 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffCRN: An Efficient Convolutional Recurrent Network for High-Performance Speech Enhancement
Jun 05, 2023Fully convolutional recurrent neural networks (FCRNs) have shown state-of-the-art performance in single-channel speech enhancement. However, the number of parameters and the FLOPs/second of the original FCRN are restrictively high. A further important class of efficient networks is the CRUSE topology, serving as reference in our work. By applying a number of topological changes at once, we propose both an efficient FCRN (FCRN15), and a new family of efficient convolutional recurrent neural networks (EffCRN23, EffCRN23lite). We show that our FCRN15 (875K parameters) and EffCRN23lite (396K) outperform the already efficient CRUSE5 (85M) and CRUSE4 (7.2M) networks, respectively, w.r.t. PESQ, DNSMOS and DeltaSNR, while requiring about 94% less parameters and about 20% less #FLOPs/frame. Thereby, according to these metrics, the FCRN/EffCRN class of networks provides new best-in-class network topologies for speech enhancement.
Does a PESQNet Require a Clean Reference Input? The Original PESQ Does, But ACR Listening Tests Don't
May 13, 2022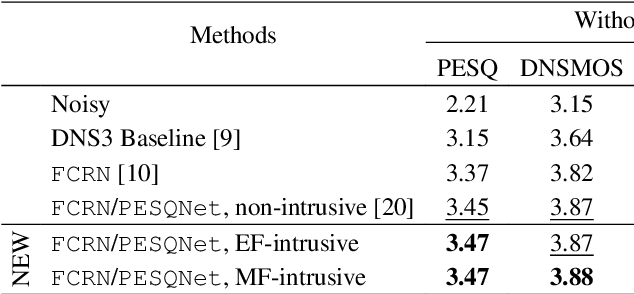
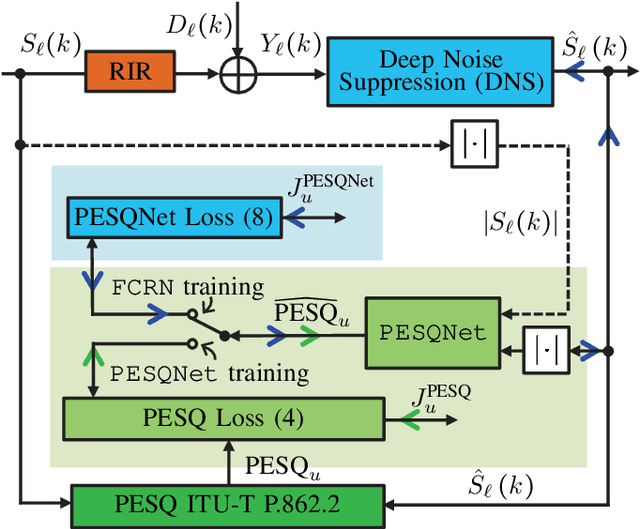

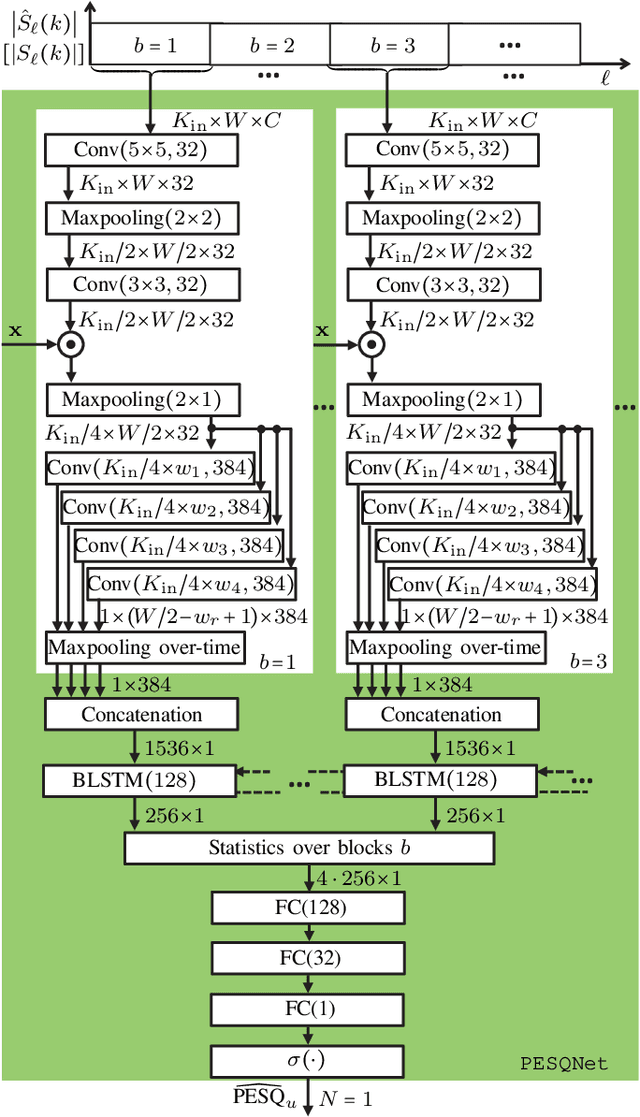
