 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study of Implicit and Explicit Biases in Large Language Models
Nov 18, 2025Large Language Models (LLMs) inherit explicit and implicit biases from their training datasets. Identifying and mitigating biases in LLMs is crucial to ensure fair outputs, as they can perpetuate harmful stereotypes and misinformation. This study highlights the need to address biases in LLMs amid growing generative AI. We studied bias-specific benchmarks such as StereoSet and CrowSPairs to evaluate the existence of various biases in multiple generative models such as BERT and GPT 3.5. We proposed an automated Bias-Identification Framework to recognize various social biases in LLMs such as gender, race, profession, and religion. We adopted a two-pronged approach to detect explicit and implicit biases in text data. Results indicated fine-tuned models struggle with gender biases but excelled at identifying and avoiding racial biases. Our findings illustrated that despite having some success, LLMs often over-relied on keywords. To illuminate the capability of the analyzed LLMs in detecting implicit biases, we employed Bag-of-Words analysis and unveiled indications of implicit stereotyping within the vocabulary. To bolster the model performance, we applied an enhancement strategy involving fine-tuning models using prompting techniques and data augmentation of the bias benchmarks. The fine-tuned models exhibited promising adaptability during cross-dataset testing and significantly enhanced performance on implicit bias benchmarks, with performance gains of up to 20%.
Hybrid Real- and Complex-valued Neural Network Architecture
Apr 04, 2025We propose a \emph{hybrid} real- and complex-valued \emph{neural network} (HNN) architecture, designed to combine the computational efficiency of real-valued processing with the ability to effectively handle complex-valued data. We illustrate the limitations of using real-valued neural networks (RVNNs) for inherently complex-valued problems by showing how it learnt to perform complex-valued convolution, but with notable inefficiencies stemming from its real-valued constraints. To create the HNN, we propose to use building blocks containing both real- and complex-valued paths, where information between domains is exchanged through domain conversion functions. We also introduce novel complex-valued activation functions, with higher generalisation and parameterisation efficiency. HNN-specific architecture search techniques are described to navigate the larger solution space. Experiments with the AudioMNIST dataset demonstrate that the HNN reduces cross-entropy loss and consumes less parameters compared to an RVNN for all considered cases. Such results highlight the potential for the use of partially complex-valued processing in neural networks and applications for HNNs in many signal processing domains.
Target Speaker Selection for Neural Network Beamforming in Multi-Speaker Scenarios
Mar 24, 2025



We propose a speaker selection mechanism (SSM) for the training of an end-to-end beamforming neural network, based on recent findings that a listener usually looks to the target speaker with a certain undershot angle. The mechanism allows the neural network model to learn toward which speaker to focus, during training, in a multi-speaker scenario, based on the position of listener and speakers. However, only audio information is necessary during inference. We perform acoustic simulations demonstrating the feasibility and performance when the SSM is employed in training. The results show significant increase in speech intelligibility, quality, and distortion metrics when compared to the minimum variance distortionless filter and the same neural network model trained without SSM. The success of the proposed method is a significant step forward toward the solution of the cocktail party problem.
