 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurvature-aware Expected Free Energy as an Acquisition Function for Bayesian Optimization
Mar 27, 2026We propose an Expected Free Energy-based acquisition function for Bayesian optimization to solve the joint learning and optimization problem, i.e., optimize and learn the underlying function simultaneously. We show that, under specific assumptions, Expected Free Energy reduces to Upper Confidence Bound, Lower Confidence Bound, and Expected Information Gain. We prove that Expected Free Energy has unbiased convergence guarantees for concave functions. Using the results from these derivations, we introduce a curvature-aware update law for Expected Free Energy and show its proof of concept using a system identification problem on a Van der Pol oscillator. Through rigorous simulation experiments, we show that our adaptive Expected Free Energy-based acquisition function outperforms state-of-the-art acquisition functions with the least final simple regret and error in learning the Gaussian process.
Gaussian Variational Inference with Non-Gaussian Factors for State Estimation: A UWB Localization Case Study
Dec 22, 2025This letter extends the exactly sparse Gaussian variational inference (ESGVI) algorithm for state estimation in two complementary directions. First, ESGVI is generalized to operate on matrix Lie groups, enabling the estimation of states with orientation components while respecting the underlying group structure. Second, factors are introduced to accommodate heavy-tailed and skewed noise distributions, as commonly encountered in ultra-wideband (UWB) localization due to non-line-of-sight (NLOS) and multipath effects. Both extensions are shown to integrate naturally within the ESGVI framework while preserving its sparse and derivative-free structure. The proposed approach is validated in a UWB localization experiment with NLOS-rich measurements, demonstrating improved accuracy and comparable consistency. Finally, a Python implementation within a factor-graph-based estimation framework is made open-source (https://github.com/decargroup/gvi_ws) to support broader research use.
Expected Free Energy-based Planning as Variational Inference
Apr 21, 2025

We address the problem of planning under uncertainty, where an agent must choose actions that not only achieve desired outcomes but also reduce uncertainty. Traditional methods often treat exploration and exploitation as separate objectives, lacking a unified inferential foundation. Active inference, grounded in the Free Energy Principle, offers such a foundation by minimizing Expected Free Energy (EFE), a cost function that combines utility with epistemic drives like ambiguity resolution and novelty seeking. However, the computational burden of EFE minimization has remained a major obstacle to its scalability. In this paper, we show that EFE-based planning arises naturally from minimizing a variational free energy functional on a generative model augmented with preference and epistemic priors. This result reinforces theoretical consistency with the Free Energy Principle, by casting planning itself as variational inference. Our formulation yields optimal policies that jointly support goal achievement and information gain, while incorporating a complexity term that accounts for bounded computational resources. This unifying framework connects and extends existing methods, enabling scalable, resource-aware implementations of active inference agents.
Variational message passing for online polynomial NARMAX identification
Apr 02, 2022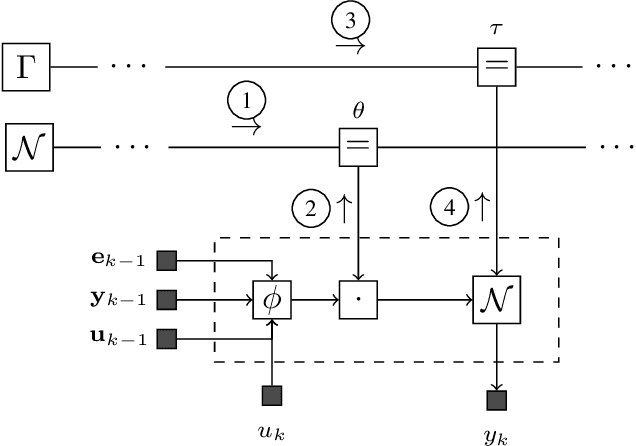

