 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHALO: Hardware-aware quantization with low critical-path-delay weights for LLM acceleration
Feb 27, 2025



Quantization is critical for realizing efficient inference of LLMs. Traditional quantization methods are hardware-agnostic, limited to bit-width constraints, and lacking circuit-level insights, such as timing and energy characteristics of Multiply-Accumulate (MAC) units. We introduce HALO, a versatile framework that adapts to various hardware through a Hardware-Aware Post-Training Quantization (PTQ) approach. By leveraging MAC unit properties, HALO minimizes critical-path delays and enables dynamic frequency scaling. Deployed on LLM accelerators like TPUs and GPUs, HALO achieves on average 270% performance gains and 51% energy savings, all with minimal accuracy drop.
Condensed Sample-Guided Model Inversion for Knowledge Distillation
Aug 25, 2024



Knowledge distillation (KD) is a key element in neural network compression that allows knowledge transfer from a pre-trained teacher model to a more compact student model. KD relies on access to the training dataset, which may not always be fully available due to privacy concerns or logistical issues related to the size of the data. To address this, "data-free" KD methods use synthetic data, generated through model inversion, to mimic the target data distribution. However, conventional model inversion methods are not designed to utilize supplementary information from the target dataset, and thus, cannot leverage it to improve performance, even when it is available. In this paper, we consider condensed samples, as a form of supplementary information, and introduce a method for using them to better approximate the target data distribution, thereby enhancing the KD performance. Our approach is versatile, evidenced by improvements of up to 11.4% in KD accuracy across various datasets and model inversion-based methods. Importantly, it remains effective even when using as few as one condensed sample per class, and can also enhance performance in few-shot scenarios where only limited real data samples are available.
Generalizing Teacher Networks for Effective Knowledge Distillation Across Student Architectures
Jul 22, 2024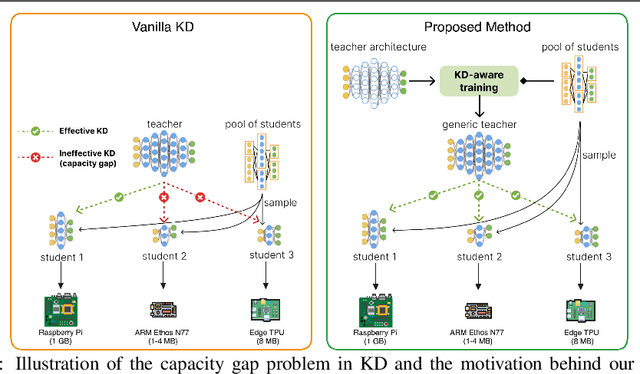

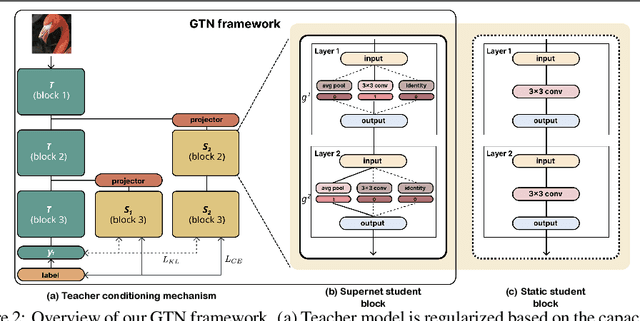
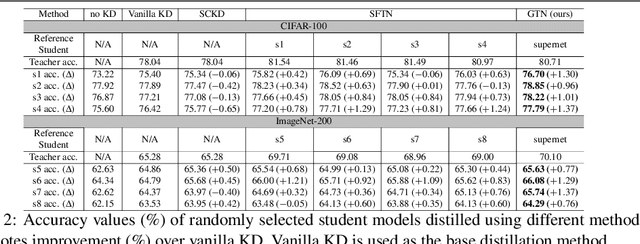
Knowledge distillation (KD) is a model compression method that entails training a compact student model to emulate the performance of a more complex teacher model. However, the architectural capacity gap between the two models limits the effectiveness of knowledge transfer. Addressing this issue, previous works focused on customizing teacher-student pairs to improve compatibility, a computationally expensive process that needs to be repeated every time either model changes. Hence, these methods are impractical when a teacher model has to be compressed into different student models for deployment on multiple hardware devices with distinct resource constraints. In this work, we propose Generic Teacher Network (GTN), a one-off KD-aware training to create a generic teacher capable of effectively transferring knowledge to any student model sampled from a given finite pool of architectures. To this end, we represent the student pool as a weight-sharing supernet and condition our generic teacher to align with the capacities of various student architectures sampled from this supernet. Experimental evaluation shows that our method both improves overall KD effectiveness and amortizes the minimal additional training cost of the generic teacher across students in the pool.
SWAT: Scalable and Efficient Window Attention-based Transformers Acceleration on FPGAs
May 27, 2024



