 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEDSAGE: Enhancing Robustness of Medical Dialogue Summarization to ASR Errors with LLM-generated Synthetic Dialogues
Aug 26, 2024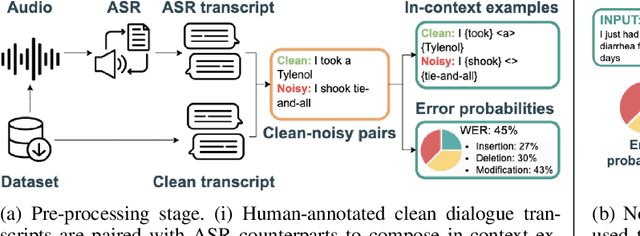
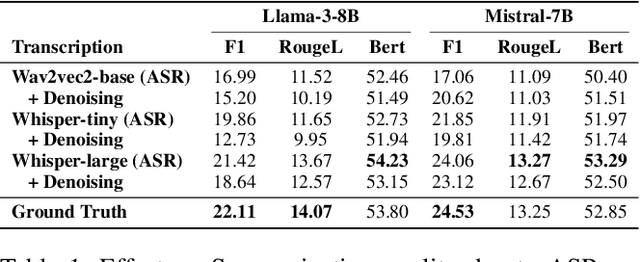

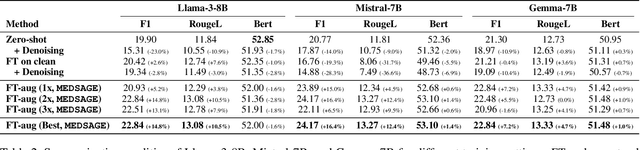
Automatic Speech Recognition (ASR) systems are pivotal in transcribing speech into text, yet the errors they introduce can significantly degrade the performance of downstream tasks like summarization. This issue is particularly pronounced in clinical dialogue summarization, a low-resource domain where supervised data for fine-tuning is scarce, necessitating the use of ASR models as black-box solutions. Employing conventional data augmentation for enhancing the noise robustness of summarization models is not feasible either due to the unavailability of sufficient medical dialogue audio recordings and corresponding ASR transcripts. To address this challenge, we propose MEDSAGE, an approach for generating synthetic samples for data augmentation using Large Language Models (LLMs). Specifically, we leverage the in-context learning capabilities of LLMs and instruct them to generate ASR-like errors based on a few available medical dialogue examples with audio recordings. Experimental results show that LLMs can effectively model ASR noise, and incorporating this noisy data into the training process significantly improves the robustness and accuracy of medical dialogue summarization systems. This approach addresses the challenges of noisy ASR outputs in critical applications, offering a robust solution to enhance the reliability of clinical dialogue summarization.
Condensed Sample-Guided Model Inversion for Knowledge Distillation
Aug 25, 2024



Knowledge distillation (KD) is a key element in neural network compression that allows knowledge transfer from a pre-trained teacher model to a more compact student model. KD relies on access to the training dataset, which may not always be fully available due to privacy concerns or logistical issues related to the size of the data. To address this, "data-free" KD methods use synthetic data, generated through model inversion, to mimic the target data distribution. However, conventional model inversion methods are not designed to utilize supplementary information from the target dataset, and thus, cannot leverage it to improve performance, even when it is available. In this paper, we consider condensed samples, as a form of supplementary information, and introduce a method for using them to better approximate the target data distribution, thereby enhancing the KD performance. Our approach is versatile, evidenced by improvements of up to 11.4% in KD accuracy across various datasets and model inversion-based methods. Importantly, it remains effective even when using as few as one condensed sample per class, and can also enhance performance in few-shot scenarios where only limited real data samples are available.
