 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHALO: Hardware-aware quantization with low critical-path-delay weights for LLM acceleration
Feb 27, 2025



Quantization is critical for realizing efficient inference of LLMs. Traditional quantization methods are hardware-agnostic, limited to bit-width constraints, and lacking circuit-level insights, such as timing and energy characteristics of Multiply-Accumulate (MAC) units. We introduce HALO, a versatile framework that adapts to various hardware through a Hardware-Aware Post-Training Quantization (PTQ) approach. By leveraging MAC unit properties, HALO minimizes critical-path delays and enables dynamic frequency scaling. Deployed on LLM accelerators like TPUs and GPUs, HALO achieves on average 270% performance gains and 51% energy savings, all with minimal accuracy drop.
NOVA: NoC-based Vector Unit for Mapping Attention Layers on a CNN Accelerator
May 07, 2024Attention mechanisms are becoming increasingly popular, being used in neural network models in multiple domains such as natural language processing (NLP) and vision applications, especially at the edge. However, attention layers are difficult to map onto existing neuro accelerators since they have a much higher density of non-linear operations, which lead to inefficient utilization of today's vector units. This work introduces NOVA, a NoC-based Vector Unit that can perform non-linear operations within the NoC of the accelerators, and can be overlaid onto existing neuro accelerators to map attention layers at the edge. Our results show that the NOVA architecture is up to 37.8x more power-efficient than state-of-the-art hardware approximators when running existing attention-based neural networks.
Shenjing: A low power reconfigurable neuromorphic accelerator with partial-sum and spike networks-on-chip
Nov 25, 2019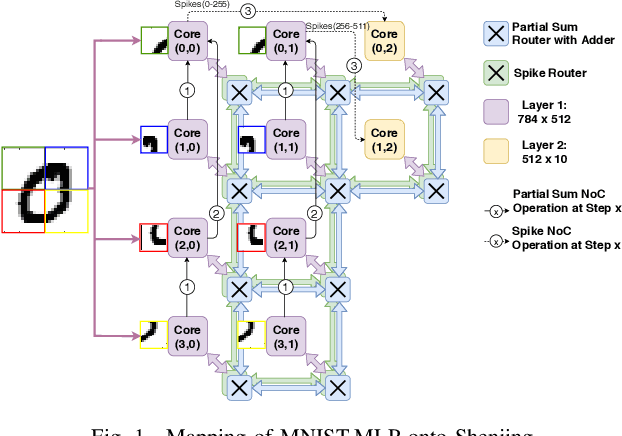

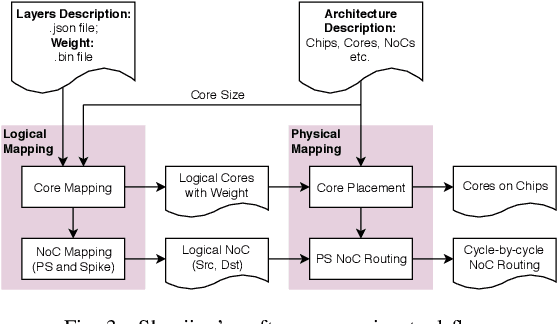
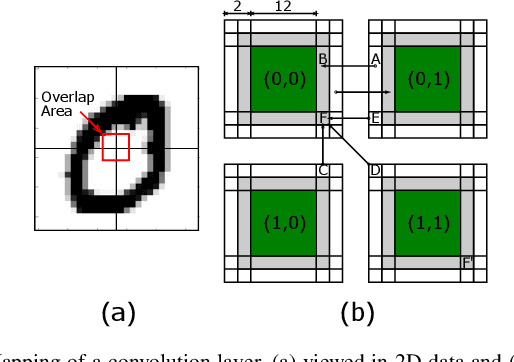
The next wave of on-device AI will likely require energy-efficient deep neural networks. Brain-inspired spiking neural networks (SNN) has been identified to be a promising candidate. Doing away with the need for multipliers significantly reduces energy. For on-device applications, besides computation, communication also incurs a significant amount of energy and time. In this paper, we propose Shenjing, a configurable SNN architecture which fully exposes all on-chip communications to software, enabling software mapping of SNN models with high accuracy at low power. Unlike prior SNN architectures like TrueNorth, Shenjing does not require any model modification and retraining for the mapping. We show that conventional artificial neural networks (ANN) such as multilayer perceptron, convolutional neural networks, as well as the latest residual neural networks can be mapped successfully onto Shenjing, realizing ANNs with SNN's energy efficiency. For the MNIST inference problem using a multilayer perceptron, we were able to achieve an accuracy of 96% while consuming just 1.26mW using 10 Shenjing cores.