 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffCRN: An Efficient Convolutional Recurrent Network for High-Performance Speech Enhancement
Jun 05, 2023Fully convolutional recurrent neural networks (FCRNs) have shown state-of-the-art performance in single-channel speech enhancement. However, the number of parameters and the FLOPs/second of the original FCRN are restrictively high. A further important class of efficient networks is the CRUSE topology, serving as reference in our work. By applying a number of topological changes at once, we propose both an efficient FCRN (FCRN15), and a new family of efficient convolutional recurrent neural networks (EffCRN23, EffCRN23lite). We show that our FCRN15 (875K parameters) and EffCRN23lite (396K) outperform the already efficient CRUSE5 (85M) and CRUSE4 (7.2M) networks, respectively, w.r.t. PESQ, DNSMOS and DeltaSNR, while requiring about 94% less parameters and about 20% less #FLOPs/frame. Thereby, according to these metrics, the FCRN/EffCRN class of networks provides new best-in-class network topologies for speech enhancement.
Deep Residual Echo Suppression and Noise Reduction: A Multi-Input FCRN Approach in a Hybrid Speech Enhancement System
Aug 06, 2021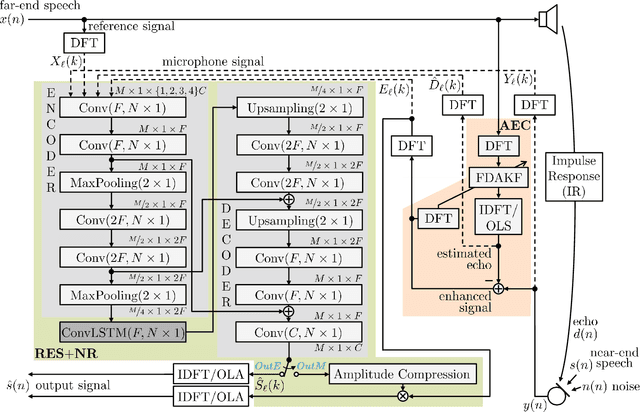
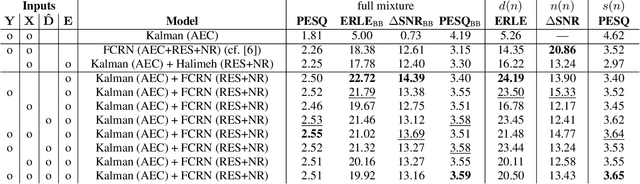
Deep neural network (DNN)-based approaches to acoustic echo cancellation (AEC) and hybrid speech enhancement systems have gained increasing attention recently, introducing significant performance improvements to this research field. Using the fully convolutional recurrent network (FCRN) architecture that is among state of the art topologies for noise reduction, we present a novel deep residual echo suppression and noise reduction with up to four input signals as part of a hybrid speech enhancement system with a linear frequency domain adaptive Kalman filter AEC. In an extensive ablation study, we reveal trade-offs with regard to echo suppression, noise reduction, and near-end speech quality, and provide surprising insights to the choice of the FCRN inputs: In contrast to often seen input combinations for this task, we propose not to use the loudspeaker reference signal, but the enhanced signal after AEC, the microphone signal, and the echo estimate, yielding improvements over previous approaches by more than 0.2 PESQ points.