LLMs are not Zero-Shot Reasoners for Biomedical Information Extraction
Aug 22, 2024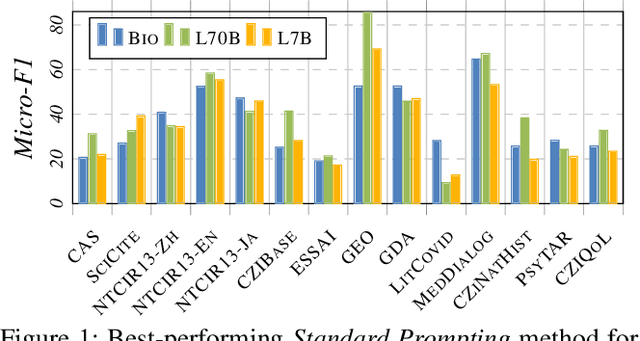
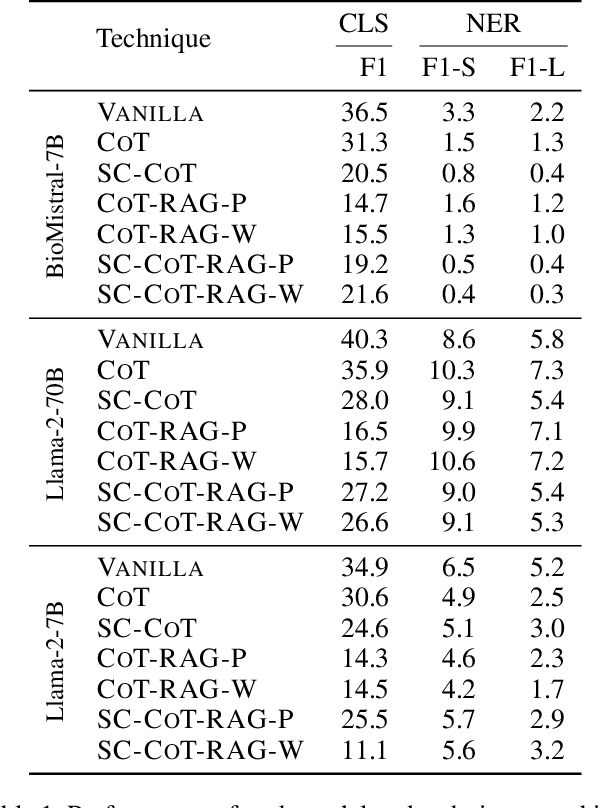
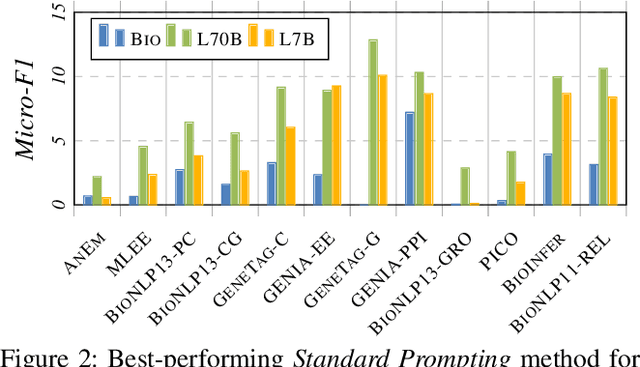
Large Language Models (LLMs) are increasingly adopted for applications in healthcare, reaching the performance of domain experts on tasks such as question answering and document summarisation. Despite their success on these tasks, it is unclear how well LLMs perform on tasks that are traditionally pursued in the biomedical domain, such as structured information extration. To breach this gap, in this paper, we systematically benchmark LLM performance in Medical Classification and Named Entity Recognition (NER) tasks. We aim to disentangle the contribution of different factors to the performance, particularly the impact of LLMs' task knowledge and reasoning capabilities, their (parametric) domain knowledge, and addition of external knowledge. To this end we evaluate various open LLMs -- including BioMistral and Llama-2 models -- on a diverse set of biomedical datasets, using standard prompting, Chain-of-Thought (CoT) and Self-Consistency based reasoning as well as Retrieval-Augmented Generation (RAG) with PubMed and Wikipedia corpora. Counter-intuitively, our results reveal that standard prompting consistently outperforms more complex techniques across both tasks, laying bare the limitations in the current application of CoT, self-consistency and RAG in the biomedical domain. Our findings suggest that advanced prompting methods developed for knowledge- or reasoning-intensive tasks, such as CoT or RAG, are not easily portable to biomedical tasks where precise structured outputs are required. This highlights the need for more effective integration of external knowledge and reasoning mechanisms in LLMs to enhance their performance in real-world biomedical applications.
