 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAMLD: Bayesian Active Meta-Learning by Disagreement
Paper and Code
Oct 19, 2021
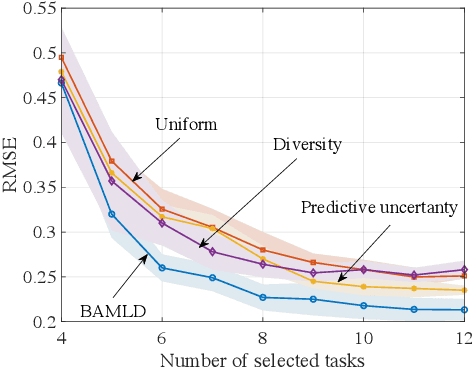
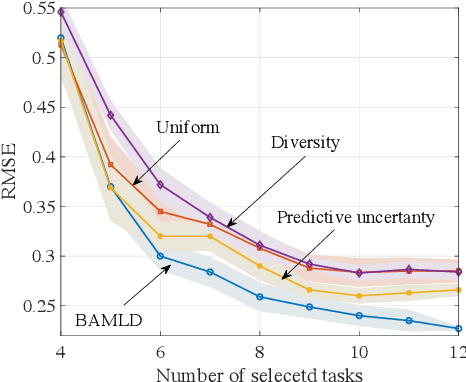

Data-efficient learning algorithms are essential in many practical applications for which data collection and labeling is expensive or infeasible, e.g., for autonomous cars. To address this problem, meta-learning infers an inductive bias from a set of meta-training tasks in order to learn new, but related, task using a small number of samples. Most studies assume the meta-learner to have access to labeled data sets from a large number of tasks. In practice, one may have available only unlabeled data sets from the tasks, requiring a costly labeling procedure to be carried out before use in standard meta-learning schemes. To decrease the number of labeling requests for meta-training tasks, this paper introduces an information-theoretic active task selection mechanism which quantifies the epistemic uncertainty via disagreements among the predictions obtained under different inductive biases. We detail an instantiation for nonparametric methods based on Gaussian Process Regression, and report its empirical performance results that compare favourably against existing heuristic acquisition mechanisms.