non-textual data, such as the alphanumeric medical codes used in records like ICD-10 or SNOMED-CT, is limited and has been particularly exposed in recent research. This paper examines the challenges LLMs face in processing medical codes due to the shortcomings of current tokenization methods. As a result, we introduce the UniStruct architecture to design a multimodal medical foundation model of unstructured text and structured data, which addresses these challenges by adapting subword tokenization techniques specifically for the structured medical codes. Our approach is validated through model pre-training on both an extensive internal medical database and a public repository of structured medical records. Trained on over 1 billion tokens on the internal medical database, the proposed model achieves up to a 23% improvement in evaluation metrics, with around 2% gain attributed to our proposed tokenization. Additionally, when evaluated on the EHRSHOT public benchmark with a 1/1000 fraction of the pre-training data, the UniStruct model improves performance on over 42% of the downstream tasks. Our approach not only enhances the representation and generalization capabilities of patient-centric models but also bridges a critical gap in representation learning models' ability to handle complex structured medical data, alongside unstructured text.
MEDSAGE: Enhancing Robustness of Medical Dialogue Summarization to ASR Errors with LLM-generated Synthetic Dialogues
Aug 26, 2024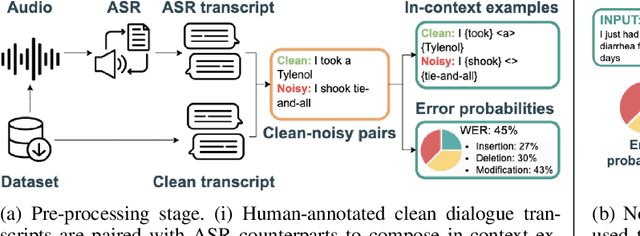
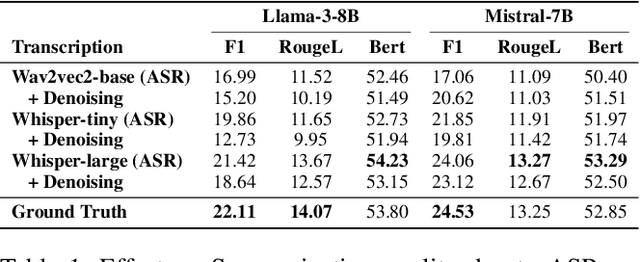

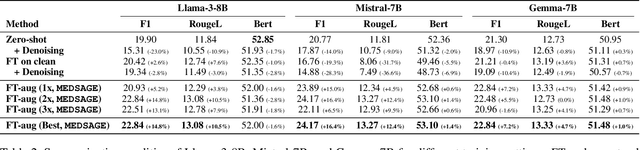
Automatic Speech Recognition (ASR) systems are pivotal in transcribing speech into text, yet the errors they introduce can significantly degrade the performance of downstream tasks like summarization. This issue is particularly pronounced in clinical dialogue summarization, a low-resource domain where supervised data for fine-tuning is scarce, necessitating the use of ASR models as black-box solutions. Employing conventional data augmentation for enhancing the noise robustness of summarization models is not feasible either due to the unavailability of sufficient medical dialogue audio recordings and corresponding ASR transcripts. To address this challenge, we propose MEDSAGE, an approach for generating synthetic samples for data augmentation using Large Language Models (LLMs). Specifically, we leverage the in-context learning capabilities of LLMs and instruct them to generate ASR-like errors based on a few available medical dialogue examples with audio recordings. Experimental results show that LLMs can effectively model ASR noise, and incorporating this noisy data into the training process significantly improves the robustness and accuracy of medical dialogue summarization systems. This approach addresses the challenges of noisy ASR outputs in critical applications, offering a robust solution to enhance the reliability of clinical dialogue summarization.
M-QALM: A Benchmark to Assess Clinical Reading Comprehension and Knowledge Recall in Large Language Models via Question Answering
Jun 06, 2024