Efficiently supporting long context length is crucial for Transformer models. The quadratic complexity of the self-attention computation plagues traditional Transformers. Sliding window-based static sparse attention mitigates the problem by limiting the attention scope of the input tokens, reducing the theoretical complexity from quadratic to linear. Although the sparsity induced by window attention is highly structured, it does not align perfectly with the microarchitecture of the conventional accelerators, leading to suboptimal implementation. In response, we propose a dataflow-aware FPGA-based accelerator design, SWAT, that efficiently leverages the sparsity to achieve scalable performance for long input. The proposed microarchitecture is based on a design that maximizes data reuse by using a combination of row-wise dataflow, kernel fusion optimization, and an input-stationary design considering the distributed memory and computation resources of FPGA. Consequently, it achieves up to 22$\times$ and 5.7$\times$ improvement in latency and energy efficiency compared to the baseline FPGA-based accelerator and 15$\times$ energy efficiency compared to GPU-based solution.
CRISP: Hybrid Structured Sparsity for Class-aware Model Pruning
Nov 24, 2023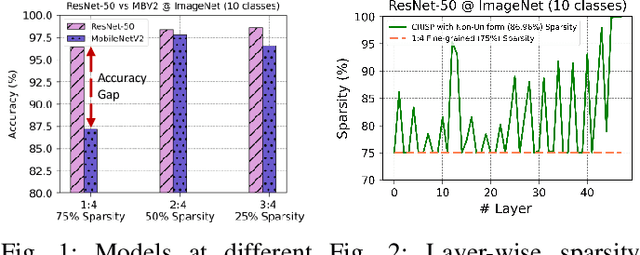
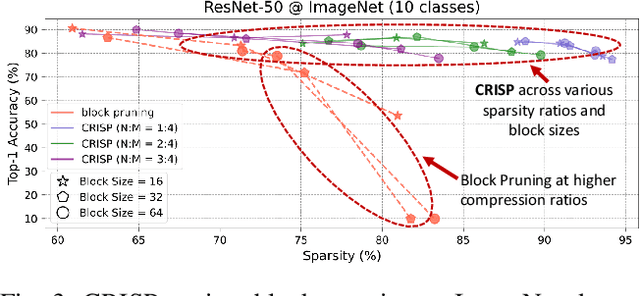
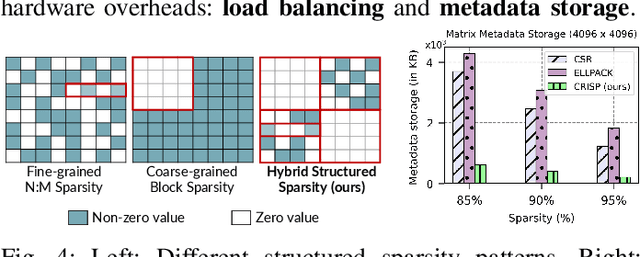
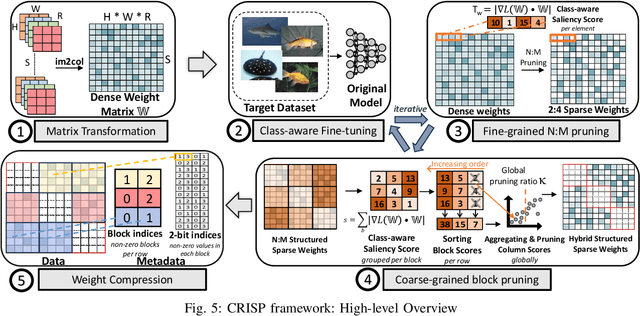
Machine learning pipelines for classification tasks often train a universal model to achieve accuracy across a broad range of classes. However, a typical user encounters only a limited selection of classes regularly. This disparity provides an opportunity to enhance computational efficiency by tailoring models to focus on user-specific classes. Existing works rely on unstructured pruning, which introduces randomly distributed non-zero values in the model, making it unsuitable for hardware acceleration. Alternatively, some approaches employ structured pruning, such as channel pruning, but these tend to provide only minimal compression and may lead to reduced model accuracy. In this work, we propose CRISP, a novel pruning framework leveraging a hybrid structured sparsity pattern that combines both fine-grained N:M structured sparsity and coarse-grained block sparsity. Our pruning strategy is guided by a gradient-based class-aware saliency score, allowing us to retain weights crucial for user-specific classes. CRISP achieves high accuracy with minimal memory consumption for popular models like ResNet-50, VGG-16, and MobileNetV2 on ImageNet and CIFAR-100 datasets. Moreover, CRISP delivers up to 14$\times$ reduction in latency and energy consumption compared to existing pruning methods while maintaining comparable accuracy. Our code is available at https://github.com/shivmgg/CRISP/.
Post-Training Quantization with Low-precision Minifloats and Integers on FPGAs
Nov 21, 2023