Perceptual evaluation of speech quality (PESQ) requires a clean speech reference as input, but predicts the results from (reference-free) absolute category rating (ACR) tests. In this work, we train a fully convolutional recurrent neural network (FCRN) as deep noise suppression (DNS) model, with either a non-intrusive or an intrusive PESQNet, where only the latter has access to a clean speech reference. The PESQNet is used as a mediator providing a perceptual loss during the DNS training to maximize the PESQ score of the enhanced speech signal. For the intrusive PESQNet, we investigate two topologies, called early-fusion (EF) and middle-fusion (MF) PESQNet, and compare to the non-intrusive PESQNet to evaluate and to quantify the benefits of employing a clean speech reference input during DNS training. Detailed analyses show that the DNS trained with the MF-intrusive PESQNet outperforms the Interspeech 2021 DNS Challenge baseline and the same DNS trained with an MSE loss by 0.23 and 0.12 PESQ points, respectively. Furthermore, we can show that only marginal benefits are obtained compared to the DNS trained with the non-intrusive PESQNet. Therefore, as ACR listening tests, the PESQNet does not necessarily require a clean speech reference input, opening the possibility of using real data for DNS training.
Deep Noise Suppression Maximizing Non-Differentiable PESQ Mediated by a Non-Intrusive PESQNet
Nov 06, 2021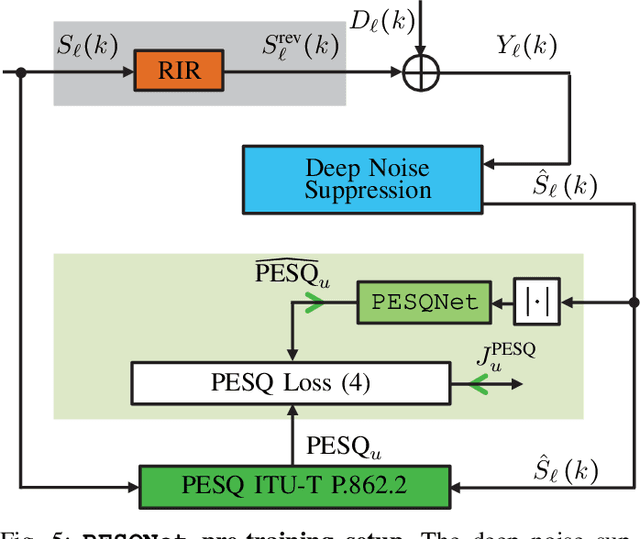
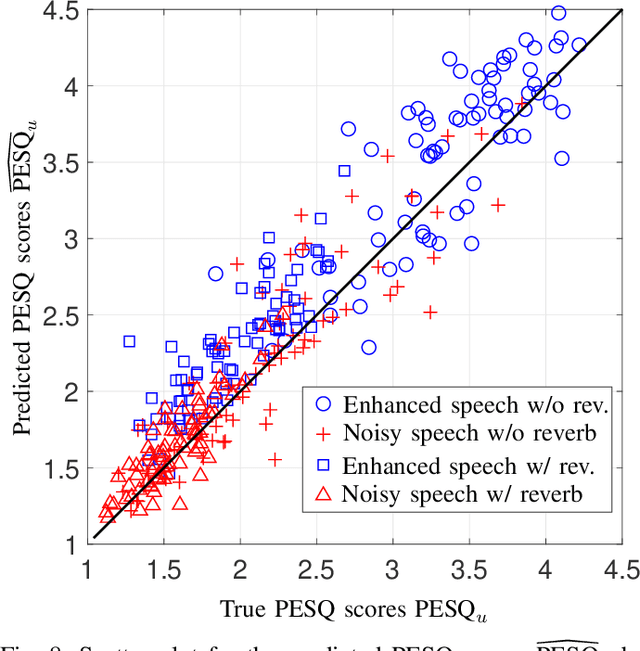
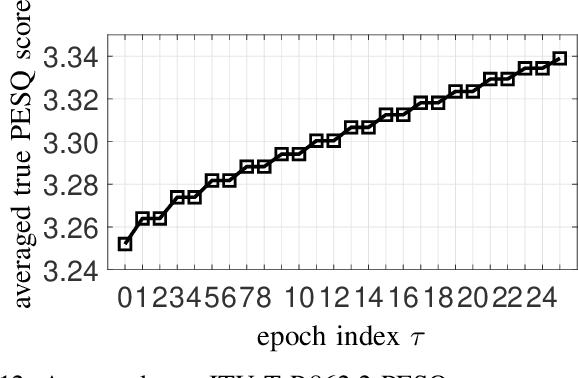
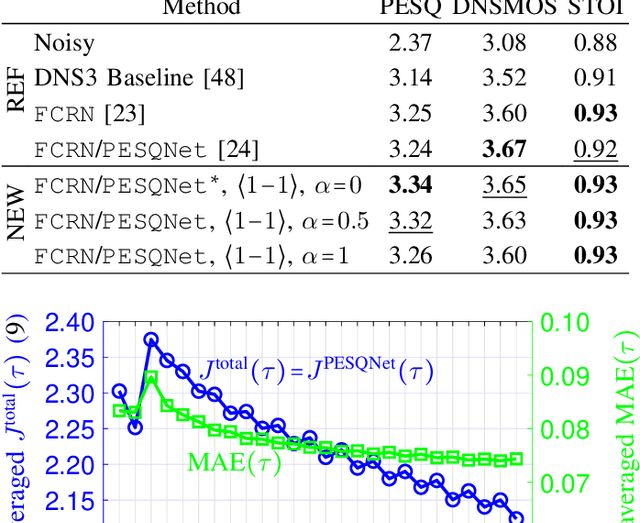
