 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Causal to Causal SSL-Supported Transfer Learning: Towards a High-Performance Low-Latency Speech Vocode
Aug 07, 2024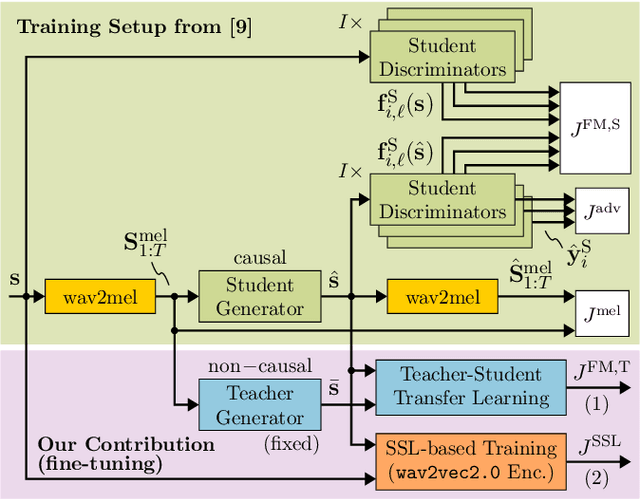
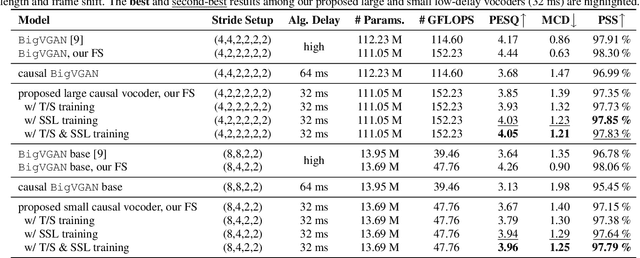
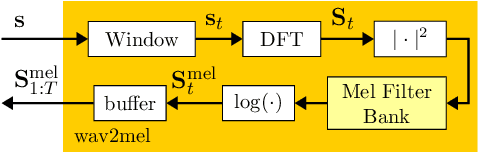

Recently, BigVGAN has emerged as high-performance speech vocoder. Its sequence-to-sequence-based synthesis, however, prohibits usage in low-latency conversational applications. Our work addresses this shortcoming in three steps. First, we introduce low latency into BigVGAN via implementing causal convolutions, yielding decreased performance. Second, to regain performance, we propose a teacher-student transfer learning scheme to distill the high-delay non-causal BigVGAN into our low-latency causal vocoder. Third, taking advantage of a self-supervised learning (SSL) model, in our case wav2vec 2.0, we align its encoder speech representations extracted from our low-latency causal vocoder to the ground truth ones. In speaker-independent settings, both proposed training schemes notably elevate the performance of our low-latency vocoder, closing up to the original high-delay BigVGAN. At only 21% higher complexity, our best small causal vocoder achieves 3.96 PESQ and 1.25 MCD, excelling even the original small non-causal BigVGAN (3.64 PESQ) by 0.32 PESQ and 0.1 MCD points, respectively.
EffCRN: An Efficient Convolutional Recurrent Network for High-Performance Speech Enhancement
Jun 05, 2023Fully convolutional recurrent neural networks (FCRNs) have shown state-of-the-art performance in single-channel speech enhancement. However, the number of parameters and the FLOPs/second of the original FCRN are restrictively high. A further important class of efficient networks is the CRUSE topology, serving as reference in our work. By applying a number of topological changes at once, we propose both an efficient FCRN (FCRN15), and a new family of efficient convolutional recurrent neural networks (EffCRN23, EffCRN23lite). We show that our FCRN15 (875K parameters) and EffCRN23lite (396K) outperform the already efficient CRUSE5 (85M) and CRUSE4 (7.2M) networks, respectively, w.r.t. PESQ, DNSMOS and DeltaSNR, while requiring about 94% less parameters and about 20% less #FLOPs/frame. Thereby, according to these metrics, the FCRN/EffCRN class of networks provides new best-in-class network topologies for speech enhancement.