Y$^2$-Net FCRN for Acoustic Echo and Noise Suppression
Mar 31, 2021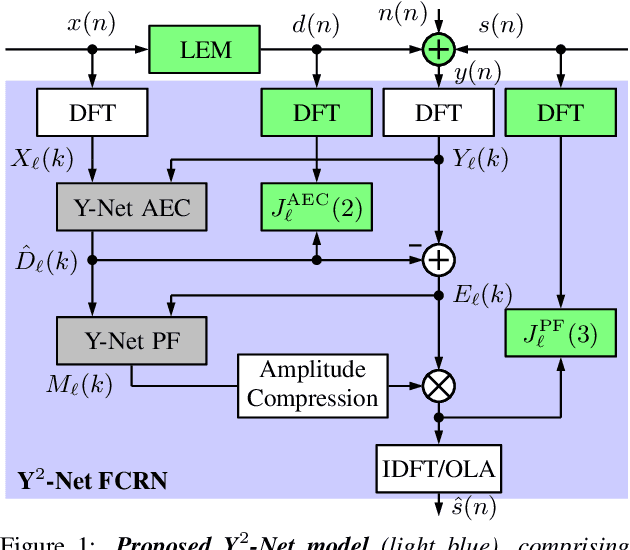
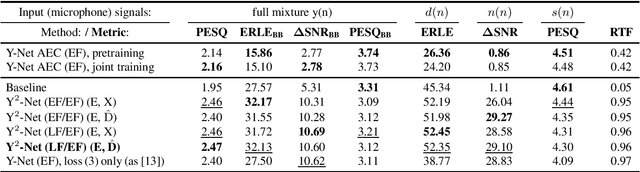
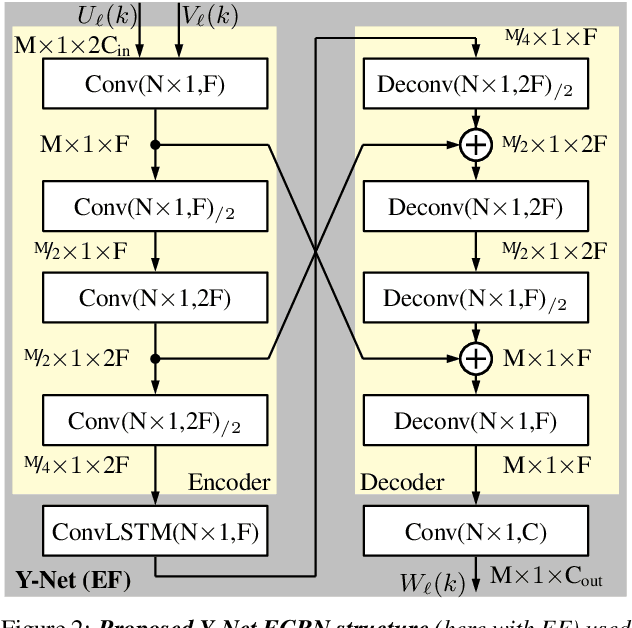
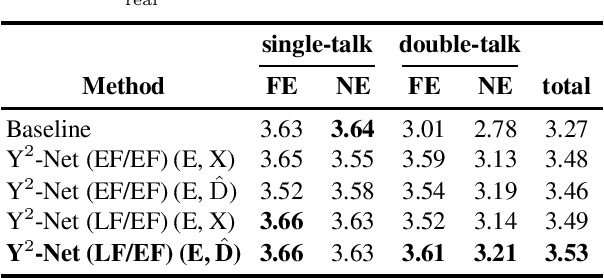
In recent years, deep neural networks (DNNs) were studied as an alternative to traditional acoustic echo cancellation (AEC) algorithms. The proposed models achieved remarkable performance for the separate tasks of AEC and residual echo suppression (RES). A promising network topology is a fully convolutional recurrent network (FCRN) structure, which has already proven its performance on both noise suppression and AEC tasks, individually. However, the combination of AEC, postfiltering, and noise suppression to a single network typically leads to a noticeable decline in the quality of the near-end speech component due to the lack of a separate loss for echo estimation. In this paper, we propose a two-stage model (Y$^2$-Net) which consists of two FCRNs, each with two inputs and one output (Y-Net). The first stage (AEC) yields an echo estimate, which - as a novelty for a DNN AEC model - is further used by the second stage to perform RES and noise suppression. While the subjective listening test of the Interspeech 2021 AEC Challenge mostly yielded results close to the baseline, the proposed method scored an average improvement of 0.46 points over the baseline on the blind testset in double-talk on the instrumental metric DECMOS, provided by the challenge organizers.
