 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECNN: A Low-complex, Adjustable CNN for Industrial Pump Monitoring Using Vibration Data
Mar 10, 2025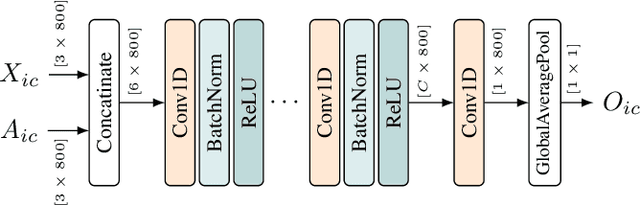
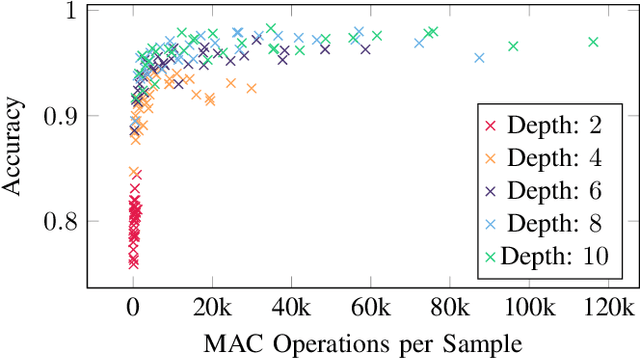
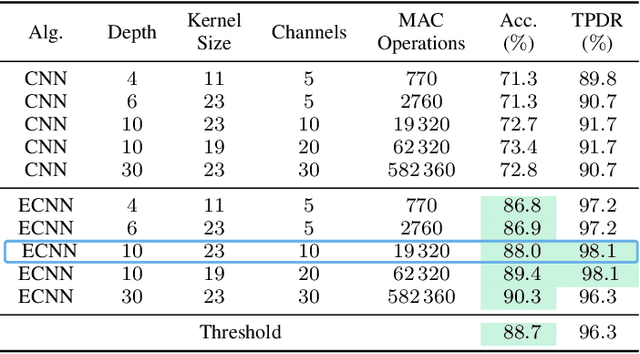

Industrial pumps are essential components in various sectors, such as manufacturing, energy production, and water treatment, where their failures can cause significant financial and safety risks. Anomaly detection can be used to reduce those risks and increase reliability. In this work, we propose a novel enhanced convolutional neural network (ECNN) to predict the failure of an industrial pump based on the vibration data captured by an acceleration sensor. The convolutional neural network (CNN) is designed with a focus on low complexity to enable its implementation on edge devices with limited computational resources. Therefore, a detailed design space exploration is performed to find a topology satisfying the trade-off between complexity and accuracy. Moreover, to allow for adaptation to unknown pumps, our algorithm features a pump-specific parameter that can be determined by a small set of normal data samples. Finally, we combine the ECNN with a threshold approach to further increase the performance and satisfy the application requirements. As a result, our combined approach significantly outperforms a traditional statistical approach and a classical CNN in terms of accuracy. To summarize, this work provides a novel, low-complex, CNN-based algorithm that is enhanced by classical methods to offer high accuracy for anomaly detection of industrial pumps.
Recent Advances on Machine Learning-aided DSP for Short-reach and Long-haul Optical Communications
Nov 15, 2024


In this paper, we highlight recent advances in the use of machine learning for implementing equalizers for optical communications. We highlight both algorithmic advances as well as implementation aspects using conventional and neuromorphic hardware.
Efficient FPGA Implementation of an Optimized SNN-based DFE for Optical Communications
Sep 13, 2024The ever-increasing demand for higher data rates in communication systems intensifies the need for advanced non-linear equalizers capable of higher performance. Recently artificial neural networks (ANNs) were introduced as a viable candidate for advanced non-linear equalizers, as they outperform traditional methods. However, they are computationally complex and therefore power hungry. Spiking neural networks (SNNs) started to gain attention as an energy-efficient alternative to ANNs. Recent works proved that they can outperform ANNs at this task. In this work, we explore the design space of an SNN-based decision-feedback equalizer (DFE) to reduce its computational complexity for an efficient implementation on field programmable gate array (FPGA). Our Results prove that it achieves higher communication performance than ANN-based DFE at roughly the same throughput and at 25X higher energy efficiency.
Achieving High Throughput with a Trainable Neural-Network-Based Equalizer for Communications on FPGA
Jul 03, 2024



