Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn reducing sampling variance in covariate shift using control variates
Paper and Code
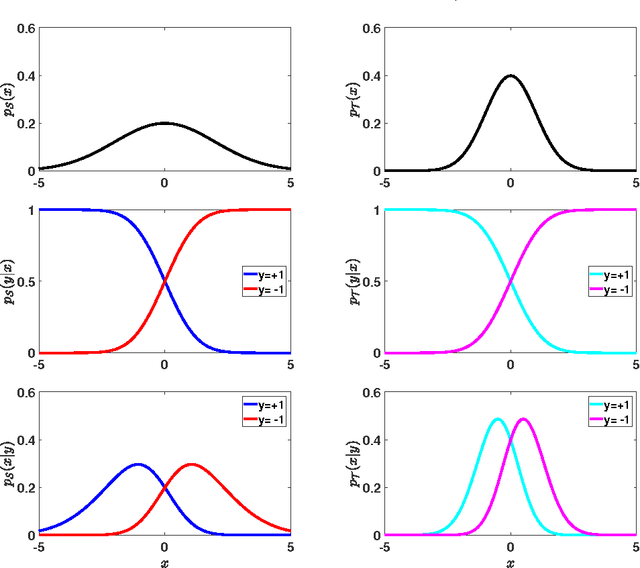
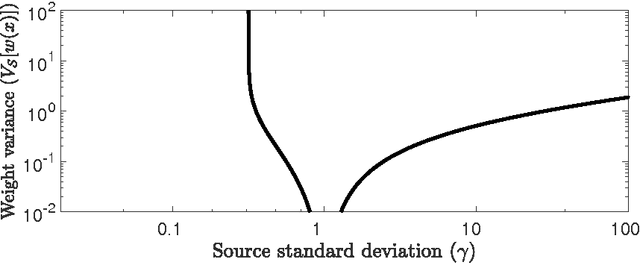


Covariate shift classification problems can in principle be tackled by importance-weighting training samples. However, the sampling variance of the risk estimator is often scaled up dramatically by the weights. This means that during cross-validation - when the importance-weighted risk is repeatedly evaluated - suboptimal hyperparameter estimates are produced. We study the sampling variances of the importance-weighted versus the oracle estimator as a function of the relative scale of the training data. We show that introducing a control variate can reduce the variance of the importance-weighted risk estimator, which leads to superior regularization parameter estimates when the training data is much smaller in scale than the test data.
* Submitted to the journal Pattern Recognition Letters
View paper on