 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Radio using Variational Quantum RF Sensing
Mar 10, 2026In modern wireless networks, radio channels serve a dual role. Whilst their primary function is to carry bits of information from a transmitter to a receiver, the intrinsic sensitivity of transmitted signals to the physical structure of the environment makes the channel a powerful source of knowledge about the world. In this paper, we consider an agent that learns about its environment using a quantum sensing probe, optimised using a quantum circuit, which interacts with the radio-frequency (RF) electromagnetic field. We use data obtained from a ray-tracer to train the quantum circuit and learning model and we provide extensive experiments under realistic conditions on a localisation task. We show that using quantum sensors to learn from radio signals can enable intelligent systems that require no channel measurements at deployment, remain sensitive to weak and obstructed RF signals, and can learn about the world despite operating with strictly less information than classical baselines.
Quantum Integrated Sensing and Computation with Indefinite Causal Order
Feb 10, 2026Quantum operations with indefinite causal order (ICO) represent a framework in quantum information processing where the relative order between two events can be indefinite. In this paper, we investigate whether sensing and computation, two canonical tasks in quantum information processing, can be carried out within the ICO framework. We propose a scheme for integrated sensing and computation that uses the same quantum state for both tasks. The quantum state is represented as an agent that performs state observation and learns a function of the state to make predictions via a parametric model. Under an ICO operation, the agent experiences a superposition of orders, one in which it performs state observation and then executes the required computation steps, and another in which the agent carries out the computation first and then performs state observation. This is distinct from prevailing information processing and machine intelligence paradigms where information acquisition and learning follow a strict causal order, with the former always preceding the latter. We provide experimental results and we show that the proposed scheme can achieve small training and testing losses on a representative task in magnetic navigation.
Physics-Guided Variational Model for Unsupervised Sound Source Tracking
Feb 09, 2026Sound source tracking is often performed using classical array-processing algorithms. Alternative methods, such as machine learning, rely on ground truth position labels, which are costly to obtain. We propose a variational model that can perform single-source unsupervised sound source tracking in latent space, aided by a physics-based decoder. Our experiments demonstrate that the proposed method surpasses traditional baselines and achieves performance and computational complexity comparable to state-of-the-art supervised models. We also show that the method presents substantial robustness to altered microphone array geometries and corrupted microphone position metadata. Finally, the method is extended to multi-source sound tracking and the basic theoretical changes are proposed.
Clustering of Acoustic Environments with Variational Autoencoders for Hearing Devices
Oct 02, 2025Particularly in hearing devices, the environmental context is taken into account for audio processing, often through classification. Traditional acoustic environment classification relies on classical algorithms, which are unable to extract meaningful representations of high-dimensionality data, or on supervised learning, being limited by the availability of labels. Knowing that human-imposed labels do not always reflect the true structure of acoustic scenes, we explore the (unsupervised) clustering of acoustic environments using variational autoencoders (VAEs), presenting a structured latent space suitable for the task. We propose a VAE model for categorical latent clustering employing a Gumbel-Softmax reparameterization with a time-context windowing scheme, tailored for real-world hearing device scenarios. Additionally, general adaptations on VAE architectures for audio clustering are also proposed. The approaches are validated through the clustering of spoken digits, a simpler task where labels are meaningful, and urban soundscapes, which recordings present strong overlap in time and frequency. While all variational methods succeeded when clustering spoken digits, only the proposed model achieved effective clustering performance on urban acoustic scenes, given its categorical nature.