The ever-increasing data rates of modern communication systems lead to severe distortions of the communication signal, imposing great challenges to state-of-the-art signal processing algorithms. In this context, neural network (NN)-based equalizers are a promising concept since they can compensate for impairments introduced by the channel. However, due to the large computational complexity, efficient hardware implementation of NNs is challenging. Especially the backpropagation algorithm, required to adapt the NN's parameters to varying channel conditions, is highly complex, limiting the throughput on resource-constrained devices like field programmable gate arrays (FPGAs). In this work, we present an FPGA architecture of an NN-based equalizer that exploits batch-level parallelism of the convolutional layer to enable a custom mapping scheme of two multiplication to a single digital signal processor (DSP). Our implementation achieves a throughput of up to 20 GBd, which enables the equalization of high-data-rate nonlinear optical fiber channels while providing adaptation capabilities by retraining the NN using backpropagation. As a result, our FPGA implementation outperforms an embedded graphics processing unit (GPU) in terms of throughput by two orders of magnitude. Further, we achieve a higher energy efficiency and throughput as state-of-the-art NN training FPGA implementations. Thus, this work fills the gap of high-throughput NN-based equalization while enabling adaptability by NN training on the edge FPGA.
CNN-Based Equalization for Communications: Achieving Gigabit Throughput with a Flexible FPGA Hardware Architecture
Apr 22, 2024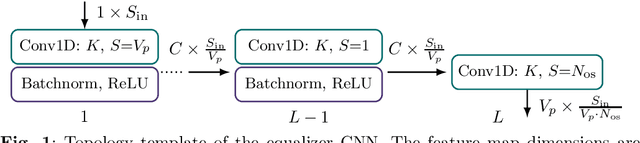

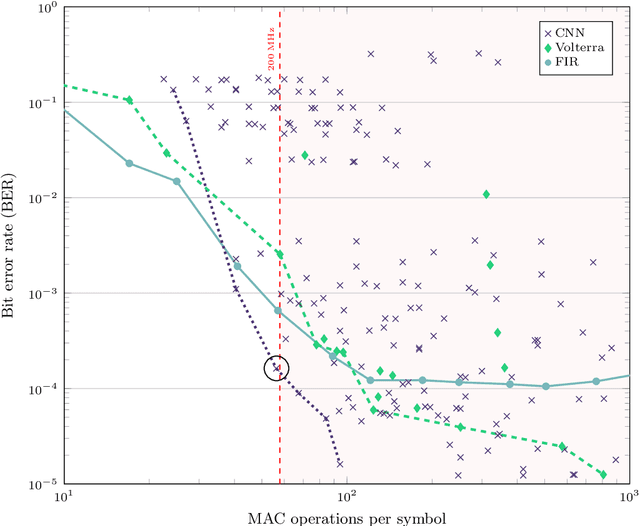
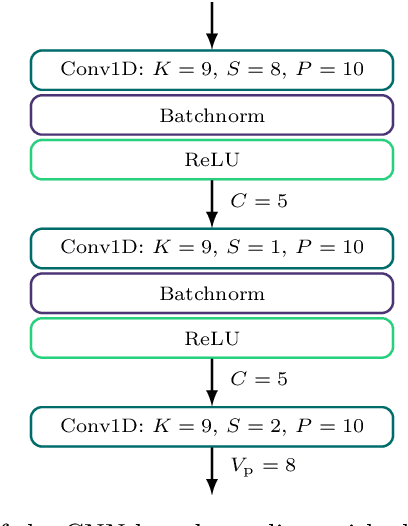
To satisfy the growing throughput demand of data-intensive applications, the performance of optical communication systems increased dramatically in recent years. With higher throughput, more advanced equalizers are crucial, to compensate for impairments caused by inter-symbol interference (ISI). The latest research shows that artificial neural network (ANN)-based equalizers are promising candidates to replace traditional algorithms for high-throughput communications. On the other hand, not only throughput but also flexibility is a main objective of beyond-5G and 6G communication systems. A platform that is able to satisfy the strict throughput and flexibility requirements of modern communication systems are field programmable gate arrays (FPGAs). Thus, in this work, we present a high-performance FPGA implementation of an ANN-based equalizer, which meets the throughput requirements of modern optical communication systems. Further, our architecture is highly flexible since it includes a variable degree of parallelism (DOP) and therefore can also be applied to low-cost or low-power applications which is demonstrated for a magnetic recording channel. The implementation is based on a cross-layer design approach featuring optimizations from the algorithm down to the hardware architecture, including a detailed quantization analysis. Moreover, we present a framework to reduce the latency of the ANN-based equalizer under given throughput constraints. As a result, the bit error ratio (BER) of our equalizer for the optical fiber channel is around four times lower than that of a conventional one, while the corresponding FPGA implementation achieves a throughput of more than 40 GBd, outperforming a high-performance graphics processing unit (GPU) by three orders of magnitude for a similar batch size.
Real-Time FPGA Demonstrator of ANN-Based Equalization for Optical Communications
Feb 23, 2024

In this work, we present a high-throughput field programmable gate array (FPGA) demonstrator of an artificial neural network (ANN)-based equalizer. The equalization is performed and illustrated in real-time for a 30 GBd, two-level pulse amplitude modulation (PAM2) optical communication system.
Fully-blind Neural Network Based Equalization for Severe Nonlinear Distortions in 112 Gbit/s Passive Optical Networks
Jan 17, 2024



We demonstrate and evaluate a fully-blind digital signal processing (DSP) chain for 100G passive optical networks (PONs), and analyze different equalizer topologies based on neural networks with low hardware complexity.
Unsupervised ANN-Based Equalizer and Its Trainable FPGA Implementation
Apr 14, 2023



