 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2Q+: Improving Accumulator-Aware Weight Quantization
Jan 19, 2024Quantization techniques commonly reduce the inference costs of neural networks by restricting the precision of weights and activations. Recent studies show that also reducing the precision of the accumulator can further improve hardware efficiency at the risk of numerical overflow, which introduces arithmetic errors that can degrade model accuracy. To avoid numerical overflow while maintaining accuracy, recent work proposed accumulator-aware quantization (A2Q), a quantization-aware training method that constrains model weights during training to safely use a target accumulator bit width during inference. Although this shows promise, we demonstrate that A2Q relies on an overly restrictive constraint and a sub-optimal weight initialization strategy that each introduce superfluous quantization error. To address these shortcomings, we introduce: (1) an improved bound that alleviates accumulator constraints without compromising overflow avoidance; and (2) a new strategy for initializing quantized weights from pre-trained floating-point checkpoints. We combine these contributions with weight normalization to introduce A2Q+. We support our analysis with experiments that show A2Q+ significantly improves the trade-off between accumulator bit width and model accuracy and characterize new trade-offs that arise as a consequence of accumulator constraints.
Post-Training Quantization with Low-precision Minifloats and Integers on FPGAs
Nov 21, 2023



Post-Training Quantization (PTQ) is a powerful technique for model compression, reducing the precision of neural networks without additional training overhead. Recent works have investigated adopting 8-bit floating-point quantization (FP8) in the context of PTQ for model inference. However, the exploration of floating-point formats smaller than 8 bits and their comparison with integer quantization remains relatively limited. In this work, we present minifloats, which are reduced-precision floating-point formats capable of further reducing the memory footprint, latency, and energy cost of a model while approaching full-precision model accuracy. Our work presents a novel PTQ design-space exploration, comparing minifloat and integer quantization schemes across a range of 3 to 8 bits for both weights and activations. We examine the applicability of various PTQ techniques to minifloats, including weight equalization, bias correction, SmoothQuant, gradient-based learned rounding, and the GPTQ method. Our experiments validate the effectiveness of low-precision minifloats when compared to their integer counterparts across a spectrum of accuracy-precision trade-offs on a set of reference deep learning vision workloads. Finally, we evaluate our results against an FPGA-based hardware cost model, showing that integer quantization often remains the Pareto-optimal option, given its relatively smaller hardware resource footprint.
A2Q: Accumulator-Aware Quantization with Guaranteed Overflow Avoidance
Aug 25, 2023We present accumulator-aware quantization (A2Q), a novel weight quantization method designed to train quantized neural networks (QNNs) to avoid overflow when using low-precision accumulators during inference. A2Q introduces a unique formulation inspired by weight normalization that constrains the L1-norm of model weights according to accumulator bit width bounds that we derive. Thus, in training QNNs for low-precision accumulation, A2Q also inherently promotes unstructured weight sparsity to guarantee overflow avoidance. We apply our method to deep learning-based computer vision tasks to show that A2Q can train QNNs for low-precision accumulators while maintaining model accuracy competitive with a floating-point baseline. In our evaluations, we consider the impact of A2Q on both general-purpose platforms and programmable hardware. However, we primarily target model deployment on FPGAs because they can be programmed to fully exploit custom accumulator bit widths. Our experimentation shows accumulator bit width significantly impacts the resource efficiency of FPGA-based accelerators. On average across our benchmarks, A2Q offers up to a 2.3x reduction in resource utilization over 32-bit accumulator counterparts with 99.2% of the floating-point model accuracy.
Quantized Neural Networks for Low-Precision Accumulation with Guaranteed Overflow Avoidance
Jan 31, 2023We introduce a quantization-aware training algorithm that guarantees avoiding numerical overflow when reducing the precision of accumulators during inference. We leverage weight normalization as a means of constraining parameters during training using accumulator bit width bounds that we derive. We evaluate our algorithm across multiple quantized models that we train for different tasks, showing that our approach can reduce the precision of accumulators while maintaining model accuracy with respect to a floating-point baseline. We then show that this reduction translates to increased design efficiency for custom FPGA-based accelerators. Finally, we show that our algorithm not only constrains weights to fit into an accumulator of user-defined bit width, but also increases the sparsity and compressibility of the resulting weights. Across all of our benchmark models trained with 8-bit weights and activations, we observe that constraining the hidden layers of quantized neural networks to fit into 16-bit accumulators yields an average 98.2% sparsity with an estimated compression rate of 46.5x all while maintaining 99.2% of the floating-point performance.