Post-Training Quantization (PTQ) is a powerful technique for model compression, reducing the precision of neural networks without additional training overhead. Recent works have investigated adopting 8-bit floating-point quantization (FP8) in the context of PTQ for model inference. However, the exploration of floating-point formats smaller than 8 bits and their comparison with integer quantization remains relatively limited. In this work, we present minifloats, which are reduced-precision floating-point formats capable of further reducing the memory footprint, latency, and energy cost of a model while approaching full-precision model accuracy. Our work presents a novel PTQ design-space exploration, comparing minifloat and integer quantization schemes across a range of 3 to 8 bits for both weights and activations. We examine the applicability of various PTQ techniques to minifloats, including weight equalization, bias correction, SmoothQuant, gradient-based learned rounding, and the GPTQ method. Our experiments validate the effectiveness of low-precision minifloats when compared to their integer counterparts across a spectrum of accuracy-precision trade-offs on a set of reference deep learning vision workloads. Finally, we evaluate our results against an FPGA-based hardware cost model, showing that integer quantization often remains the Pareto-optimal option, given its relatively smaller hardware resource footprint.
InkStream: Real-time GNN Inference on Streaming Graphs via Incremental Update
Sep 20, 2023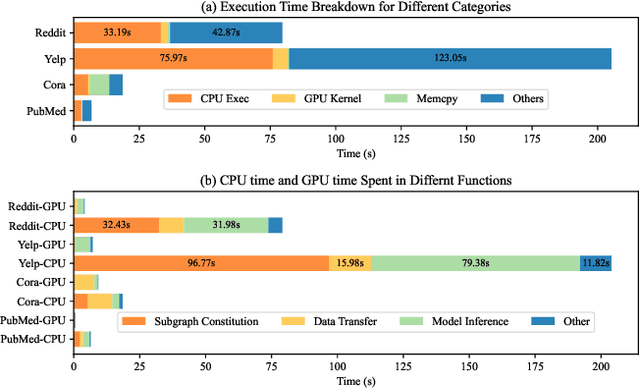
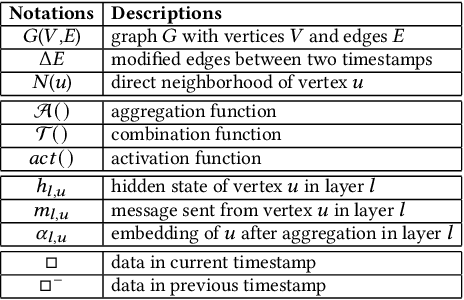
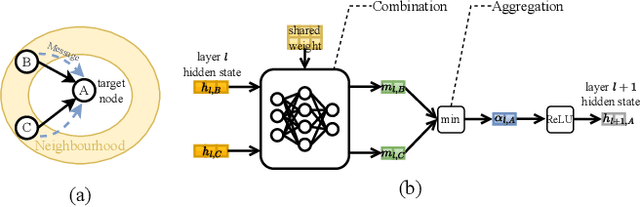

