 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCondensed Sample-Guided Model Inversion for Knowledge Distillation
Aug 25, 2024



Knowledge distillation (KD) is a key element in neural network compression that allows knowledge transfer from a pre-trained teacher model to a more compact student model. KD relies on access to the training dataset, which may not always be fully available due to privacy concerns or logistical issues related to the size of the data. To address this, "data-free" KD methods use synthetic data, generated through model inversion, to mimic the target data distribution. However, conventional model inversion methods are not designed to utilize supplementary information from the target dataset, and thus, cannot leverage it to improve performance, even when it is available. In this paper, we consider condensed samples, as a form of supplementary information, and introduce a method for using them to better approximate the target data distribution, thereby enhancing the KD performance. Our approach is versatile, evidenced by improvements of up to 11.4% in KD accuracy across various datasets and model inversion-based methods. Importantly, it remains effective even when using as few as one condensed sample per class, and can also enhance performance in few-shot scenarios where only limited real data samples are available.
Robust and Resource-Efficient Data-Free Knowledge Distillation by Generative Pseudo Replay
Jan 09, 2022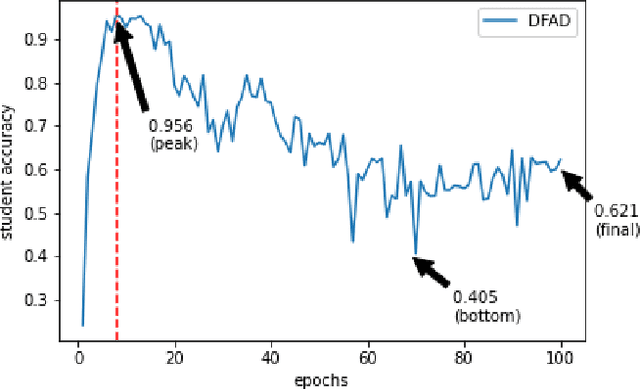


Data-Free Knowledge Distillation (KD) allows knowledge transfer from a trained neural network (teacher) to a more compact one (student) in the absence of original training data. Existing works use a validation set to monitor the accuracy of the student over real data and report the highest performance throughout the entire process. However, validation data may not be available at distillation time either, making it infeasible to record the student snapshot that achieved the peak accuracy. Therefore, a practical data-free KD method should be robust and ideally provide monotonically increasing student accuracy during distillation. This is challenging because the student experiences knowledge degradation due to the distribution shift of the synthetic data. A straightforward approach to overcome this issue is to store and rehearse the generated samples periodically, which increases the memory footprint and creates privacy concerns. We propose to model the distribution of the previously observed synthetic samples with a generative network. In particular, we design a Variational Autoencoder (VAE) with a training objective that is customized to learn the synthetic data representations optimally. The student is rehearsed by the generative pseudo replay technique, with samples produced by the VAE. Hence knowledge degradation can be prevented without storing any samples. Experiments on image classification benchmarks show that our method optimizes the expected value of the distilled model accuracy while eliminating the large memory overhead incurred by the sample-storing methods.
Preventing Catastrophic Forgetting and Distribution Mismatch in Knowledge Distillation via Synthetic Data
Aug 11, 2021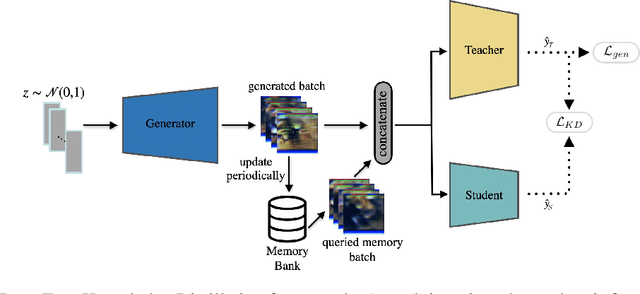
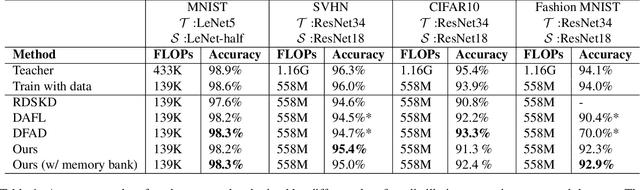

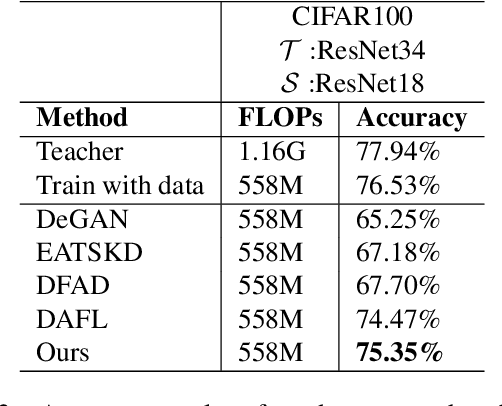
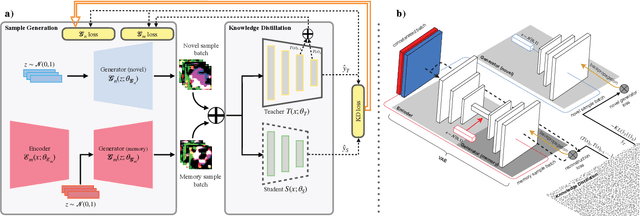
With the increasing popularity of deep learning on edge devices, compressing large neural networks to meet the hardware requirements of resource-constrained devices became a significant research direction. Numerous compression methodologies are currently being used to reduce the memory sizes and energy consumption of neural networks. Knowledge distillation (KD) is among such methodologies and it functions by using data samples to transfer the knowledge captured by a large model (teacher) to a smaller one(student). However, due to various reasons, the original training data might not be accessible at the compression stage. Therefore, data-free model compression is an ongoing research problem that has been addressed by various works. In this paper, we point out that catastrophic forgetting is a problem that can potentially be observed in existing data-free distillation methods. Moreover, the sample generation strategies in some of these methods could result in a mismatch between the synthetic and real data distributions. To prevent such problems, we propose a data-free KD framework that maintains a dynamic collection of generated samples over time. Additionally, we add the constraint of matching the real data distribution in sample generation strategies that target maximum information gain. Our experiments demonstrate that we can improve the accuracy of the student models obtained via KD when compared with state-of-the-art approaches on the SVHN, Fashion MNIST and CIFAR100 datasets.