QONNX: Representing Arbitrary-Precision Quantized Neural Networks
Jun 17, 2022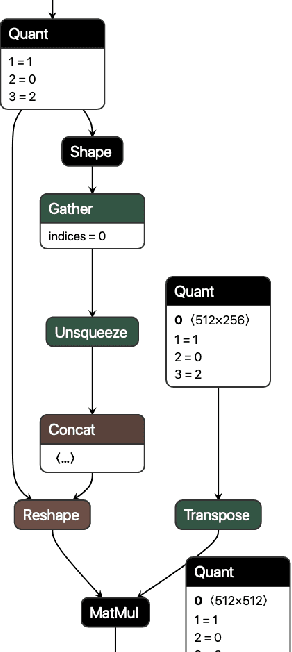
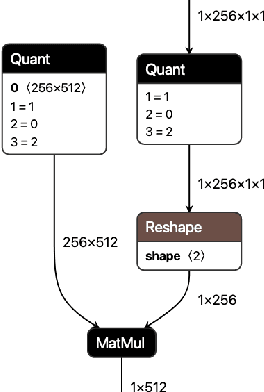
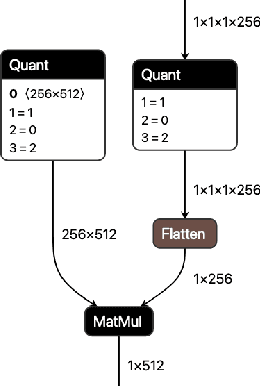
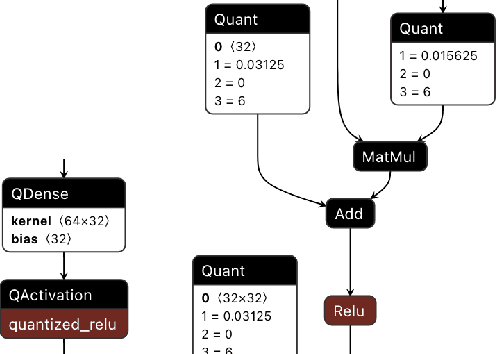
We present extensions to the Open Neural Network Exchange (ONNX) intermediate representation format to represent arbitrary-precision quantized neural networks. We first introduce support for low precision quantization in existing ONNX-based quantization formats by leveraging integer clipping, resulting in two new backward-compatible variants: the quantized operator format with clipping and quantize-clip-dequantize (QCDQ) format. We then introduce a novel higher-level ONNX format called quantized ONNX (QONNX) that introduces three new operators -- Quant, BipolarQuant, and Trunc -- in order to represent uniform quantization. By keeping the QONNX IR high-level and flexible, we enable targeting a wider variety of platforms. We also present utilities for working with QONNX, as well as examples of its usage in the FINN and hls4ml toolchains. Finally, we introduce the QONNX model zoo to share low-precision quantized neural networks.