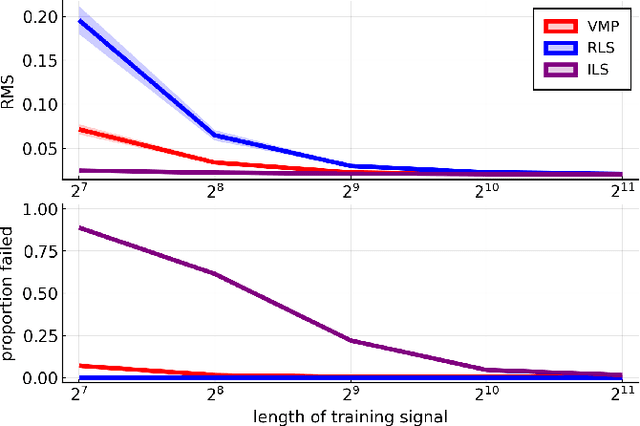
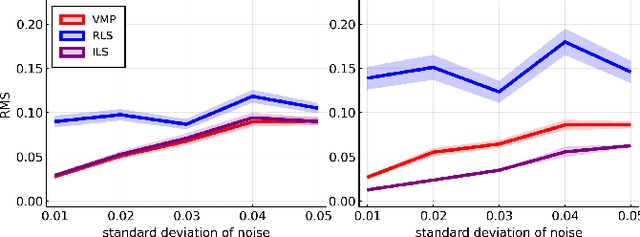
We propose a variational Bayesian inference procedure for online nonlinear system identification. For each output observation, a set of parameter posterior distributions is updated, which is then used to form a posterior predictive distribution for future outputs. We focus on the class of polynomial NARMAX models, which we cast into probabilistic form and represent in terms of a Forney-style factor graph. Inference in this graph is efficiently performed by a variational message passing algorithm. We show empirically that our variational Bayesian estimator outperforms an online recursive least-squares estimator, most notably in small sample size settings and low noise regimes, and performs on par with an iterative least-squares estimator trained offline.
Back to the Future -- Sequential Alignment of Text Representations
Sep 10, 2019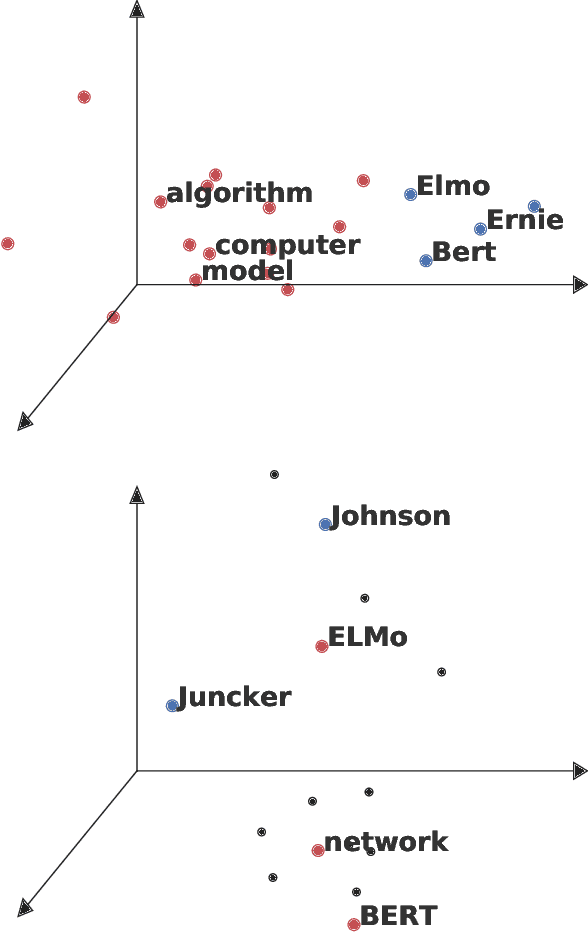


Language evolves over time in many ways relevant to natural language processing tasks. For example, recent occurrences of tokens 'BERT' and 'ELMO' in publications refer to neural network architectures rather than persons. This type of temporal signal is typically overlooked, but is important if one aims to deploy a machine learning model over an extended period of time. In particular, language evolution causes data drift between time-steps in sequential decision-making tasks. Examples of such tasks include prediction of paper acceptance for yearly conferences (regular intervals) or author stance prediction for rumours on Twitter (irregular intervals). Inspired by successes in computer vision, we tackle data drift by sequentially aligning learned representations. We evaluate on three challenging tasks varying in terms of time-scales, linguistic units, and domains. These tasks show our method outperforming several strong baselines, including using all available data. We argue that, due to its low computational expense, sequential alignment is a practical solution to dealing with language evolution.
On reducing sampling variance in covariate shift using control variates
Oct 17, 2017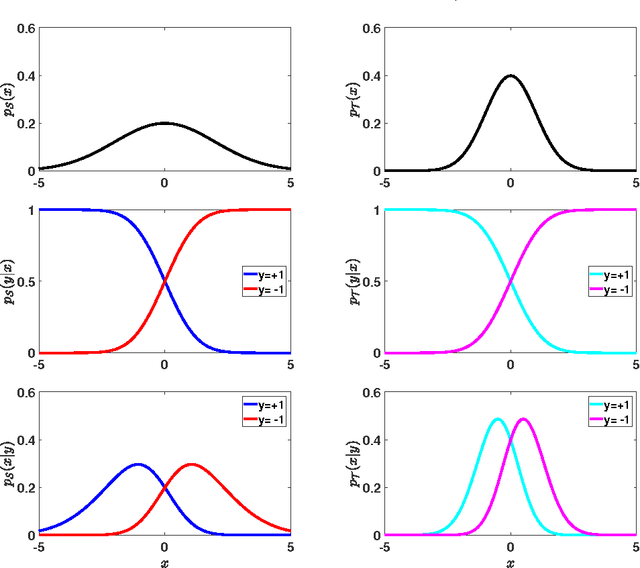
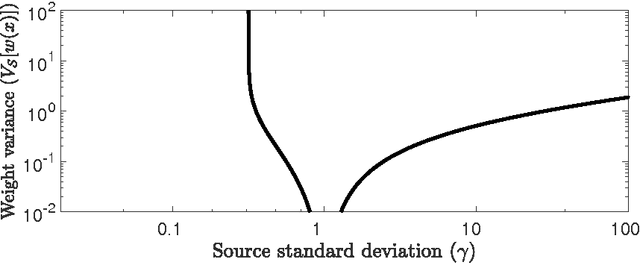


Covariate shift classification problems can in principle be tackled by importance-weighting training samples. However, the sampling variance of the risk estimator is often scaled up dramatically by the weights. This means that during cross-validation - when the importance-weighted risk is repeatedly evaluated - suboptimal hyperparameter estimates are produced. We study the sampling variances of the importance-weighted versus the oracle estimator as a function of the relative scale of the training data. We show that introducing a control variate can reduce the variance of the importance-weighted risk estimator, which leads to superior regularization parameter estimates when the training data is much smaller in scale than the test data.