 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes a PESQNet Require a Clean Reference Input? The Original PESQ Does, But ACR Listening Tests Don't
Paper and Code
May 13, 2022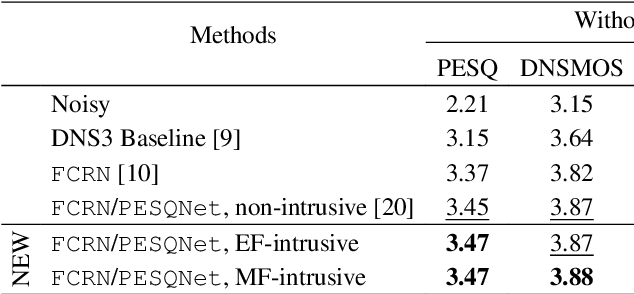
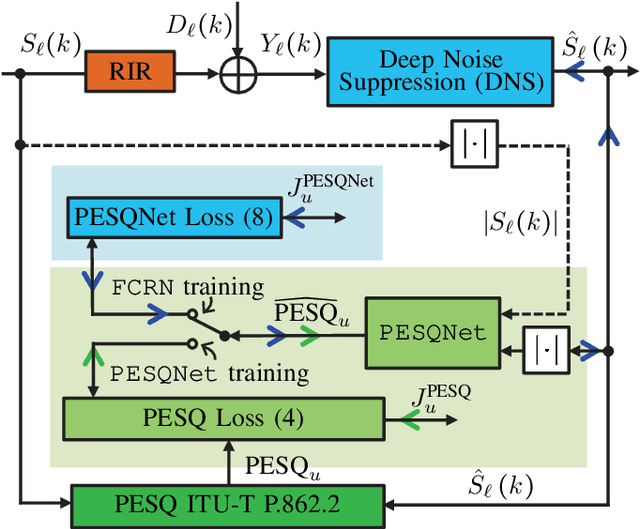

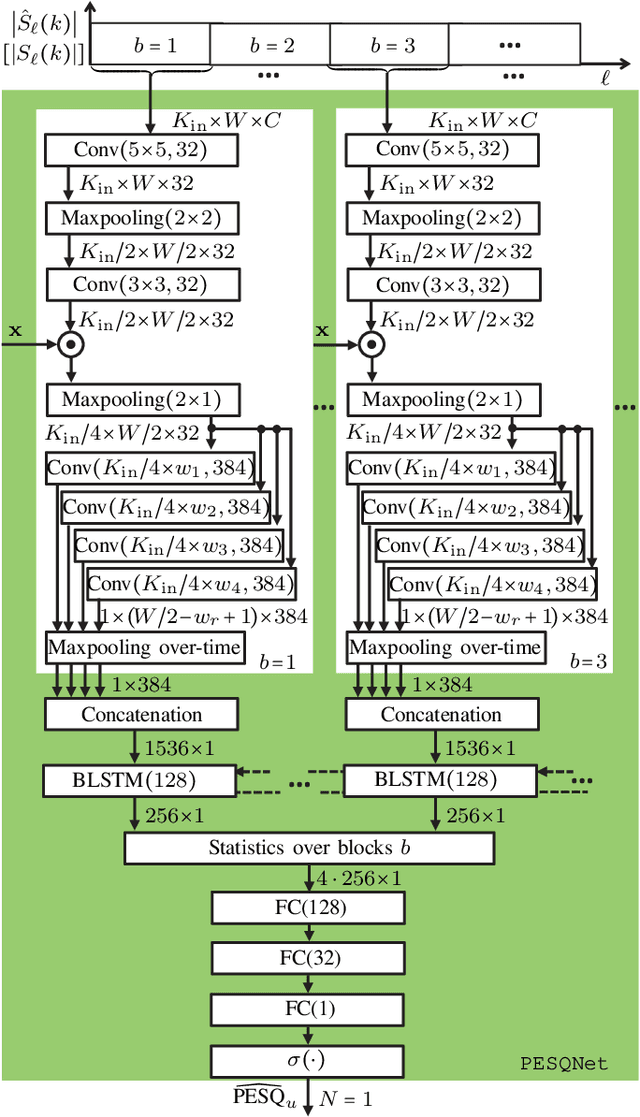
Perceptual evaluation of speech quality (PESQ) requires a clean speech reference as input, but predicts the results from (reference-free) absolute category rating (ACR) tests. In this work, we train a fully convolutional recurrent neural network (FCRN) as deep noise suppression (DNS) model, with either a non-intrusive or an intrusive PESQNet, where only the latter has access to a clean speech reference. The PESQNet is used as a mediator providing a perceptual loss during the DNS training to maximize the PESQ score of the enhanced speech signal. For the intrusive PESQNet, we investigate two topologies, called early-fusion (EF) and middle-fusion (MF) PESQNet, and compare to the non-intrusive PESQNet to evaluate and to quantify the benefits of employing a clean speech reference input during DNS training. Detailed analyses show that the DNS trained with the MF-intrusive PESQNet outperforms the Interspeech 2021 DNS Challenge baseline and the same DNS trained with an MSE loss by 0.23 and 0.12 PESQ points, respectively. Furthermore, we can show that only marginal benefits are obtained compared to the DNS trained with the non-intrusive PESQNet. Therefore, as ACR listening tests, the PESQNet does not necessarily require a clean speech reference input, opening the possibility of using real data for DNS training.