AEC in a NetShell: On Target and Topology Choices for FCRN Acoustic Echo Cancellation
Mar 16, 2021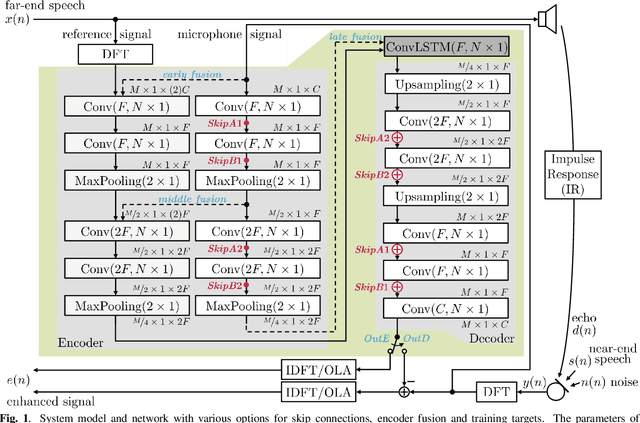
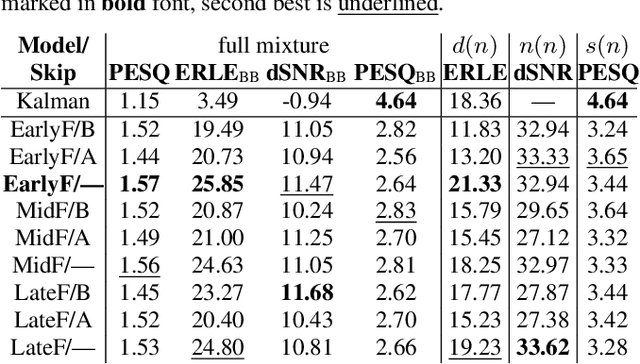
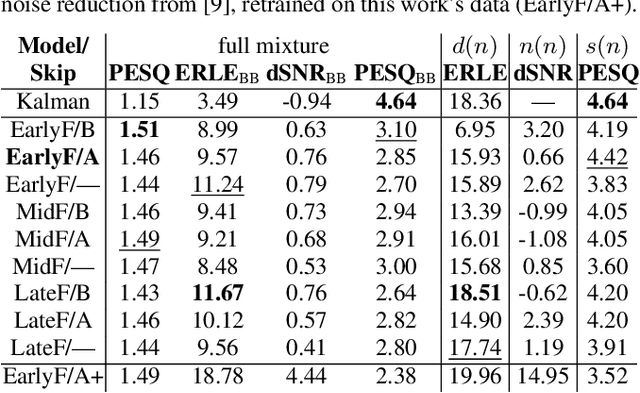
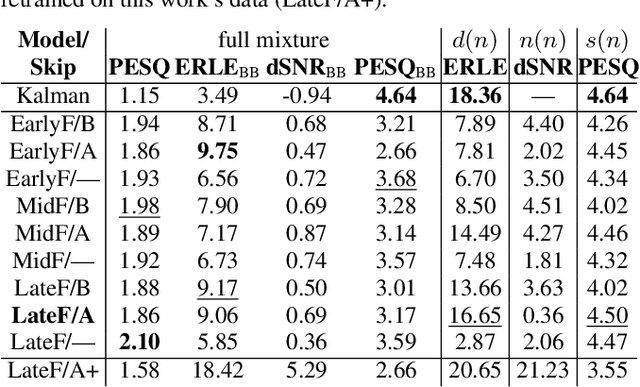
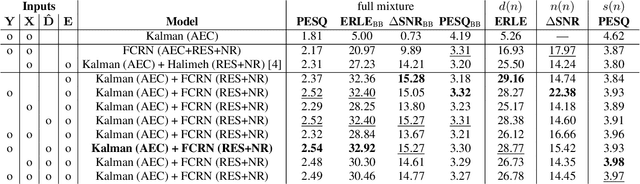
Acoustic echo cancellation (AEC) algorithms have a long-term steady role in signal processing, with approaches improving the performance of applications such as automotive hands-free systems, smart home and loudspeaker devices, or web conference systems. Just recently, very first deep neural network (DNN)-based approaches were proposed with a DNN for joint AEC and residual echo suppression (RES)/noise reduction, showing significant improvements in terms of echo suppression performance. Noise reduction algorithms, on the other hand, have enjoyed already a lot of attention with regard to DNN approaches, with the fully convolutional recurrent network (FCRN) architecture being among state of the art topologies. The recently published impressive echo cancellation performance of joint AEC/RES DNNs, however, so far came along with an undeniable impairment of speech quality. In this work we will heal this issue and significantly improve the near-end speech component quality over existing approaches. Also, we propose for the first time-to the best of our knowledge-a pure DNN AEC in the form of an echo estimator, that is based on a competitive FCRN structure and delivers a quality useful for practical applications.