Generalizing Teacher Networks for Effective Knowledge Distillation Across Student Architectures
Jul 22, 2024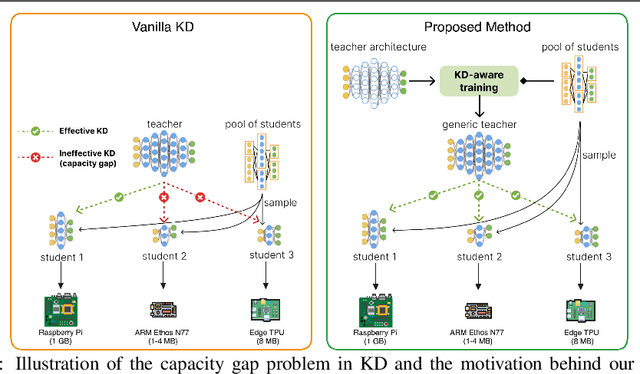

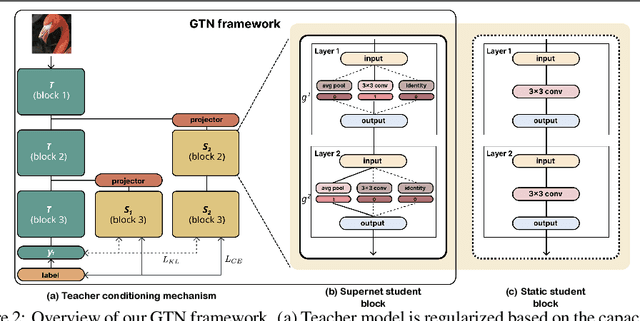
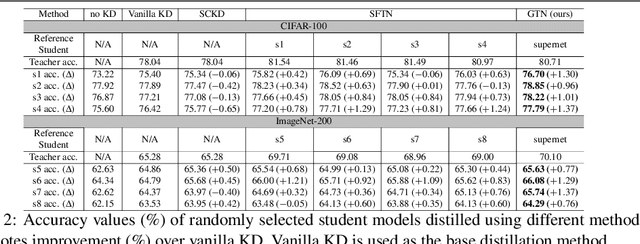
Knowledge distillation (KD) is a model compression method that entails training a compact student model to emulate the performance of a more complex teacher model. However, the architectural capacity gap between the two models limits the effectiveness of knowledge transfer. Addressing this issue, previous works focused on customizing teacher-student pairs to improve compatibility, a computationally expensive process that needs to be repeated every time either model changes. Hence, these methods are impractical when a teacher model has to be compressed into different student models for deployment on multiple hardware devices with distinct resource constraints. In this work, we propose Generic Teacher Network (GTN), a one-off KD-aware training to create a generic teacher capable of effectively transferring knowledge to any student model sampled from a given finite pool of architectures. To this end, we represent the student pool as a weight-sharing supernet and condition our generic teacher to align with the capacities of various student architectures sampled from this supernet. Experimental evaluation shows that our method both improves overall KD effectiveness and amortizes the minimal additional training cost of the generic teacher across students in the pool.
CRISP: Hybrid Structured Sparsity for Class-aware Model Pruning
Nov 24, 2023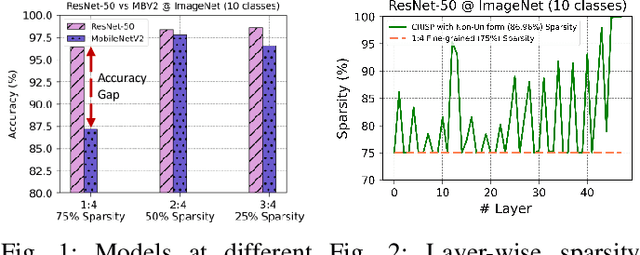
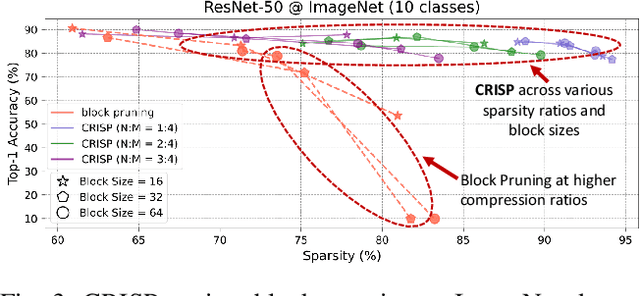
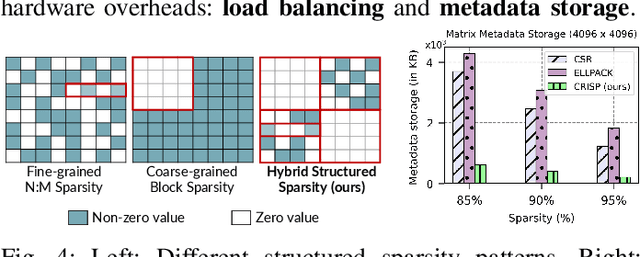
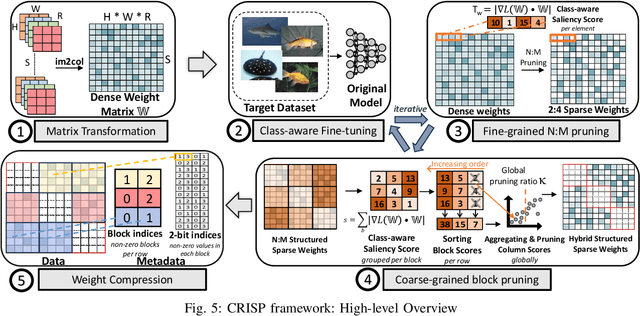
Machine learning pipelines for classification tasks often train a universal model to achieve accuracy across a broad range of classes. However, a typical user encounters only a limited selection of classes regularly. This disparity provides an opportunity to enhance computational efficiency by tailoring models to focus on user-specific classes. Existing works rely on unstructured pruning, which introduces randomly distributed non-zero values in the model, making it unsuitable for hardware acceleration. Alternatively, some approaches employ structured pruning, such as channel pruning, but these tend to provide only minimal compression