Adaptive Bayesian Single-Shot Quantum Sensing
Jul 22, 2025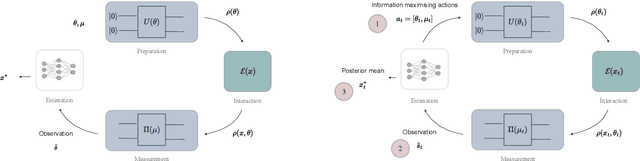
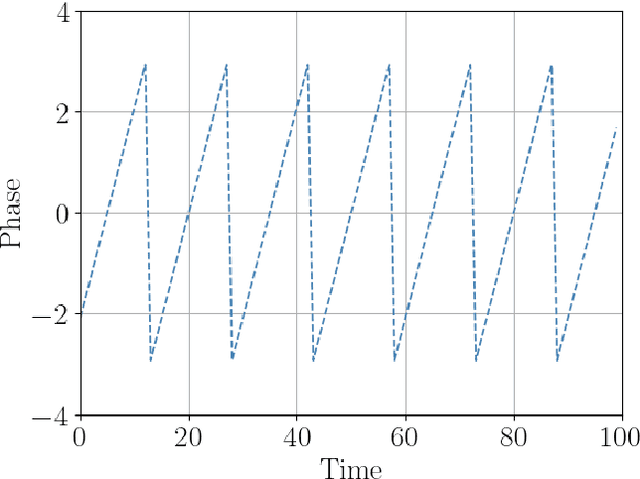

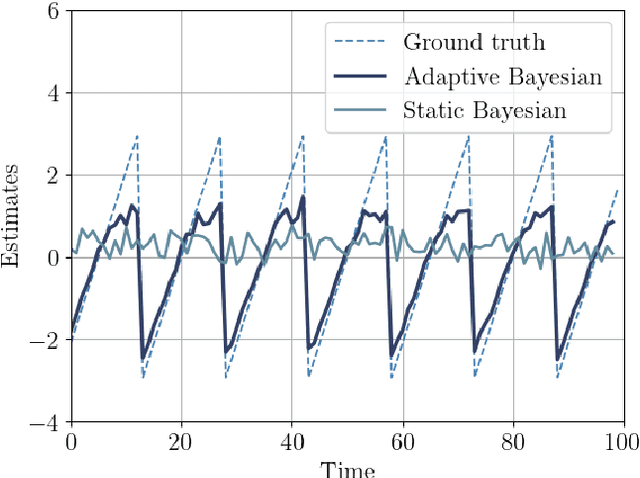
Quantum sensing harnesses the unique properties of quantum systems to enable precision measurements of physical quantities such as time, magnetic and electric fields, acceleration, and gravitational gradients well beyond the limits of classical sensors. However, identifying suitable sensing probes and measurement schemes can be a classically intractable task, as it requires optimizing over Hilbert spaces of high dimension. In variational quantum sensing, a probe quantum system is generated via a parameterized quantum circuit (PQC), exposed to an unknown physical parameter through a quantum channel, and measured to collect classical data. PQCs and measurements are typically optimized using offline strategies based on frequentist learning criteria. This paper introduces an adaptive protocol that uses Bayesian inference to optimize the sensing policy via the maximization of the active information gain. The proposed variational methodology is tailored for non-asymptotic regimes where a single probe can be deployed in each time step, and is extended to support the fusion of estimates from multiple quantum sensing agents.
Dynamic Estimation Loss Control in Variational Quantum Sensing via Online Conformal Inference
May 29, 2025Quantum sensing exploits non-classical effects to overcome limitations of classical sensors, with applications ranging from gravitational-wave detection to nanoscale imaging. However, practical quantum sensors built on noisy intermediate-scale quantum (NISQ) devices face significant noise and sampling constraints, and current variational quantum sensing (VQS) methods lack rigorous performance guarantees. This paper proposes an online control framework for VQS that dynamically updates the variational parameters while providing deterministic error bars on the estimates. By leveraging online conformal inference techniques, the approach produces sequential estimation sets with a guaranteed long-term risk level. Experiments on a quantum magnetometry task confirm that the proposed dynamic VQS approach maintains the required reliability over time, while still yielding precise estimates. The results demonstrate the practical benefits of combining variational quantum algorithms with online conformal inference to achieve reliable quantum sensing on NISQ devices.
Expected Free Energy-based Planning as Variational Inference
Apr 21, 2025

We address the problem of planning under uncertainty, where an agent must choose actions that not only achieve desired outcomes but also reduce uncertainty. Traditional methods often treat exploration and exploitation as separate objectives, lacking a unified inferential foundation. Active inference, grounded in the Free Energy Principle, offers such a foundation by minimizing Expected Free Energy (EFE), a cost function that combines utility with epistemic drives like ambiguity resolution and novelty seeking. However, the computational burden of EFE minimization has remained a major obstacle to its scalability. In this paper, we show that EFE-based planning arises naturally from minimizing a variational free energy functional on a generative model augmented with preference and epistemic priors. This result reinforces theoretical consistency with the Free Energy Principle, by casting planning itself as variational inference. Our formulation yields optimal policies that jointly support goal achievement and information gain, while incorporating a complexity term that accounts for bounded computational resources. This unifying framework connects and extends existing methods, enabling scalable, resource-aware implementations of active inference agents.
Physics-Aware Initialization Refinement in Code-Aided EM for Blind Channel Estimation
Apr 15, 2025This paper addresses the well-known local maximum problem of the expectation-maximization (EM) algorithm in blind intersymbol interference (ISI) channel estimation. This problem primarily results from phase and shift ambiguity during initialization, which blind estimation is inherently unable to distinguish. We propose an effective initialization refinement algorithm that utilizes the decoder output as a model selection metric, incorporating a technique to detect phase and shift ambiguity. Our results show that the proposed algorithm significantly reduces the number of local maximum cases to nearly one-third for a 3-tap ISI channel under highly uncertain initial conditions. The improvement becomes more pronounced as initial errors increase and the channel memory grows. When used in a turbo equalizer, the proposed algorithm is required only in the first turbo iteration, which limits any complexity increase with subsequent iterations.