In recent years, communication engineers put strong emphasis on artificial neural network (ANN)-based algorithms with the aim of increasing the flexibility and autonomy of the system and its components. In this context, unsupervised training is of special interest as it enables adaptation without the overhead of transmitting pilot symbols. In this work, we present a novel ANN-based, unsupervised equalizer and its trainable field programmable gate array (FPGA) implementation. We demonstrate that our custom loss function allows the ANN to adapt for varying channel conditions, approaching the performance of a supervised baseline. Furthermore, as a first step towards a practical communication system, we design an efficient FPGA implementation of our proposed algorithm, which achieves a throughput in the order of Gbit/s, outperforming a high-performance GPU by a large margin.
A Hybrid Approach combining ANN-based and Conventional Demapping in Communication for Efficient FPGA-Implementation
Apr 11, 2023In communication systems, Autoencoder (AE) refers to the concept of replacing parts of the transmitter and receiver by artificial neural networks (ANNs) to train the system end-to-end over a channel model. This approach aims to improve communication performance, especially for varying channel conditions, with the cost of high computational complexity for training and inference. Field-programmable gate arrays (FPGAs) have been shown to be a suitable platform for energy-efficient ANN implementation. However, the high number of operations and the large model size of ANNs limit the performance on resource-constrained devices, which is critical for low latency and high-throughput communication systems. To tackle his challenge, we propose a novel approach for efficient ANN-based remapping on FPGAs, which combines the adaptability of the AE with the efficiency of conventional demapping algorithms. After adaption to channel conditions, the channel characteristics, implicitly learned by the ANN, are extracted to enable the use of optimized conventional demapping algorithms for inference. We validate the hardware efficiency of our approach by providing FPGA implementation results and by comparing the communication performance to that of conventional systems. Our work opens a door for the practical application of ANN-based communication algorithms on FPGAs.
* Available at: https://ieeexplore.ieee.org/document/9835699
Blind and Channel-agnostic Equalization Using Adversarial Networks
Sep 15, 2022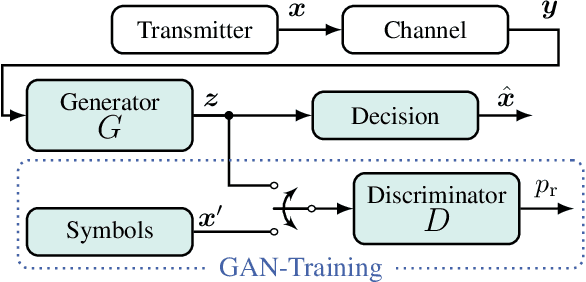
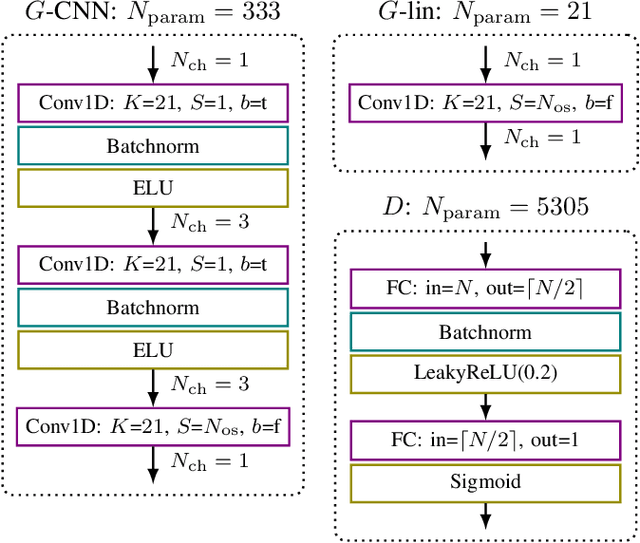
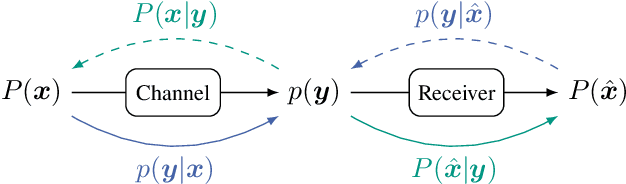
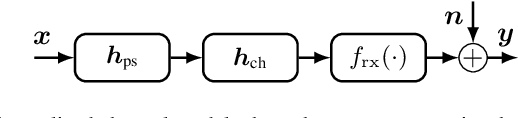
Due to the rapid development of autonomous driving, the Internet of Things and streaming services, modern communication systems have to cope with varying channel conditions and a steadily rising number of users and devices. This, and the still rising bandwidth demands, can only be met by intelligent network automation, which requires highly flexible and blind transceiver algorithms. To tackle those challenges, we propose a novel adaptive equalization scheme, which exploits the prosperous advances in deep learning by training an equalizer with an adversarial network. The learning is only based on the statistics of the transmit signal, so it is blind regarding the actual transmit symbols and agnostic to the channel model. The proposed approach is independent of the equalizer topology and enables the application of powerful neural network based equalizers. In this work, we prove this concept in simulations of different -- both linear and nonlinear -- transmission channels and demonstrate the capability of the proposed blind learning scheme to approach the performance of non-blind equalizers. Furthermore, we provide a theoretical perspective and highlight the challenges of the approach.