and may lead to reduced model accuracy. In this work, we propose CRISP, a novel pruning framework leveraging a hybrid structured sparsity pattern that combines both fine-grained N:M structured sparsity and coarse-grained block sparsity. Our pruning strategy is guided by a gradient-based class-aware saliency score, allowing us to retain weights crucial for user-specific classes. CRISP achieves high accuracy with minimal memory consumption for popular models like ResNet-50, VGG-16, and MobileNetV2 on ImageNet and CIFAR-100 datasets. Moreover, CRISP delivers up to 14$\times$ reduction in latency and energy consumption compared to existing pruning methods while maintaining comparable accuracy. Our code is available at https://github.com/shivmgg/CRISP/.
Visual-Policy Learning through Multi-Camera View to Single-Camera View Knowledge Distillation for Robot Manipulation Tasks
Mar 13, 2023The use of multi-camera views simultaneously has been shown to improve the generalization capabilities and performance of visual policies. However, the hardware cost and design constraints in real-world scenarios can potentially make it challenging to use multiple cameras. In this study, we present a novel approach to enhance the generalization performance of vision-based Reinforcement Learning (RL) algorithms for robotic manipulation tasks. Our proposed method involves utilizing a technique known as knowledge distillation, in which a pre-trained ``teacher'' policy trained with multiple camera viewpoints guides a ``student'' policy in learning from a single camera viewpoint. To enhance the student policy's robustness against camera location perturbations, it is trained using data augmentation and extreme viewpoint changes. As a result, the student policy learns robust visual features that allow it to locate the object of interest accurately and consistently, regardless of the camera viewpoint. The efficacy and efficiency of the proposed method were evaluated both in simulation and real-world environments. The results demonstrate that the single-view visual student policy can successfully learn to grasp and lift a challenging object, which was not possible with a single-view policy alone. Furthermore, the student policy demonstrates zero-shot transfer capability, where it can successfully grasp and lift objects in real-world scenarios for unseen visual configurations.
