 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Guided Variational Model for Unsupervised Sound Source Tracking
Feb 09, 2026Sound source tracking is often performed using classical array-processing algorithms. Alternative methods, such as machine learning, rely on ground truth position labels, which are costly to obtain. We propose a variational model that can perform single-source unsupervised sound source tracking in latent space, aided by a physics-based decoder. Our experiments demonstrate that the proposed method surpasses traditional baselines and achieves performance and computational complexity comparable to state-of-the-art supervised models. We also show that the method presents substantial robustness to altered microphone array geometries and corrupted microphone position metadata. Finally, the method is extended to multi-source sound tracking and the basic theoretical changes are proposed.
Target Speaker Selection for Neural Network Beamforming in Multi-Speaker Scenarios
Mar 24, 2025



We propose a speaker selection mechanism (SSM) for the training of an end-to-end beamforming neural network, based on recent findings that a listener usually looks to the target speaker with a certain undershot angle. The mechanism allows the neural network model to learn toward which speaker to focus, during training, in a multi-speaker scenario, based on the position of listener and speakers. However, only audio information is necessary during inference. We perform acoustic simulations demonstrating the feasibility and performance when the SSM is employed in training. The results show significant increase in speech intelligibility, quality, and distortion metrics when compared to the minimum variance distortionless filter and the same neural network model trained without SSM. The success of the proposed method is a significant step forward toward the solution of the cocktail party problem.
Unsupervised Variational Acoustic Clustering
Mar 24, 2025



We propose an unsupervised variational acoustic clustering model for clustering audio data in the time-frequency domain. The model leverages variational inference, extended to an autoencoder framework, with a Gaussian mixture model as a prior for the latent space. Specifically designed for audio applications, we introduce a convolutional-recurrent variational autoencoder optimized for efficient time-frequency processing. Our experimental results considering a spoken digits dataset demonstrate a significant improvement in accuracy and clustering performance compared to traditional methods, showcasing the model's enhanced ability to capture complex audio patterns.
Spectral Masking with Explicit Time-Context Windowing for Neural Network-Based Monaural Speech Enhancement
Aug 28, 2024
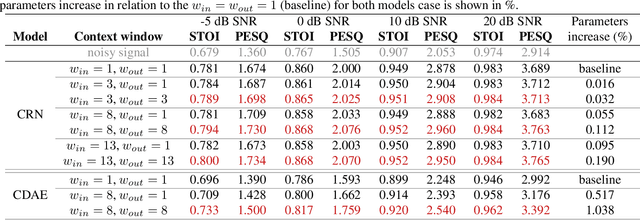

We propose and analyze the use of an explicit time-context window for neural network-based spectral masking speech enhancement to leverage signal context dependencies between neighboring frames. In particular, we concentrate on soft masking and loss computed on the time-frequency representation of the reconstructed speech. We show that the application of a time-context windowing function at both input and output of the neural network model improves the soft mask estimation process by combining multiple estimates taken from different contexts. The proposed approach is only applied as post-optimization in inference mode, not requiring additional layers or special training for the neural network model. Our results show that the method consistently increases both intelligibility and signal quality of the denoised speech, as demonstrated for two classes of convolutional-based speech enhancement models. Importantly, the proposed method requires only a negligible ($\leq1\%$) increase in the number of model parameters, making it suitable for hardware-constrained applications.
EffCRN: An Efficient Convolutional Recurrent Network for High-Performance Speech Enhancement
Jun 05, 2023Fully convolutional recurrent neural networks (FCRNs) have shown state-of-the-art performance in single-channel speech enhancement. However, the number of parameters and the FLOPs/second of the original FCRN are restrictively high. A further important class of efficient networks is the CRUSE topology, serving as reference in our work. By applying a number of topological changes at once, we propose both an efficient FCRN (FCRN15), and a new family of efficient convolutional recurrent neural networks (EffCRN23, EffCRN23lite). We show that our FCRN15 (875K parameters) and EffCRN23lite (396K) outperform the already efficient CRUSE5 (85M) and CRUSE4 (7.2M) networks, respectively, w.r.t. PESQ, DNSMOS and DeltaSNR, while requiring about 94% less parameters and about 20% less #FLOPs/frame. Thereby, according to these metrics, the FCRN/EffCRN class of networks provides new best-in-class network topologies for speech enhancement.