 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreventing Catastrophic Forgetting and Distribution Mismatch in Knowledge Distillation via Synthetic Data
Paper and Code
Aug 11, 2021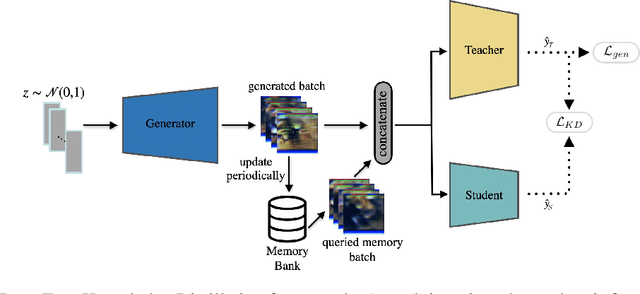
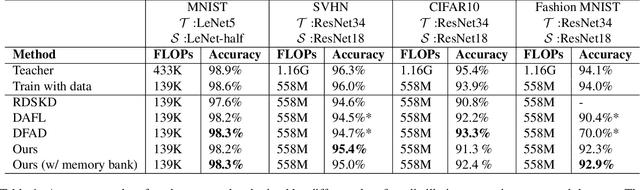

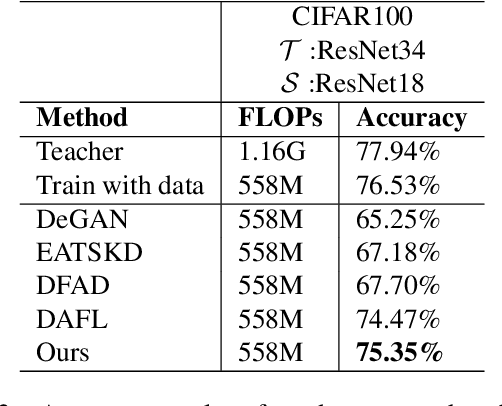
With the increasing popularity of deep learning on edge devices, compressing large neural networks to meet the hardware requirements of resource-constrained devices became a significant research direction. Numerous compression methodologies are currently being used to reduce the memory sizes and energy consumption of neural networks. Knowledge distillation (KD) is among such methodologies and it functions by using data samples to transfer the knowledge captured by a large model (teacher) to a smaller one(student). However, due to various reasons, the original training data might not be accessible at the compression stage. Therefore, data-free model compression is an ongoing research problem that has been addressed by various works. In this paper, we point out that catastrophic forgetting is a problem that can potentially be observed in existing data-free distillation methods. Moreover, the sample generation strategies in some of these methods could result in a mismatch between the synthetic and real data distributions. To prevent such problems, we propose a data-free KD framework that maintains a dynamic collection of generated samples over time. Additionally, we add the constraint of matching the real data distribution in sample generation strategies that target maximum information gain. Our experiments demonstrate that we can improve the accuracy of the student models obtained via KD when compared with state-of-the-art approaches on the SVHN, Fashion MNIST and CIFAR100 datasets.