Analysis of Impulsive Interference in Digital Audio Broadcasting Systems in Electric Vehicles
May 17, 2024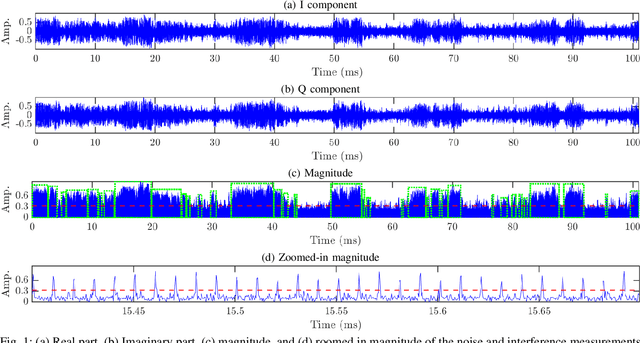
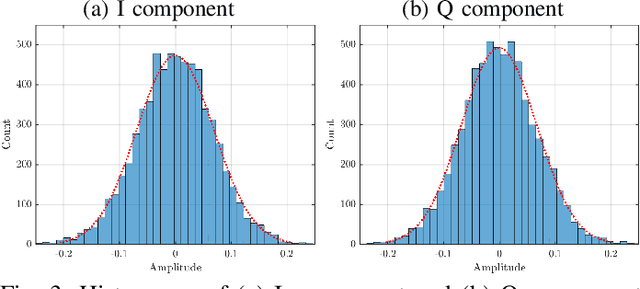
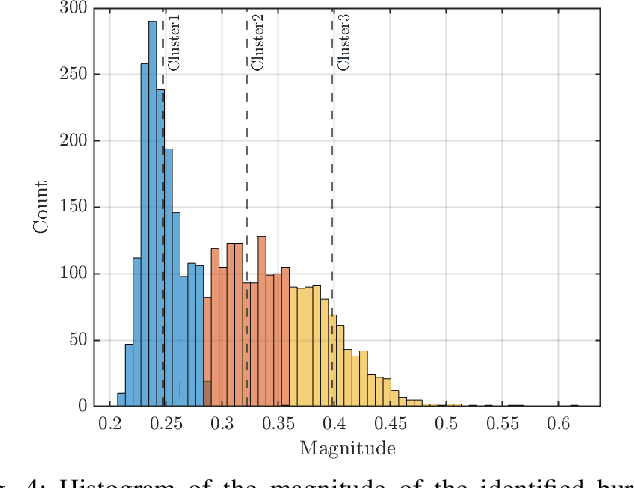
Recently, new types of interference in electric vehicles (EVs), such as converters switching and/or battery chargers, have been found to degrade the performance of wireless digital transmission systems. Measurements show that such an interference is characterized by impulsive behavior and is widely varying in time. This paper uses recorded data from our EV testbed to analyze the impulsive interference in the digital audio broadcasting band. Moreover, we use our analysis to obtain a corresponding interference model. In particular, we studied the temporal characteristics of the interference and confirmed that its amplitude indeed exhibits an impulsive behavior. Our results show that impulsive events span successive received signal samples and thus indicate a bursty nature. To this end, we performed a data-driven modification of a well-established model for bursty impulsive interference, the Markov-Middleton model, to produce synthetic noise realization. We investigate the optimal symbol detector design based on the proposed model and show significant performance gains compared to the conventional detector based on the additive white Gaussian noise assumption.
Data-Driven Symbol Detection for Intersymbol Interference Channels with Bursty Impulsive Noise
May 17, 2024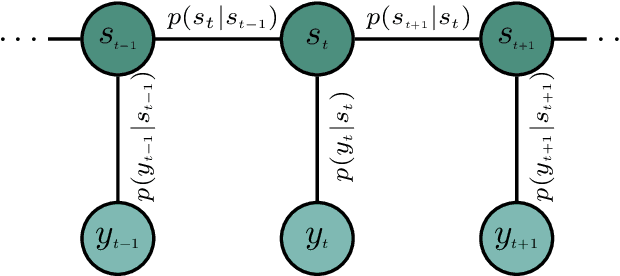
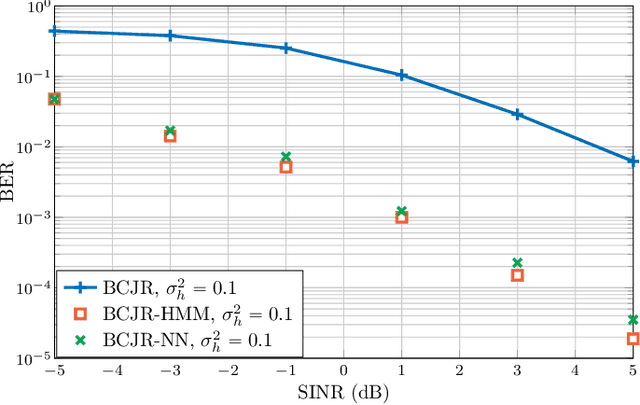
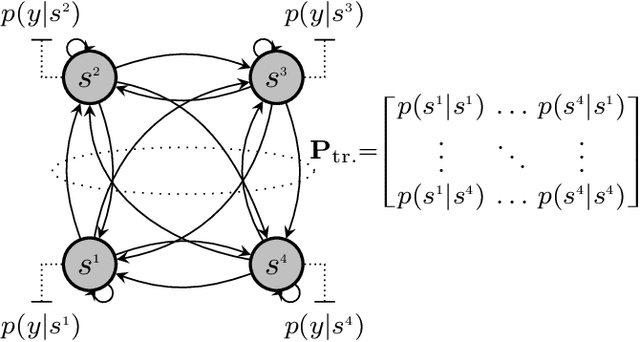
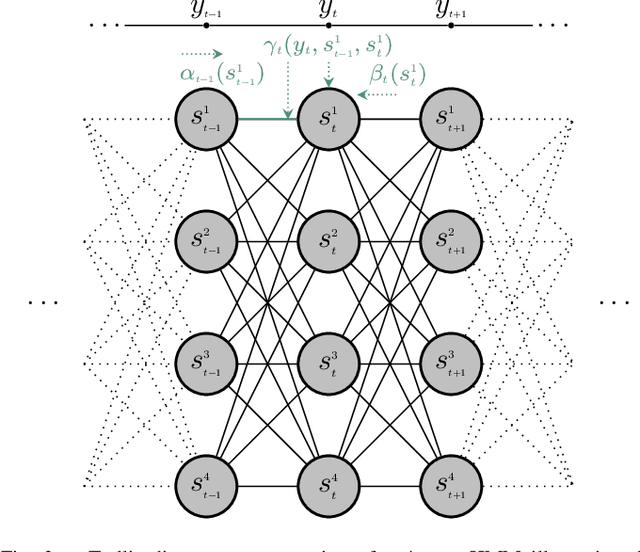