Classic Graph Neural Network (GNN) inference approaches, designed for static graphs, are ill-suited for streaming graphs that evolve with time. The dynamism intrinsic to streaming graphs necessitates constant updates, posing unique challenges to acceleration on GPU. We address these challenges based on two key insights: (1) Inside the $k$-hop neighborhood, a significant fraction of the nodes is not impacted by the modified edges when the model uses min or max as aggregation function; (2) When the model weights remain static while the graph structure changes, node embeddings can incrementally evolve over time by computing only the impacted part of the neighborhood. With these insights, we propose a novel method, InkStream, designed for real-time inference with minimal memory access and computation, while ensuring an identical output to conventional methods. InkStream operates on the principle of propagating and fetching data only when necessary. It uses an event-based system to control inter-layer effect propagation and intra-layer incremental updates of node embedding. InkStream is highly extensible and easily configurable by allowing users to create and process customized events. We showcase that less than 10 lines of additional user code are needed to support popular GNN models such as GCN, GraphSAGE, and GIN. Our experiments with three GNN models on four large graphs demonstrate that InkStream accelerates by 2.5-427$\times$ on a CPU cluster and 2.4-343$\times$ on two different GPU clusters while producing identical outputs as GNN model inference on the latest graph snapshot.
Accelerating Edge AI with Morpher: An Integrated Design, Compilation and Simulation Framework for CGRAs
Sep 12, 2023

Coarse-Grained Reconfigurable Arrays (CGRAs) hold great promise as power-efficient edge accelerator, offering versatility beyond AI applications. Morpher, an open-source, architecture-adaptive CGRA design framework, is specifically designed to explore the vast design space of CGRAs. The comprehensive ecosystem of Morpher includes a tailored compiler, simulator, accelerator synthesis, and validation framework. This study provides an overview of Morpher, highlighting its capabilities in automatically compiling AI application kernels onto user-defined CGRA architectures and verifying their functionality. Through the Morpher framework, the versatility of CGRAs is harnessed to facilitate efficient compilation and verification of edge AI applications, covering important kernels representative of a wide range of embedded AI workloads. Morpher is available online at https://github.com/ecolab-nus/morpher-v2.
Robust and Resource-Efficient Data-Free Knowledge Distillation by Generative Pseudo Replay
Jan 09, 2022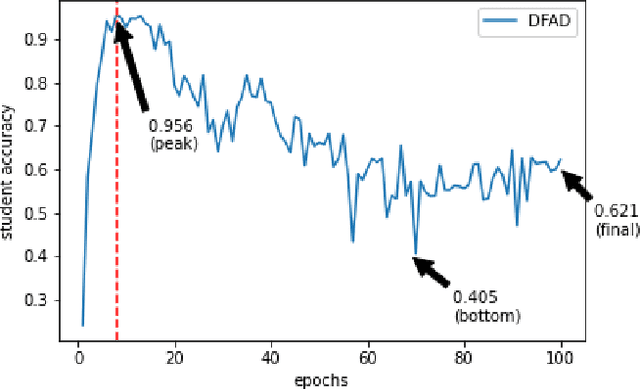