Categorical Unsupervised Variational Acoustic Clustering
Apr 10, 2025


We propose a categorical approach for unsupervised variational acoustic clustering of audio data in the time-frequency domain. The consideration of a categorical distribution enforces sharper clustering even when data points strongly overlap in time and frequency, which is the case for most datasets of urban acoustic scenes. To this end, we use a Gumbel-Softmax distribution as a soft approximation to the categorical distribution, allowing for training via backpropagation. In this settings, the softmax temperature serves as the main mechanism to tune clustering performance. The results show that the proposed model can obtain impressive clustering performance for all considered datasets, even when data points strongly overlap in time and frequency.
Modified Baum-Welch Algorithm for Joint Blind Channel Estimation and Turbo Equalization
Dec 10, 2024
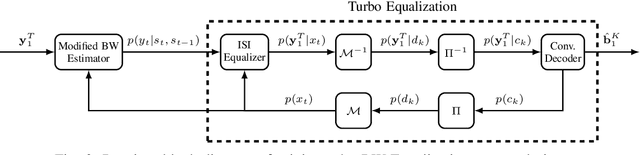
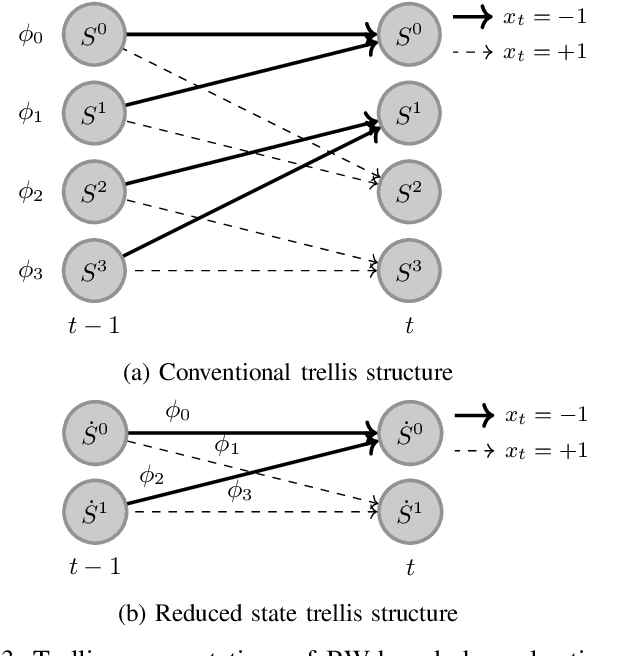
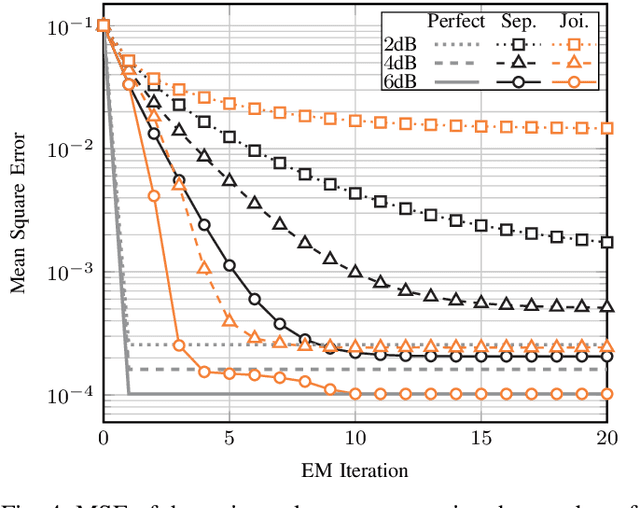
Blind estimation of intersymbol interference channels based on the Baum-Welch (BW) algorithm, a specific implementation of the expectation-maximization (EM) algorithm for training hidden Markov models, is robust and does not require labeled data. However, it is known for its extensive computation cost, slow convergence, and frequently converges to a local maximum. In this paper, we modified the trellis structure of the BW algorithm by associating the channel parameters with two consecutive states. This modification enables us to reduce the number of required states by half while maintaining the same performance. Moreover, to improve the convergence rate and the estimation performance, we construct a joint turbo-BW-equalization system by exploiting the extrinsic information produced by the turbo decoder to refine the BW-based estimator at each EM iteration. Our experiments demonstrate that the joint system achieves convergence in just 4 EM iterations, which is 8 iterations less than a separate system design for a signal-to-noise ratio (SNR) of 6 dB. Additionally, the joint system provides improved estimation accuracy with a mean square error (MSE) of $10^{-4}$. We also identify scenarios where a joint design is not preferable, especially when the channel is noisy (e.g., SNR=2 dB) and the turbo decoder is unable to provide reliable extrinsic information for a BW-based estimator.