 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFINN-L: Library Extensions and Design Trade-off Analysis for Variable Precision LSTM Networks on FPGAs
Jul 11, 2018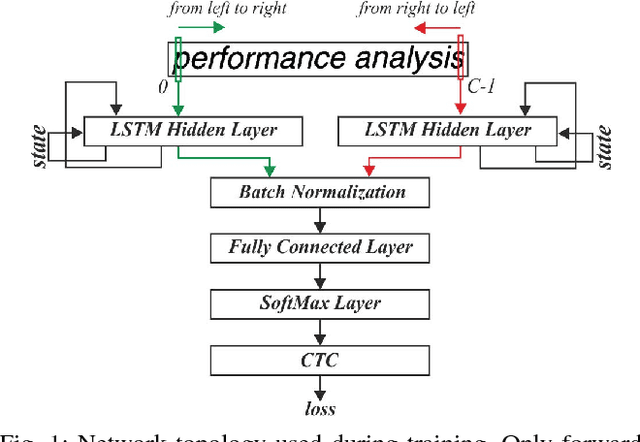
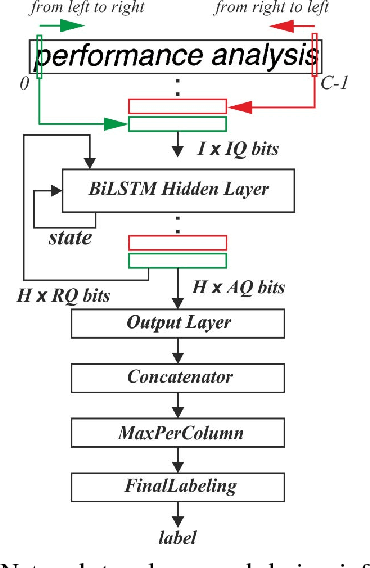
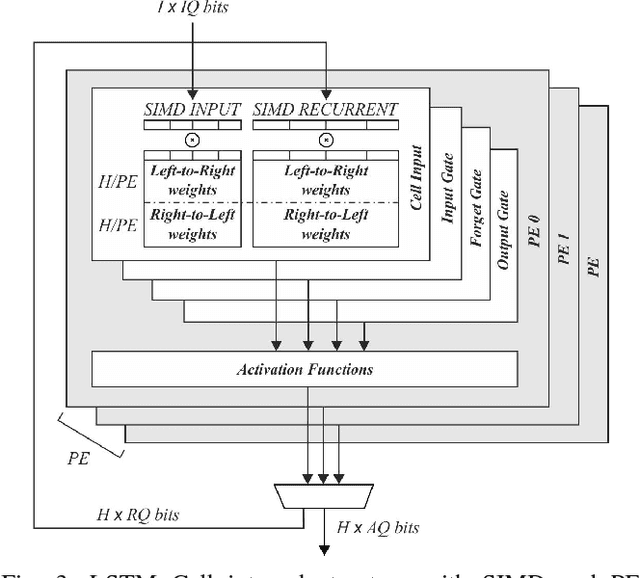
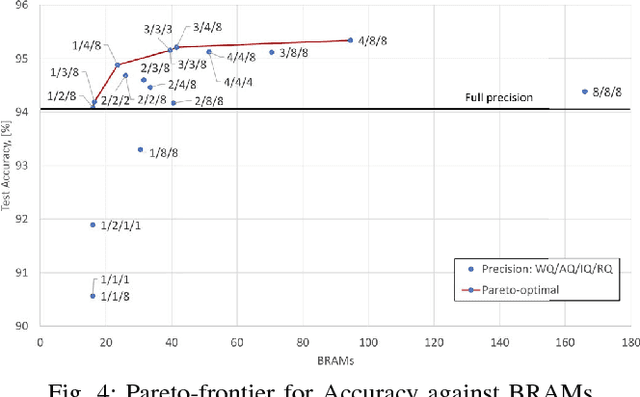
It is well known that many types of artificial neural networks, including recurrent networks, can achieve a high classification accuracy even with low-precision weights and activations. The reduction in precision generally yields much more efficient hardware implementations in regards to hardware cost, memory requirements, energy, and achievable throughput. In this paper, we present the first systematic exploration of this design space as a function of precision for Bidirectional Long Short-Term Memory (BiLSTM) neural network. Specifically, we include an in-depth investigation of precision vs. accuracy using a fully hardware-aware training flow, where during training quantization of all aspects of the network including weights, input, output and in-memory cell activations are taken into consideration. In addition, hardware resource cost, power consumption and throughput scalability are explored as a function of precision for FPGA-based implementations of BiLSTM, and multiple approaches of parallelizing the hardware. We provide the first open source HLS library extension of FINN for parameterizable hardware architectures of LSTM layers on FPGAs which offers full precision flexibility and allows for parameterizable performance scaling offering different levels of parallelism within the architecture. Based on this library, we present an FPGA-based accelerator for BiLSTM neural network designed for optical character recognition, along with numerous other experimental proof points for a Zynq UltraScale+ XCZU7EV MPSoC within the given design space.