 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Cross-Modal Retrieval with Missing Modalities via Semantic Routing and Adapter Personalization
Apr 24, 2026Federated cross-modal retrieval faces severe challenges from heterogeneous client data, particularly non-IID semantic distributions and missing modalities. Under such heterogeneity, a single global model is often insufficient to capture both shared cross-modal knowledge and client-specific characteristics. We propose RCSR, a personalization-friendly federated framework that integrates prototype anchoring, retrieval-centric semantic routing, and optional client-specific adapters. Built on a frozen CLIP backbone, RCSR leverages lightweight shared adapters for global knowledge transfer while supporting efficient local personalization. Prototype anchoring helps unimodal clients align with global cross-modal semantics, and a server-side semantic router adaptively assigns aggregation weights based on retrieval consistency to mitigate alignment drift during heterogeneous updates. Extensive experiments on MS-COCO, Flickr30K, and other benchmarks show that RCSR consistently improves global retrieval accuracy and training stability, while further enhancing client-level retrieval performance, especially for clients with incomplete modalities. Code is available at https://github.com/RezinChow/RCSR-Retrieval-Centric-Semantic-Routing.
On the Robustness of Deep Learning-aided Symbol Detectors to Varying Conditions and Imperfect Channel Knowledge
Jan 23, 2024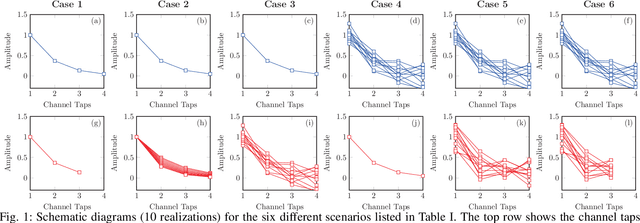
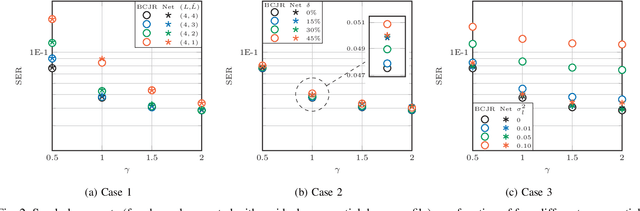
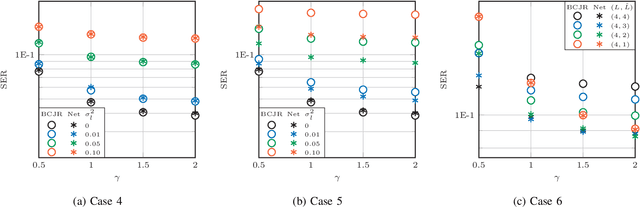

Recently, a data-driven Bahl-Cocke-Jelinek-Raviv (BCJR) algorithm tailored to channels with intersymbol interference has been introduced. This so-called BCJRNet algorithm utilizes neural networks to calculate channel likelihoods. BCJRNet has demonstrated resilience against inaccurate channel tap estimations when applied to a time-invariant channel with ideal exponential decay profiles. However, its generalization capabilities for practically-relevant time-varying channels, where the receiver can only access incorrect channel parameters, remain largely unexplored. The primary contribution of this paper is to expand upon the results from existing literature to encompass a variety of imperfect channel knowledge cases that appear in real-world transmissions. Our findings demonstrate that BCJRNet significantly outperforms the conventional BCJR algorithm for stationary transmission scenarios when learning from noisy channel data and with imperfect channel decay profiles. However, this advantage is shown to diminish when the operating channel is also rapidly time-varying. Our results also show the importance of memory assumptions for conventional BCJR and BCJRNet. An underestimation of the memory largely degrades the performance of both BCJR and BCJRNet, especially in a slow-decaying channel. To mimic a situation closer to a practical scenario, we also combined channel tap uncertainty with imperfect channel memory knowledge. Somewhat surprisingly, our results revealed improved performance when employing the conventional BCJR with an underestimated memory assumption. BCJRNet, on the other hand, showed a consistent performance improvement as the level of accurate memory knowledge increased.
Visual-Policy Learning through Multi-Camera View to Single-Camera View Knowledge Distillation for Robot Manipulation Tasks
Mar 13, 2023The use of multi-camera views simultaneously has been shown to improve the generalization capabilities and performance of visual policies. However, the hardware cost and design constraints in real-world scenarios can potentially make it challenging to use multiple cameras. In this study, we present a novel approach to enhance the generalization performance of vision-based Reinforcement Learning (RL) algorithms for robotic manipulation tasks. Our proposed method involves utilizing a technique known as knowledge distillation, in which a pre-trained ``teacher'' policy trained with multiple camera viewpoints guides a ``student'' policy in learning from a single camera viewpoint. To enhance the student policy's robustness against camera location perturbations, it is trained using data augmentation and extreme viewpoint changes. As a result, the student policy learns robust visual features that allow it to locate the object of interest accurately and consistently, regardless of the camera viewpoint. The efficacy and efficiency of the proposed method were evaluated both in simulation and real-world environments. The results demonstrate that the single-view visual student policy can successfully learn to grasp and lift a challenging object, which was not possible with a single-view policy alone. Furthermore, the student policy demonstrates zero-shot transfer capability, where it can successfully grasp and lift objects in real-world scenarios for unseen visual configurations.
Inferring the Geometric Nullspace of Robot Skills from Human Demonstrations
Mar 30, 2021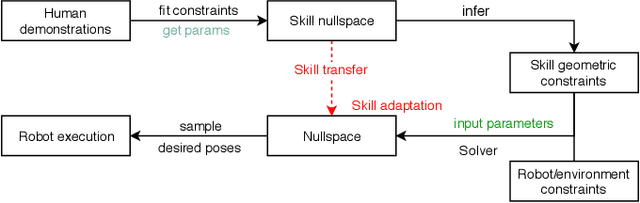
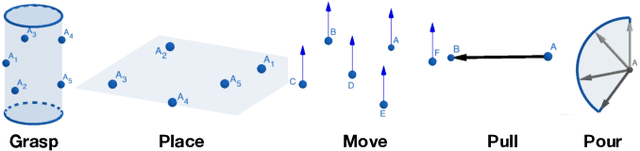


In this paper we present a framework to learn skills from human demonstrations in the form of geometric nullspaces, which can be executed using a robot. We collect data of human demonstrations, fit geometric nullspaces to them, and also infer their corresponding geometric constraint models. These geometric constraints provide a powerful mathematical model as well as an intuitive representation of the skill in terms of the involved objects. To execute the skill using a robot, we combine this geometric skill description with the robot's kinematics and other environmental constraints, from which poses can be sampled for the robot's execution. The result of our framework is a system that takes the human demonstrations as input, learns the underlying skill model, and executes the learnt skill with different robots in different dynamic environments. We evaluate our approach on a simulated industrial robot, and execute the final task on the iCub humanoid robot.
* 8 pages, 6 figures, ICRA 2020