Ps and Qs: Quantization-aware pruning for efficient low latency neural network inference
Feb 22, 2021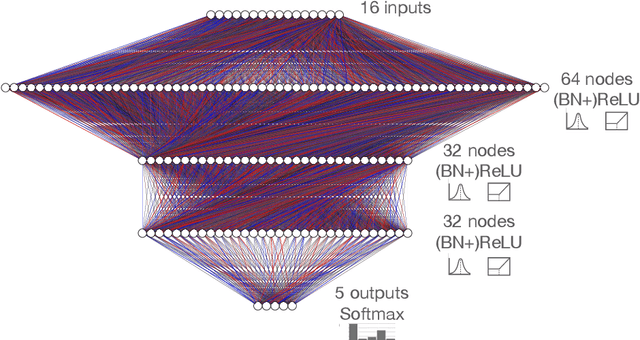

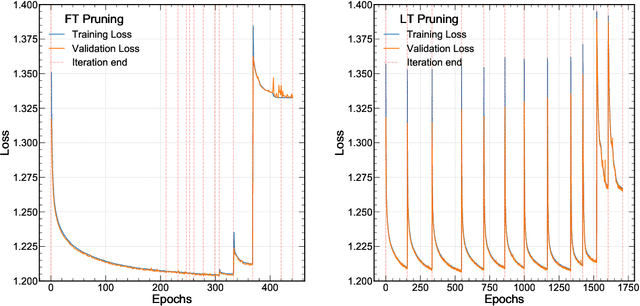
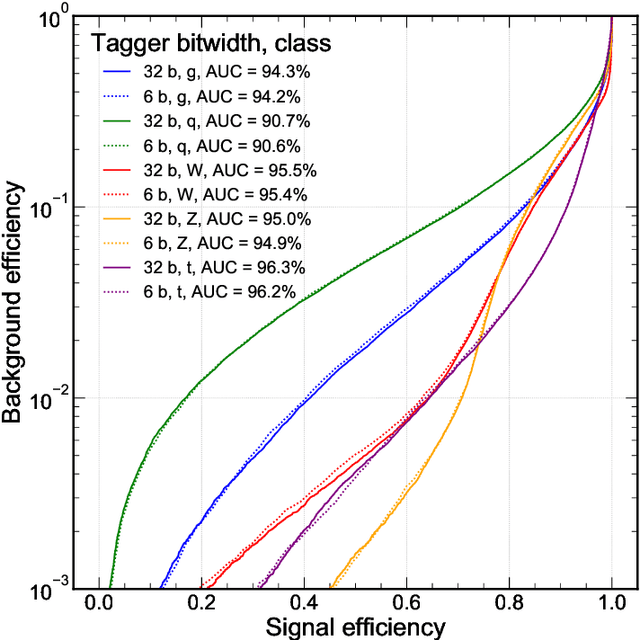
Efficient machine learning implementations optimized for inference in hardware have wide-ranging benefits depending on the application from lower inference latencies to higher data throughputs to more efficient energy consumption. Two popular techniques for reducing computation in neural networks are pruning, removing insignificant synapses, and quantization, reducing the precision of the calculations. In this work, we explore the interplay between pruning and quantization during the training of neural networks for ultra low latency applications targeting high energy physics use cases. However, techniques developed for this study have potential application across many other domains. We study various configurations of pruning during quantization-aware training, which we term \emph{quantization-aware pruning} and the effect of techniques like regularization, batch normalization, and different pruning schemes on multiple computational or neural efficiency metrics. We find that quantization-aware pruning yields more computationally efficient models than either pruning or quantization alone for our task. Further, quantization-aware pruning typically performs similar to or better in terms of computational efficiency compared to standard neural architecture optimization techniques. While the accuracy for the benchmark application may be similar, the information content of the network can vary significantly based on the training configuration.