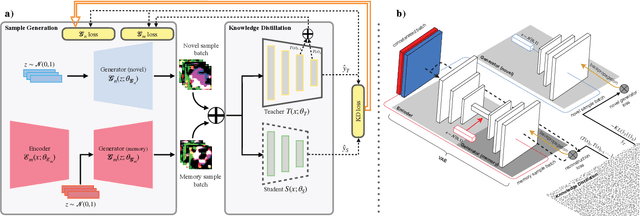

Data-Free Knowledge Distillation (KD) allows knowledge transfer from a trained neural network (teacher) to a more compact one (student) in the absence of original training data. Existing works use a validation set to monitor the accuracy of the student over real data and report the highest performance throughout the entire process. However, validation data may not be available at distillation time either, making it infeasible to record the student snapshot that achieved the peak accuracy. Therefore, a practical data-free KD method should be robust and ideally provide monotonically increasing student accuracy during distillation. This is challenging because the student experiences knowledge degradation due to the distribution shift of the synthetic data. A straightforward approach to overcome this issue is to store and rehearse the generated samples periodically, which increases the memory footprint and creates privacy concerns. We propose to model the distribution of the previously observed synthetic samples with a generative network. In particular, we design a Variational Autoencoder (VAE) with a training objective that is customized to learn the synthetic data representations optimally. The student is rehearsed by the generative pseudo replay technique, with samples produced by the VAE. Hence knowledge degradation can be prevented without storing any samples. Experiments on image classification benchmarks show that our method optimizes the expected value of the distilled model accuracy while eliminating the large memory overhead incurred by the sample-storing methods.
Preventing Catastrophic Forgetting and Distribution Mismatch in Knowledge Distillation via Synthetic Data
Aug 11, 2021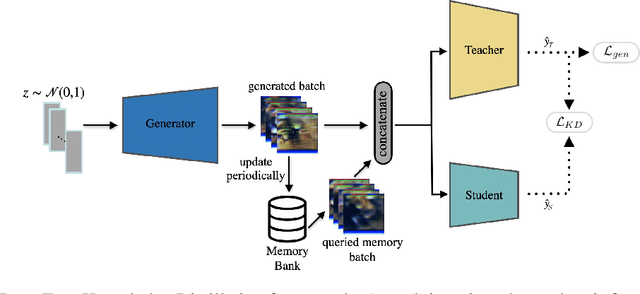
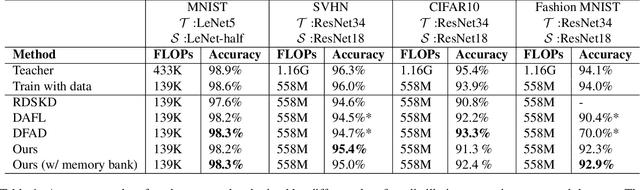

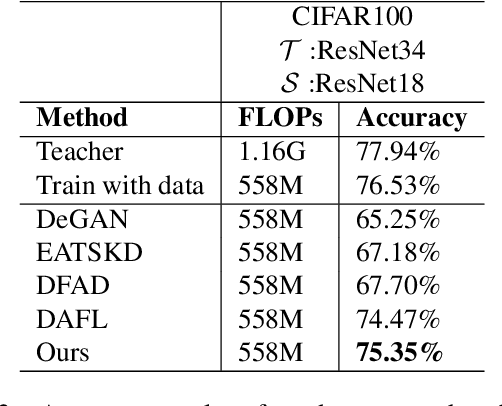
With the increasing popularity of deep learning on edge devices, compressing large neural networks to meet the hardware requirements of resource-constrained devices became a significant research direction. Numerous compression methodologies are currently being used to reduce the memory sizes and energy consumption of neural networks. Knowledge distillation (KD) is among such methodologies and it functions by using data samples to transfer the knowledge captured by a large model (teacher) to a smaller one(student). However, due to various reasons, the original training data might not be accessible at the compression stage. Therefore, data-free model compression is an ongoing research problem that has been addressed by various works. In this paper, we point out that catastrophic forgetting is a problem that can potentially be observed in existing data-free distillation methods. Moreover, the sample generation strategies in some of these methods could result in a mismatch between the synthetic and real data distributions. To prevent such problems, we propose a data-free KD framework that maintains a dynamic collection of generated samples over time. Additionally, we add the constraint of matching the real data distribution in sample generation strategies that target maximum information gain. Our experiments demonstrate that we can improve the accuracy of the student models obtained via KD when compared with state-of-the-art approaches on the SVHN, Fashion MNIST and CIFAR100 datasets.