We developed machine learning approaches for data-driven trellis-based soft symbol detection in coded transmission over intersymbol interference (ISI) channels in presence of bursty impulsive noise (IN), for example encountered in wireless digital broadcasting systems and vehicular communications. This enabled us to obtain optimized detectors based on the Bahl-Cocke-Jelinek-Raviv (BCJR) algorithm while circumventing the use of full channel state information (CSI) for computing likelihoods and trellis state transition probabilities. First, we extended the application of the neural network (NN)-aided BCJR, recently proposed for ISI channels with additive white Gaussian noise (AWGN). Although suitable for estimating likelihoods via labeling of transmission sequences, the BCJR-NN method does not provide a framework for learning the trellis state transitions. In addition to detection over the joint ISI and IN states we also focused on another scenario where trellis transitions are not trivial: detection for the ISI channel with AWGN with inaccurate knowledge of the channel memory at the receiver. Without access to the accurate state transition matrix, the BCJR- NN performance significantly degrades in both settings. To this end, we devised an alternative approach for data-driven BCJR detection based on the unsupervised learning of a hidden Markov model (HMM). The BCJR-HMM allowed us to optimize both the likelihood function and the state transition matrix without labeling. Moreover, we demonstrated the viability of a hybrid NN and HMM BCJR detection where NN is used for learning the likelihoods, while the state transitions are optimized via HMM. While reducing the required prior channel knowledge, the examined data-driven detectors with learned trellis state transitions achieve bit error rates close to the optimal full CSI-based BCJR, significantly outperforming detection with inaccurate CSI.