Speech enhancement employing deep neural networks (DNNs) for denoising are called deep noise suppression (DNS). During training, DNS methods are typically trained with mean squared error (MSE) type loss functions, which do not guarantee good perceptual quality. Perceptual evaluation of speech quality (PESQ) is a widely used metric for evaluating speech quality. However, the original PESQ algorithm is non-differentiable, and therefore cannot directly be used as optimization criterion for gradient-based learning. In this work, we propose an end-to-end non-intrusive PESQNet DNN to estimate the PESQ scores of the enhanced speech signal. Thus, by providing a reference-free perceptual loss, it serves as a mediator towards the DNS training, allowing to maximize the PESQ score of the enhanced speech signal. We illustrate the potential of our proposed PESQNet-mediated training on the basis of an already strong baseline DNS. As further novelty, we propose to train the DNS and the PESQNet alternatingly to keep the PESQNet up-to-date and perform well specifically for the DNS under training. Our proposed method is compared to the same DNS trained with MSE-based loss for joint denoising and dereverberation, and the Interspeech 2021 DNS Challenge baseline. Detailed analysis shows that the PESQNet mediation can further increase the DNS performance by about 0.1 PESQ points on synthetic test data and by 0.03 DNSMOS points on real test data, compared to training with the MSE-based loss. Our proposed method also outperforms the Challenge baseline by 0.2 PESQ points on synthetic test data and 0.1 DNSMOS points on real test data.
