 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Guided Variational Model for Unsupervised Sound Source Tracking
Feb 09, 2026Sound source tracking is often performed using classical array-processing algorithms. Alternative methods, such as machine learning, rely on ground truth position labels, which are costly to obtain. We propose a variational model that can perform single-source unsupervised sound source tracking in latent space, aided by a physics-based decoder. Our experiments demonstrate that the proposed method surpasses traditional baselines and achieves performance and computational complexity comparable to state-of-the-art supervised models. We also show that the method presents substantial robustness to altered microphone array geometries and corrupted microphone position metadata. Finally, the method is extended to multi-source sound tracking and the basic theoretical changes are proposed.
Clustering of Acoustic Environments with Variational Autoencoders for Hearing Devices
Oct 02, 2025Particularly in hearing devices, the environmental context is taken into account for audio processing, often through classification. Traditional acoustic environment classification relies on classical algorithms, which are unable to extract meaningful representations of high-dimensionality data, or on supervised learning, being limited by the availability of labels. Knowing that human-imposed labels do not always reflect the true structure of acoustic scenes, we explore the (unsupervised) clustering of acoustic environments using variational autoencoders (VAEs), presenting a structured latent space suitable for the task. We propose a VAE model for categorical latent clustering employing a Gumbel-Softmax reparameterization with a time-context windowing scheme, tailored for real-world hearing device scenarios. Additionally, general adaptations on VAE architectures for audio clustering are also proposed. The approaches are validated through the clustering of spoken digits, a simpler task where labels are meaningful, and urban soundscapes, which recordings present strong overlap in time and frequency. While all variational methods succeeded when clustering spoken digits, only the proposed model achieved effective clustering performance on urban acoustic scenes, given its categorical nature.
Categorical Unsupervised Variational Acoustic Clustering
Apr 10, 2025


We propose a categorical approach for unsupervised variational acoustic clustering of audio data in the time-frequency domain. The consideration of a categorical distribution enforces sharper clustering even when data points strongly overlap in time and frequency, which is the case for most datasets of urban acoustic scenes. To this end, we use a Gumbel-Softmax distribution as a soft approximation to the categorical distribution, allowing for training via backpropagation. In this settings, the softmax temperature serves as the main mechanism to tune clustering performance. The results show that the proposed model can obtain impressive clustering performance for all considered datasets, even when data points strongly overlap in time and frequency.
Hybrid Real- and Complex-valued Neural Network Architecture
Apr 04, 2025We propose a \emph{hybrid} real- and complex-valued \emph{neural network} (HNN) architecture, designed to combine the computational efficiency of real-valued processing with the ability to effectively handle complex-valued data. We illustrate the limitations of using real-valued neural networks (RVNNs) for inherently complex-valued problems by showing how it learnt to perform complex-valued convolution, but with notable inefficiencies stemming from its real-valued constraints. To create the HNN, we propose to use building blocks containing both real- and complex-valued paths, where information between domains is exchanged through domain conversion functions. We also introduce novel complex-valued activation functions, with higher generalisation and parameterisation efficiency. HNN-specific architecture search techniques are described to navigate the larger solution space. Experiments with the AudioMNIST dataset demonstrate that the HNN reduces cross-entropy loss and consumes less parameters compared to an RVNN for all considered cases. Such results highlight the potential for the use of partially complex-valued processing in neural networks and applications for HNNs in many signal processing domains.
Unsupervised Variational Acoustic Clustering
Mar 24, 2025



We propose an unsupervised variational acoustic clustering model for clustering audio data in the time-frequency domain. The model leverages variational inference, extended to an autoencoder framework, with a Gaussian mixture model as a prior for the latent space. Specifically designed for audio applications, we introduce a convolutional-recurrent variational autoencoder optimized for efficient time-frequency processing. Our experimental results considering a spoken digits dataset demonstrate a significant improvement in accuracy and clustering performance compared to traditional methods, showcasing the model's enhanced ability to capture complex audio patterns.
Target Speaker Selection for Neural Network Beamforming in Multi-Speaker Scenarios
Mar 24, 2025



We propose a speaker selection mechanism (SSM) for the training of an end-to-end beamforming neural network, based on recent findings that a listener usually looks to the target speaker with a certain undershot angle. The mechanism allows the neural network model to learn toward which speaker to focus, during training, in a multi-speaker scenario, based on the position of listener and speakers. However, only audio information is necessary during inference. We perform acoustic simulations demonstrating the feasibility and performance when the SSM is employed in training. The results show significant increase in speech intelligibility, quality, and distortion metrics when compared to the minimum variance distortionless filter and the same neural network model trained without SSM. The success of the proposed method is a significant step forward toward the solution of the cocktail party problem.
Spectral Masking with Explicit Time-Context Windowing for Neural Network-Based Monaural Speech Enhancement
Aug 28, 2024
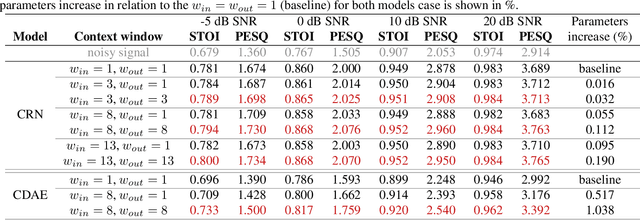

We propose and analyze the use of an explicit time-context window for neural network-based spectral masking speech enhancement to leverage signal context dependencies between neighboring frames. In particular, we concentrate on soft masking and loss computed on the time-frequency representation of the reconstructed speech. We show that the application of a time-context windowing function at both input and output of the neural network model improves the soft mask estimation process by combining multiple estimates taken from different contexts. The proposed approach is only applied as post-optimization in inference mode, not requiring additional layers or special training for the neural network model. Our results show that the method consistently increases both intelligibility and signal quality of the denoised speech, as demonstrated for two classes of convolutional-based speech enhancement models. Importantly, the proposed method requires only a negligible ($\leq1\%$) increase in the number of model parameters, making it suitable for hardware-constrained applications.