Yi: Open Foundation Models by 01.AI
Mar 07, 2024



We introduce the Yi model family, a series of language and multimodal models that demonstrate strong multi-dimensional capabilities. The Yi model family is based on 6B and 34B pretrained language models, then we extend them to chat models, 200K long context models, depth-upscaled models, and vision-language models. Our base models achieve strong performance on a wide range of benchmarks like MMLU, and our finetuned chat models deliver strong human preference rate on major evaluation platforms like AlpacaEval and Chatbot Arena. Building upon our scalable super-computing infrastructure and the classical transformer architecture, we attribute the performance of Yi models primarily to its data quality resulting from our data-engineering efforts. For pretraining, we construct 3.1 trillion tokens of English and Chinese corpora using a cascaded data deduplication and quality filtering pipeline. For finetuning, we polish a small scale (less than 10K) instruction dataset over multiple iterations such that every single instance has been verified directly by our machine learning engineers. For vision-language, we combine the chat language model with a vision transformer encoder and train the model to align visual representations to the semantic space of the language model. We further extend the context length to 200K through lightweight continual pretraining and demonstrate strong needle-in-a-haystack retrieval performance. We show that extending the depth of the pretrained checkpoint through continual pretraining further improves performance. We believe that given our current results, continuing to scale up model parameters using thoroughly optimized data will lead to even stronger frontier models.
On the Robustness of Deep Learning-aided Symbol Detectors to Varying Conditions and Imperfect Channel Knowledge
Jan 23, 2024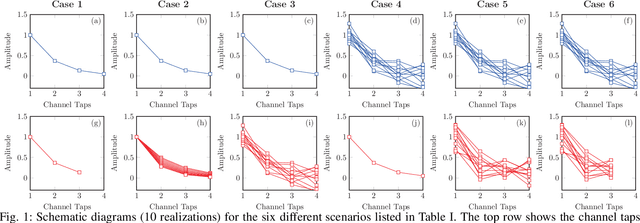
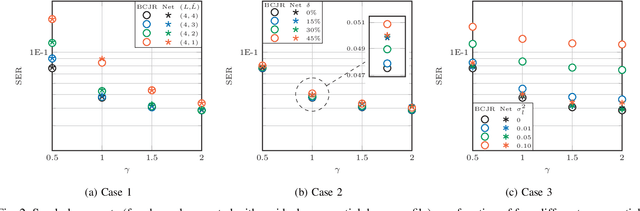
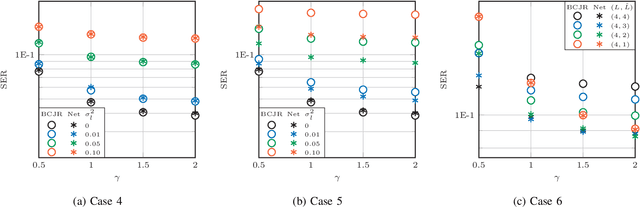

Recently, a data-driven Bahl-Cocke-Jelinek-Raviv (BCJR) algorithm tailored to channels with intersymbol interference has been introduced. This so-called BCJRNet algorithm utilizes neural networks to calculate channel likelihoods. BCJRNet has demonstrated resilience against inaccurate channel tap estimations when applied to a time-invariant channel with ideal exponential decay profiles. However, its generalization capabilities for practically-relevant time-varying channels, where the receiver can only access incorrect channel parameters, remain largely unexplored. The primary contribution of this paper is to expand upon the results from existing literature to encompass a variety of imperfect channel knowledge cases that appear in real-world transmissions. Our findings demonstrate that BCJRNet significantly outperforms the conventional BCJR algorithm for stationary transmission scenarios when learning from noisy channel data and with imperfect channel decay profiles. However, this advantage is shown to diminish when the operating channel is also rapidly time-varying. Our results also show the importance of memory assumptions for conventional BCJR and BCJRNet. An underestimation of the memory largely degrades the performance of both BCJR and BCJRNet, especially in a slow-decaying channel. To mimic a situation closer to a practical scenario, we also combined channel tap uncertainty with imperfect channel memory knowledge. Somewhat surprisingly, our results revealed improved performance when employing the conventional BCJR with an underestimated memory assumption. BCJRNet, on the other hand, showed a consistent performance improvement as the level of accurate memory knowledge increased.