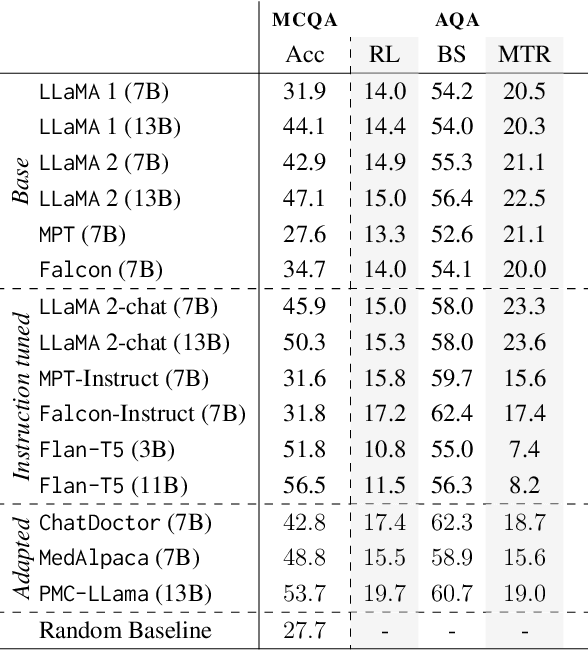

There is vivid research on adapting Large Language Models (LLMs) to perform a variety of tasks in high-stakes domains such as healthcare. Despite their popularity, there is a lack of understanding of the extent and contributing factors that allow LLMs to recall relevant knowledge and combine it with presented information in the clinical and biomedical domain: a fundamental pre-requisite for success on down-stream tasks. Addressing this gap, we use Multiple Choice and Abstractive Question Answering to conduct a large-scale empirical study on 22 datasets in three generalist and three specialist biomedical sub-domains. Our multifaceted analysis of the performance of 15 LLMs, further broken down by sub-domain, source of knowledge and model architecture, uncovers success factors such as instruction tuning that lead to improved recall and comprehension. We further show that while recently proposed domain-adapted models may lack adequate knowledge, directly fine-tuning on our collected medical knowledge datasets shows encouraging results, even generalising to unseen specialist sub-domains. We complement the quantitative results with a skill-oriented manual error analysis, which reveals a significant gap between the models' capabilities to simply recall necessary knowledge and to integrate it with the presented context. To foster research and collaboration in this field we share M-QALM, our resources, standardised methodology, and evaluation results, with the research community to facilitate further advancements in clinical knowledge representation learning within language models.
Automated Clinical Coding for Outpatient Departments
Dec 24, 2023Computerised clinical coding approaches aim to automate the process of assigning a set of codes to medical records. While there is active research pushing the state of the art on clinical coding for hospitalized patients, the outpatient setting -- where doctors tend to non-hospitalised patients -- is overlooked. Although both settings can be formalised as a multi-label classification task, they present unique and distinct challenges, which raises the question of whether the success of inpatient clinical coding approaches translates to the outpatient setting. This paper is the first to investigate how well state-of-the-art deep learning-based clinical coding approaches work in the outpatient setting at hospital scale. To this end, we collect a large outpatient dataset comprising over 7 million notes documenting over half a million patients. We adapt four state-of-the-art clinical coding approaches to this setting and evaluate their potential to assist coders. We find evidence that clinical coding in outpatient settings can benefit from more innovations in popular inpatient coding benchmarks. A deeper analysis of the factors contributing to the success -- amount and form of data and choice of document representation -- reveals the presence of easy-to-solve examples, the coding of which can be completely automated with a low error rate.
PULSAR at MEDIQA-Sum 2023: Large Language Models Augmented by Synthetic Dialogue Convert Patient Dialogues to Medical Records
Jul 05, 2023