Y$^2$-Net FCRN for Acoustic Echo and Noise Suppression
Mar 31, 2021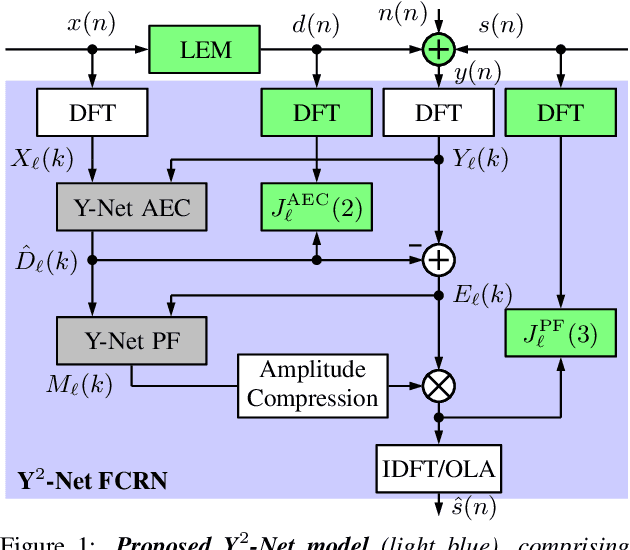
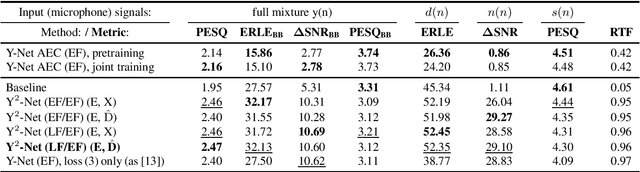
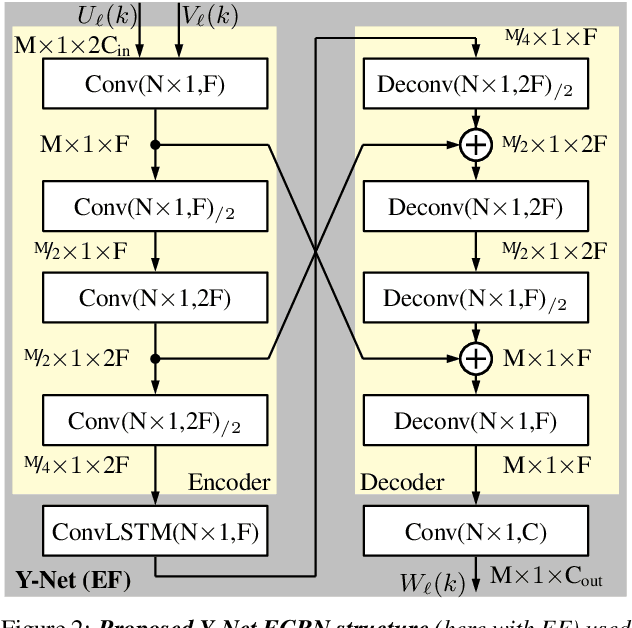
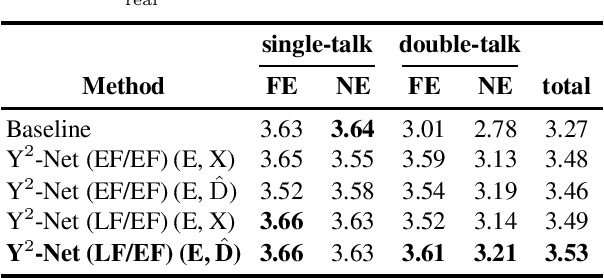
In recent years, deep neural networks (DNNs) were studied as an alternative to traditional acoustic echo cancellation (AEC) algorithms. The proposed models achieved remarkable performance for the separate tasks of AEC and residual echo suppression (RES). A promising network topology is a fully convolutional recurrent network (FCRN) structure, which has already proven its performance on both noise suppression and AEC tasks, individually. However, the combination of AEC, postfiltering, and noise suppression to a single network typically leads to a noticeable decline in the quality of the near-end speech component due to the lack of a separate loss for echo estimation. In this paper, we propose a two-stage model (Y$^2$-Net) which consists of two FCRNs, each with two inputs and one output (Y-Net). The first stage (AEC) yields an echo estimate, which - as a novelty for a DNN AEC model - is further used by the second stage to perform RES and noise suppression. While the subjective listening test of the Interspeech 2021 AEC Challenge mostly yielded results close to the baseline, the proposed method scored an average improvement of 0.46 points over the baseline on the blind testset in double-talk on the instrumental metric DECMOS, provided by the challenge organizers.