Robust and Resource-Efficient Data-Free Knowledge Distillation by Generative Pseudo Replay
Jan 09, 2022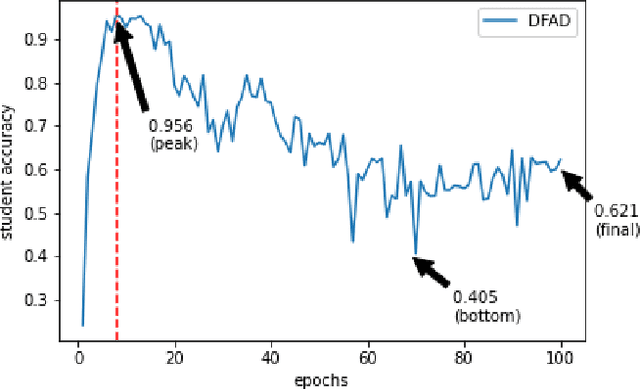

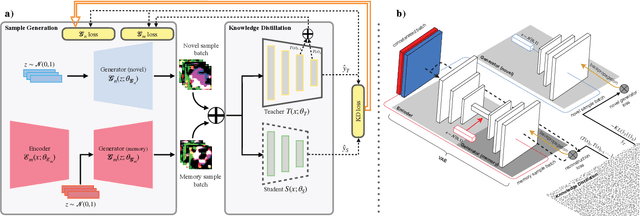

Data-Free Knowledge Distillation (KD) allows knowledge transfer from a trained neural network (teacher) to a more compact one (student) in the absence of original training data. Existing works use a validation set to monitor the accuracy of the student over real data and report the highest performance throughout the entire process. However, validation data may not be available at distillation time either, making it infeasible to record the student snapshot that achieved the peak accuracy. Therefore, a practical data-free KD method should be robust and ideally provide monotonically increasing student accuracy during distillation. This is challenging because the student experiences knowledge degradation due to the distribution shift of the synthetic data. A straightforward approach to overcome this issue is to store and rehearse the generated samples periodically, which increases the memory footprint and creates privacy concerns. We propose to model the distribution of the previously observed synthetic samples with a generative network. In particular, we design a Variational Autoencoder (VAE) with a training objective that is customized to learn the synthetic data representations optimally. The student is rehearsed by the generative pseudo replay technique, with samples produced by the VAE. Hence knowledge degradation can be prevented without storing any samples. Experiments on image classification benchmarks show that our method optimizes the expected value of the distilled model accuracy while eliminating the large memory overhead incurred by the sample-storing methods.
Preventing Catastrophic Forgetting and Distribution Mismatch in Knowledge Distillation via Synthetic Data
Aug 11, 2021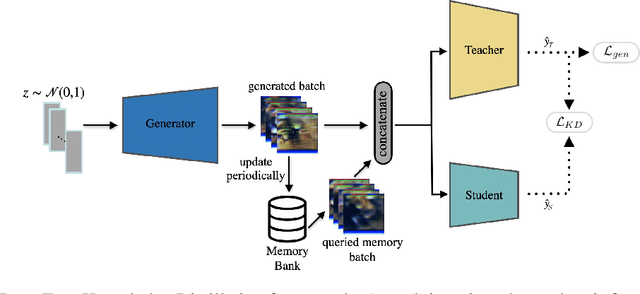
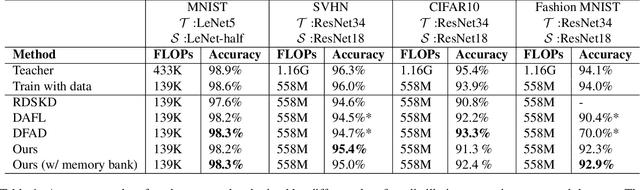

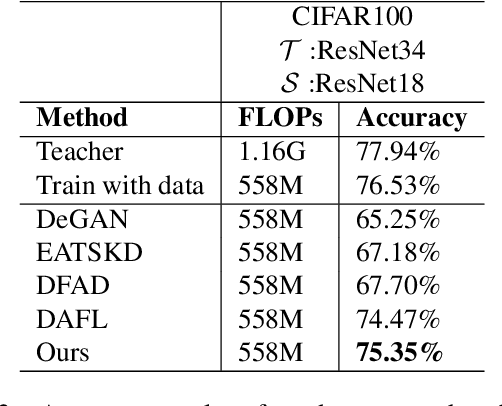
With the increasing popularity of deep learning on edge devices, compressing large neural networks to meet the hardware requirements of resource-constrained devices became a significant research direction. Numerous compression methodologies are currently being used to reduce the memory sizes and energy consumption of neural networks. Knowledge distillation (KD) is among such methodologies and it functions by using data samples to transfer the knowledge captured by a large model (teacher) to a smaller one(student). However, due to various reasons, the original training data might not be accessible at the compression stage. Therefore, data-free model compression is an ongoing research problem that has been addressed by various works. In this paper, we point out that catastrophic forgetting is a problem that can potentially be observed in existing data-free distillation methods. Moreover, the sample generation strategies in some of these methods could result in a mismatch between the synthetic and real data distributions. To prevent such problems, we propose a data-free KD framework that maintains a dynamic collection of generated samples over time. Additionally, we add the constraint of matching the real data distribution in sample generation strategies that target maximum information gain. Our experiments demonstrate that we can improve the accuracy of the student models obtained via KD when compared with state-of-the-art approaches on the SVHN, Fashion MNIST and CIFAR100 datasets.