This paper describes PULSAR, our system submission at the ImageClef 2023 MediQA-Sum task on summarising patient-doctor dialogues into clinical records. The proposed framework relies on domain-specific pre-training, to produce a specialised language model which is trained on task-specific natural data augmented by synthetic data generated by a black-box LLM. We find limited evidence towards the efficacy of domain-specific pre-training and data augmentation, while scaling up the language model yields the best performance gains. Our approach was ranked second and third among 13 submissions on task B of the challenge. Our code is available at https://github.com/yuping-wu/PULSAR.
PULSAR: Pre-training with Extracted Healthcare Terms for Summarising Patients' Problems and Data Augmentation with Black-box Large Language Models
Jun 05, 2023



Medical progress notes play a crucial role in documenting a patient's hospital journey, including his or her condition, treatment plan, and any updates for healthcare providers. Automatic summarisation of a patient's problems in the form of a problem list can aid stakeholders in understanding a patient's condition, reducing workload and cognitive bias. BioNLP 2023 Shared Task 1A focuses on generating a list of diagnoses and problems from the provider's progress notes during hospitalisation. In this paper, we introduce our proposed approach to this task, which integrates two complementary components. One component employs large language models (LLMs) for data augmentation; the other is an abstractive summarisation LLM with a novel pre-training objective for generating the patients' problems summarised as a list. Our approach was ranked second among all submissions to the shared task. The performance of our model on the development and test datasets shows that our approach is more robust on unknown data, with an improvement of up to 3.1 points over the same size of the larger model.
ADAPTERMIX: Exploring the Efficacy of Mixture of Adapters for Low-Resource TTS Adaptation
May 29, 2023There are significant challenges for speaker adaptation in text-to-speech for languages that are not widely spoken or for speakers with accents or dialects that are not well-represented in the training data. To address this issue, we propose the use of the "mixture of adapters" method. This approach involves adding multiple adapters within a backbone-model layer to learn the unique characteristics of different speakers. Our approach outperforms the baseline, with a noticeable improvement of 5% observed in speaker preference tests when using only one minute of data for each new speaker. Moreover, following the adapter paradigm, we fine-tune only the adapter parameters (11% of the total model parameters). This is a significant achievement in parameter-efficient speaker adaptation, and one of the first models of its kind. Overall, our proposed approach offers a promising solution to the speech synthesis techniques, particularly for adapting to speakers from diverse backgrounds.
Beyond Words: A Comprehensive Survey of Sentence Representations
May 23, 2023Sentence representations have become a critical component in natural language processing applications, such as retrieval, question answering, and text classification. They capture the semantics and meaning of a sentence, enabling machines to understand and reason over human language. In recent years, significant progress has been made in developing methods for learning sentence representations, including unsupervised, supervised, and transfer learning approaches. In this paper, we provide an overview of the different methods for sentence representation learning, including both traditional and deep learning-based techniques. We provide a systematic organization of the literature on sentence representation learning, highlighting the key contributions and challenges in this area. Overall, our review highlights the progress made in sentence representation learning, the importance of this area in natural language processing, and the challenges that remain. We conclude with directions for future research, suggesting potential avenues for improving the quality and efficiency of sentence representations in NLP applications.
UDApter -- Efficient Domain Adaptation Using Adapters
Feb 16, 2023We propose two methods to make unsupervised domain adaptation (UDA) more parameter efficient using adapters, small bottleneck layers interspersed with every layer of the large-scale pre-trained language model (PLM). The first method deconstructs UDA into a two-step process: first by adding a domain adapter to learn domain-invariant information and then by adding a task adapter that uses domain-invariant information to learn task representations in the source domain. The second method jointly learns a supervised classifier while reducing the divergence measure. Compared to strong baselines, our simple methods perform well in natural language inference (MNLI) and the cross-domain sentiment classification task. We even outperform unsupervised domain adaptation methods such as DANN and DSN in sentiment classification, and we are within 0.85% F1 for natural language inference task, by fine-tuning only a fraction of the full model parameters. We release our code at https://github.com/declare-lab/domadapter
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.