Deep Noise Suppression With Non-Intrusive PESQNet Supervision Enabling the Use of Real Training Data
Mar 31, 2021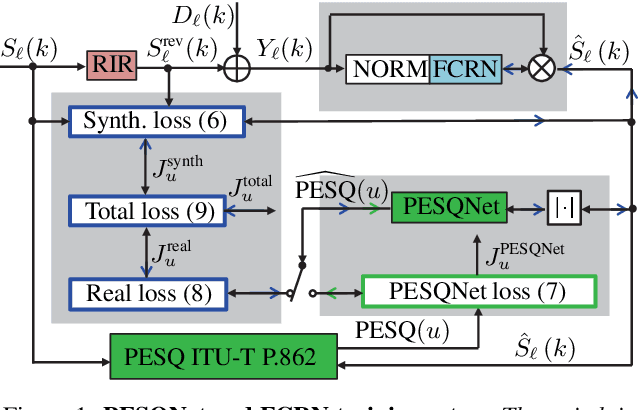
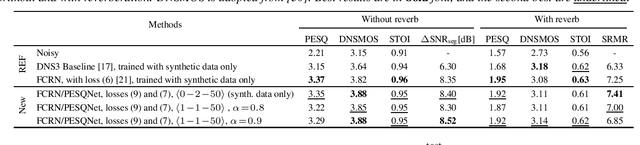


Data-driven speech enhancement employing deep neural networks (DNNs) can provide state-of-the-art performance even in the presence of non-stationary noise. During the training process, most of the speech enhancement neural networks are trained in a fully supervised way with losses requiring noisy speech to be synthesized by clean speech and additive noise. However, in a real implementation, only the noisy speech mixture is available, which leads to the question, how such data could be advantageously employed in training. In this work, we propose an end-to-end non-intrusive PESQNet DNN which estimates perceptual evaluation of speech quality (PESQ) scores, allowing a reference-free loss for real data. As a further novelty, we combine the PESQNet loss with denoising and dereverberation loss terms, and train a complex mask-based fully convolutional recurrent neural network (FCRN) in a "weakly" supervised way, each training cycle employing some synthetic data, some real data, and again synthetic data to keep the PESQNet up-to-date. In a subjective listening test, our proposed framework outperforms the Interspeech 2021 Deep Noise Suppression (DNS) Challenge baseline overall by 0.09 MOS points and in particular by 0.45 background noise MOS points.