FINN-L: Library Extensions and Design Trade-off Analysis for Variable Precision LSTM Networks on FPGAs
Jul 11, 2018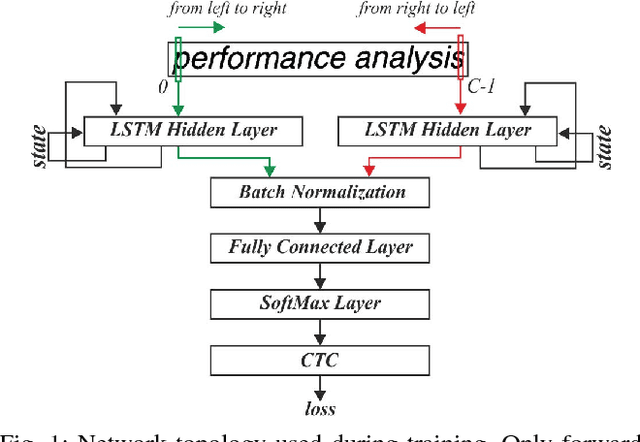
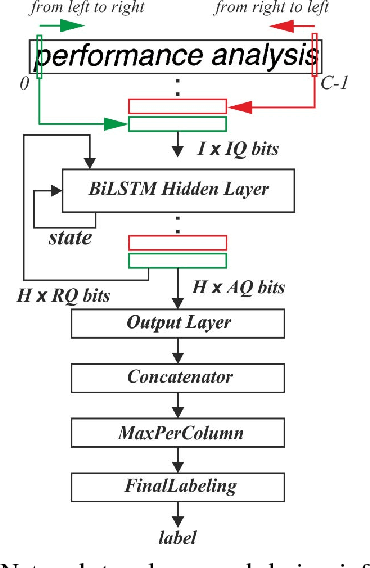
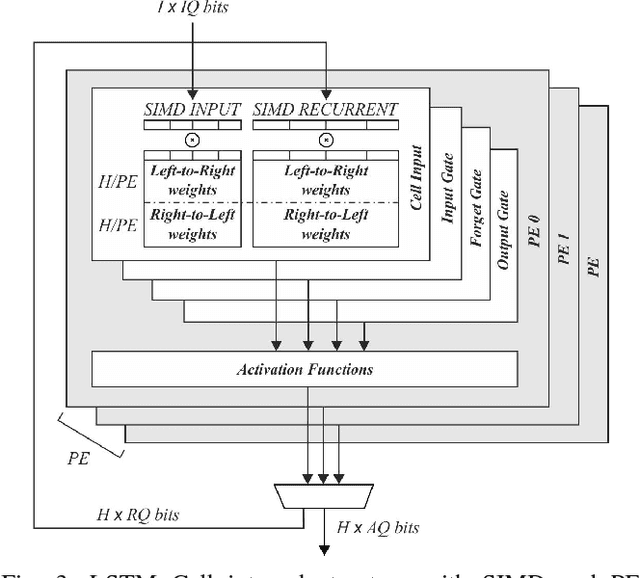
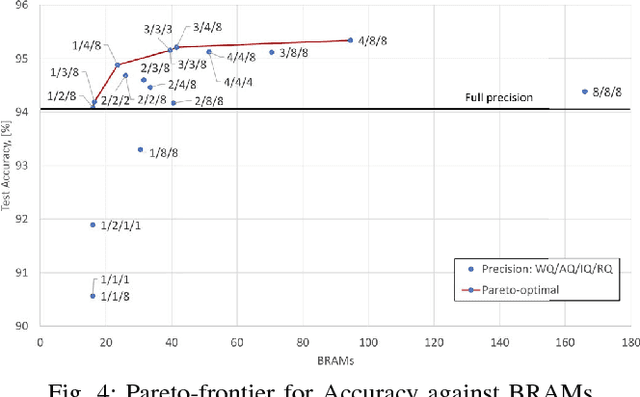
It is well known that many types of artificial neural networks, including recurrent networks, can achieve a high classification accuracy even with low-precision weights and activations. The reduction in precision generally yields much more efficient hardware implementations in regards to hardware cost, memory requirements, energy, and achievable throughput. In this paper, we present the first systematic exploration of this design space as a function of precision for Bidirectional Long Short-Term Memory (BiLSTM) neural network. Specifically, we include an in-depth investigation of precision vs. accuracy using a fully hardware-aware training flow, where during training quantization of all aspects of the network including weights, input, output and in-memory cell activations are taken into consideration. In addition, hardware resource cost, power consumption and throughput scalability are explored as a function of precision for FPGA-based implementations of BiLSTM, and multiple approaches of parallelizing the hardware. We provide the first open source HLS library extension of FINN for parameterizable hardware architectures of LSTM layers on FPGAs which offers full precision flexibility and allows for parameterizable performance scaling offering different levels of parallelism within the architecture. Based on this library, we present an FPGA-based accelerator for BiLSTM neural network designed for optical character recognition, along with numerous other experimental proof points for a Zynq UltraScale+ XCZU7EV MPSoC within the given design space.