 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Unified Coding Scheme for 6G
Mar 24, 2026The growing demand for higher data rates necessitates continuous innovations in wireless communication systems, particularly with the emergence of 6G. Channel coding plays a crucial role in this evolution. In 5G systems, rate-adaptive raptor-like quasi-cyclic irregular low-density parity-check codes are used for the data link, while polar codes with successive cancellation list decoding handle short messages on the synchronization channel. However, to meet the stringent requirements of future 6G systems, a versatile and unified coding scheme should be developed - one that offers competitive error-correcting performance alongside low complexity encoding and decoding schemes that enable energy-efficient hardware implementations. This white paper outlines the vision for such a unified coding scheme. We explore various 6G communication scenarios that pose new challenges to channel coding and provide a first analysis of potential solutions.
Security Risks in Machining Process Monitoring: Sequence-to-Sequence Learning for Reconstruction of CNC Axis Positions
Mar 02, 2026Accelerometer-based process monitoring is widely deployed in modern machining systems. When mounted on moving machine components, such sensors implicitly capture kinematic information related to machine motion and tool trajectories. If this information can be reconstructed, condition monitoring data constitutes a severe security threat, particularly for retrofitted or weakly protected sensor systems. Classical signal processing approaches are infeasible for position reconstruction from broadband accelerometer signals due to sensor- and process-specific non-idealities, like noise or sensor placement effects. In this work, we demonstrate that sequence-to-sequence machine learning models can overcome these non-idealities and enable reconstruction of CNC axis and tool positions. Our approach employs LSTM-based sequence-to-sequence models and is evaluated on an industrial milling dataset. We show that learning-based models reduce the reconstruction error by up to 98% for low complexity motion profiles and by up to 85% for complex machining sequences compared to double integration. Furthermore, key geometric characteristics of tool trajectories and workpiece-related motion features are preserved. To the best of our knowledge, this is the first study demonstrating learning-based CNC position reconstruction from industrial condition monitoring accelerometer data.
CRADLE: Conversational RTL Design Space Exploration with LLM-based Multi-Agent Systems
Aug 12, 2025This paper presents CRADLE, a conversational framework for design space exploration of RTL designs using LLM-based multi-agent systems. Unlike existing rigid approaches, CRADLE enables user-guided flows with internal self-verification, correction, and optimization. We demonstrate the framework with a generator-critic agent system targeting FPGA resource minimization using state-of-the-art LLMs. Experimental results on the RTLLM benchmark show that CRADLE achieves significant reductions in resource usage with averages of 48% and 40% in LUTs and FFs across all benchmark designs.
Smart Environmental Monitoring of Marine Pollution using Edge AI
Apr 30, 2025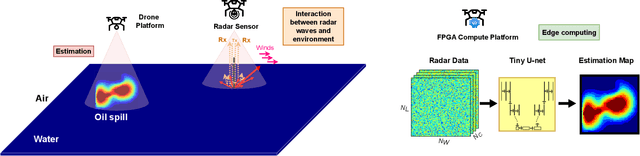
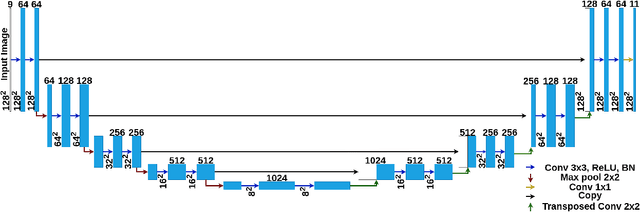
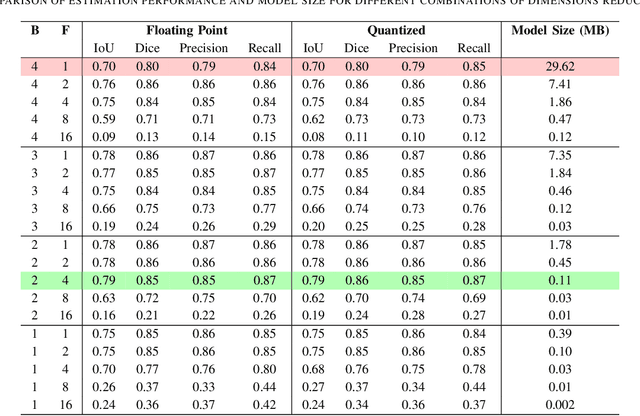

Oil spill incidents pose severe threats to marine ecosystems and coastal environments, necessitating rapid detection and monitoring capabilities to mitigate environmental damage. In this paper, we demonstrate how artificial intelligence, despite the inherent high computational and memory requirements, can be efficiently integrated into marine pollution monitoring systems. More precisely, we propose a drone-based smart monitoring system leveraging a compressed deep learning U-Net architecture for oil spill detection and thickness estimation. Compared to the standard U-Net architecture, the number of convolution blocks and channels per block are modified. The new model is then trained on synthetic radar data to accurately predict thick oil slick thickness up to 10 mm. Results show that our optimized Tiny U-Net achieves superior performance with an Intersection over Union (IoU) metric of approximately 79%, while simultaneously reducing the model size by a factor of $\sim$269x compared to the state-of-the-art. This significant model compression enables efficient edge computing deployment on field-programmable gate array (FPGA) hardware integrated directly into the drone platform. Hardware implementation demonstrates near real-time thickness estimation capabilities with a run-time power consumption of approximately 2.2 watts. Our findings highlight the increasing potential of smart monitoring technologies and efficient edge computing for operational characterization in marine environments.
ECNN: A Low-complex, Adjustable CNN for Industrial Pump Monitoring Using Vibration Data
Mar 10, 2025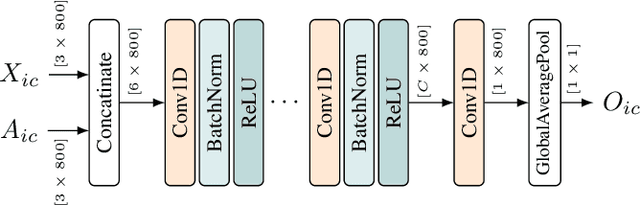
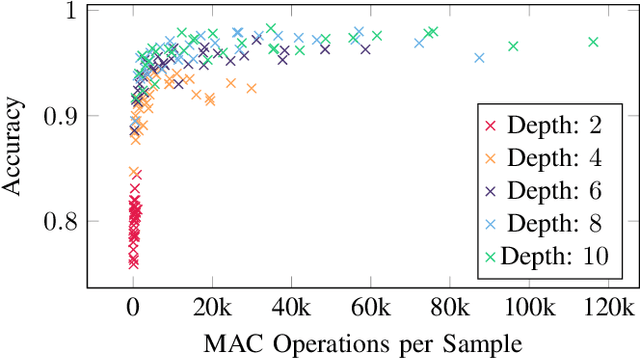
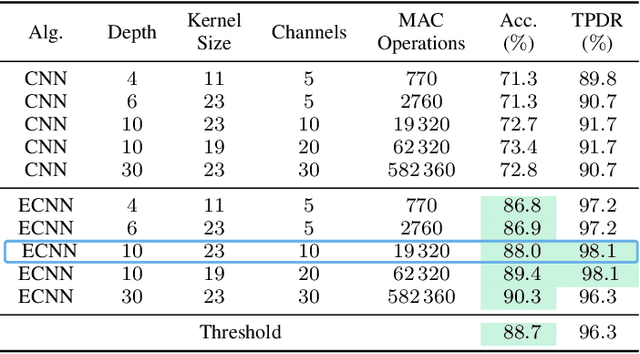

Industrial pumps are essential components in various sectors, such as manufacturing, energy production, and water treatment, where their failures can cause significant financial and safety risks. Anomaly detection can be used to reduce those risks and increase reliability. In this work, we propose a novel enhanced convolutional neural network (ECNN) to predict the failure of an industrial pump based on the vibration data captured by an acceleration sensor. The convolutional neural network (CNN) is designed with a focus on low complexity to enable its implementation on edge devices with limited computational resources. Therefore, a detailed design space exploration is performed to find a topology satisfying the trade-off between complexity and accuracy. Moreover, to allow for adaptation to unknown pumps, our algorithm features a pump-specific parameter that can be determined by a small set of normal data samples. Finally, we combine the ECNN with a threshold approach to further increase the performance and satisfy the application requirements. As a result, our combined approach significantly outperforms a traditional statistical approach and a classical CNN in terms of accuracy. To summarize, this work provides a novel, low-complex, CNN-based algorithm that is enhanced by classical methods to offer high accuracy for anomaly detection of industrial pumps.
Recent Advances on Machine Learning-aided DSP for Short-reach and Long-haul Optical Communications
Nov 15, 2024


In this paper, we highlight recent advances in the use of machine learning for implementing equalizers for optical communications. We highlight both algorithmic advances as well as implementation aspects using conventional and neuromorphic hardware.
Efficient FPGA Implementation of an Optimized SNN-based DFE for Optical Communications
Sep 13, 2024The ever-increasing demand for higher data rates in communication systems intensifies the need for advanced non-linear equalizers capable of higher performance. Recently artificial neural networks (ANNs) were introduced as a viable candidate for advanced non-linear equalizers, as they outperform traditional methods. However, they are computationally complex and therefore power hungry. Spiking neural networks (SNNs) started to gain attention as an energy-efficient alternative to ANNs. Recent works proved that they can outperform ANNs at this task. In this work, we explore the design space of an SNN-based decision-feedback equalizer (DFE) to reduce its computational complexity for an efficient implementation on field programmable gate array (FPGA). Our Results prove that it achieves higher communication performance than ANN-based DFE at roughly the same throughput and at 25X higher energy efficiency.
Achieving High Throughput with a Trainable Neural-Network-Based Equalizer for Communications on FPGA
Jul 03, 2024



The ever-increasing data rates of modern communication systems lead to severe distortions of the communication signal, imposing great challenges to state-of-the-art signal processing algorithms. In this context, neural network (NN)-based equalizers are a promising concept since they can compensate for impairments introduced by the channel. However, due to the large computational complexity, efficient hardware implementation of NNs is challenging. Especially the backpropagation algorithm, required to adapt the NN's parameters to varying channel conditions, is highly complex, limiting the throughput on resource-constrained devices like field programmable gate arrays (FPGAs). In this work, we present an FPGA architecture of an NN-based equalizer that exploits batch-level parallelism of the convolutional layer to enable a custom mapping scheme of two multiplication to a single digital signal processor (DSP). Our implementation achieves a throughput of up to 20 GBd, which enables the equalization of high-data-rate nonlinear optical fiber channels while providing adaptation capabilities by retraining the NN using backpropagation. As a result, our FPGA implementation outperforms an embedded graphics processing unit (GPU) in terms of throughput by two orders of magnitude. Further, we achieve a higher energy efficiency and throughput as state-of-the-art NN training FPGA implementations. Thus, this work fills the gap of high-throughput NN-based equalization while enabling adaptability by NN training on the edge FPGA.
CNN-Based Equalization for Communications: Achieving Gigabit Throughput with a Flexible FPGA Hardware Architecture
Apr 22, 2024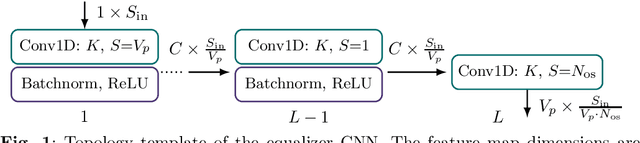

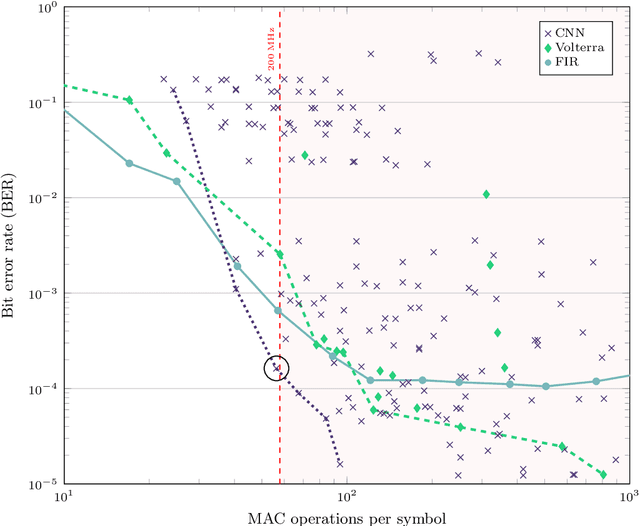
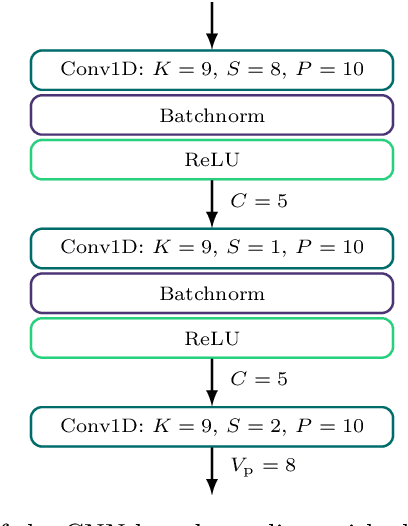
To satisfy the growing throughput demand of data-intensive applications, the performance of optical communication systems increased dramatically in recent years. With higher throughput, more advanced equalizers are crucial, to compensate for impairments caused by inter-symbol interference (ISI). The latest research shows that artificial neural network (ANN)-based equalizers are promising candidates to replace traditional algorithms for high-throughput communications. On the other hand, not only throughput but also flexibility is a main objective of beyond-5G and 6G communication systems. A platform that is able to satisfy the strict throughput and flexibility requirements of modern communication systems are field programmable gate arrays (FPGAs). Thus, in this work, we present a high-performance FPGA implementation of an ANN-based equalizer, which meets the throughput requirements of modern optical communication systems. Further, our architecture is highly flexible since it includes a variable degree of parallelism (DOP) and therefore can also be applied to low-cost or low-power applications which is demonstrated for a magnetic recording channel. The implementation is based on a cross-layer design approach featuring optimizations from the algorithm down to the hardware architecture, including a detailed quantization analysis. Moreover, we present a framework to reduce the latency of the ANN-based equalizer under given throughput constraints. As a result, the bit error ratio (BER) of our equalizer for the optical fiber channel is around four times lower than that of a conventional one, while the corresponding FPGA implementation achieves a throughput of more than 40 GBd, outperforming a high-performance graphics processing unit (GPU) by three orders of magnitude for a similar batch size.
Real-Time FPGA Demonstrator of ANN-Based Equalization for Optical Communications
Feb 23, 2024

In this work, we present a high-throughput field programmable gate array (FPGA) demonstrator of an artificial neural network (ANN)-based equalizer. The equalization is performed and illustrated in real-time for a 30 GBd, two-level pulse amplitude modulation (PAM2) optical communication system.