 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Irradiance Distributions for Weakly Turbulent FSO Links: Log-Normal vs. Gamma-Gamma
Oct 24, 2025Weak turbulence is commonly modeled using the log-normal distribution. Our experimental results show that this distribution fails to capture irradiance fluctuations in this regime. The Gamma-Gamma model is shown to be more accurate.
Beyond 200 Gb/s/lane: An Analytical Approach to Optimal Detection in Shaped IM-DD Optical Links with Relative Intensity Noise
Jun 24, 2025Next-generation intensity-modulation (IM) and direct-detection (DD) systems used in data centers are expected to operate at 400 Gb/s/lane and beyond. Such rates can be achieved by increasing the system bandwidth or the modulation format, which in turn requires maintaining or increasing the signal-to-noise ratio (SNR). Such SNR requirements can be achieved by increasing the transmitted optical power. This increase in optical power causes the emergence of relative intensity noise (RIN), a signal-dependent impairment inherent to the transmitter laser, which ultimately limits the performance of the system. In this paper, we develop an analytical symbol error rate (SER) expression for the optimal detector for the IM-DD optical link under study. The developed expression takes into account the signal-dependent nature of RIN and does not make any assumptions on the geometry or probability distribution of the constellation. Our expression is therefore applicable to general probabilistically and/or geometrically shaped systems. Unlike results available in the literature, our proposed expression provides a perfect match to numerical simulations of probabilistic and geometrically shaped systems.
On Error Rate Approximations for FSO Systems with Weak Turbulence and Pointing Errors
Jun 24, 2025Atmospheric attenuation, atmospheric turbulence, geometric spread, and pointing errors, degrade the performance of free-space optical transmission. In the weak turbulence regime, the probability density function describing the distribution of the channel fading coefficient that models these four effects is known in the literature. This function is an integral equation, which makes it difficult to find simple analytical expressions of important performance metrics such as the bit error rate (BER) and symbol error rate (SER). In this paper, we present simple and accurate approximations of the average BER and SER for pulse-amplitude modulation (PAM) in the weak turbulence regime for an intensity modulation and direct detection system. Our numerical results show that the proposed expressions exhibit excellent accuracy when compared against Monte Carlo simulations. To demonstrate the usefulness of the developed approximations, we perform two asymptotic analyses. First, we investigate the additional transmit power required to maintain the same SER when the spectral efficiency increases by 1 bit/symbol. Second, we study the asymptotic behavior of our SER approximation for dense PAM constellations and high transmit power.
On Geometric Shaping for 400 Gbps IM-DD Links with Laser Intensity Noise
Apr 24, 2025We propose geometric shaping for IM-DD links dominated by relative intensity noise (RIN). For 400 Gbps links, our geometrically-shaped constellations result in error probability improvements that relaxes the RIN laser design by 3 dB.
Physics-Aware Initialization Refinement in Code-Aided EM for Blind Channel Estimation
Apr 15, 2025This paper addresses the well-known local maximum problem of the expectation-maximization (EM) algorithm in blind intersymbol interference (ISI) channel estimation. This problem primarily results from phase and shift ambiguity during initialization, which blind estimation is inherently unable to distinguish. We propose an effective initialization refinement algorithm that utilizes the decoder output as a model selection metric, incorporating a technique to detect phase and shift ambiguity. Our results show that the proposed algorithm significantly reduces the number of local maximum cases to nearly one-third for a 3-tap ISI channel under highly uncertain initial conditions. The improvement becomes more pronounced as initial errors increase and the channel memory grows. When used in a turbo equalizer, the proposed algorithm is required only in the first turbo iteration, which limits any complexity increase with subsequent iterations.
On the Optimality of Single-label and Multi-label Neural Network Decoders
Mar 24, 2025We investigate the design of two neural network (NN) architectures recently proposed as decoders for forward error correction: the so-called single-label NN (SLNN) and multi-label NN (MLNN) decoders. These decoders have been reported to achieve near-optimal codeword- and bit-wise performance, respectively. Results in the literature show near-optimality for a variety of short codes. In this paper, we analytically prove that certain SLNN and MLNN architectures can, in fact, always realize optimal decoding, regardless of the code. These optimal architectures and their binary weights are shown to be defined by the codebook, i.e., no training or network optimization is required. Our proposed architectures are in fact not NNs, but a different way of implementing the maximum likelihood decoding rule. Optimal performance is numerically demonstrated for Hamming $(7,4)$, Polar $(16,8)$, and BCH $(31,21)$ codes. The results show that our optimal architectures are less complex than the SLNN and MLNN architectures proposed in the literature, which in fact only achieve near-optimal performance. Extension to longer codes is still hindered by the curse of dimensionality. Therefore, even though SLNN and MLNN can perform maximum likelihood decoding, such architectures cannot be used for medium and long codes.
Turbo Receiver Design with Joint Detection and Demapping for Coded Differential BPSK in Bursty Impulsive Noise Channels
Dec 10, 2024
It has been recognized that the impulsive noise (IN) generated by power devices poses significant challenges to wireless receivers in practice. In this paper, we assess the achievable information rate (AIR) and the performance of practical turbo receiver designs for a well-established Markov-Middleton IN model. We utilize a commonly used commercial transmission setup consisting of a convolutional encoder, bit-level interleaver, and a differential binary phase-shift keying (DBPSK) symbol mapper. Firstly, we conduct a comprehensive assessment of the AIRs of the underlying channel model using DBPSK transmitted symbols across various channel conditions. Additionally, we introduce two robust turbo-like receiver designs. The first design features a separate IN detector and a turbo-demapper-decoder. The second design employs a joint approach, where the extrinsic information of both the detector and demapper is simultaneously updated, forming a turbo-detector-demapper-decoder structure. We show that the joint design consistently outperforms the separate design across all channel conditions, particularly in low AIR situations. However, the maximum performance gain for the channel conditions considered in this paper is merely 0.2 dB, and the joint system incurs significantly greater computational complexity, especially for a high number of turbo iterations. The performance of the two proposed turbo receiver designs is demonstrated to be close to the estimated AIR, with a performance gap dependent on the channel parameters.
Modified Baum-Welch Algorithm for Joint Blind Channel Estimation and Turbo Equalization
Dec 10, 2024
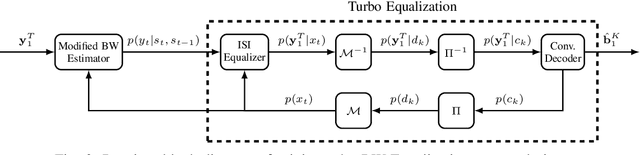
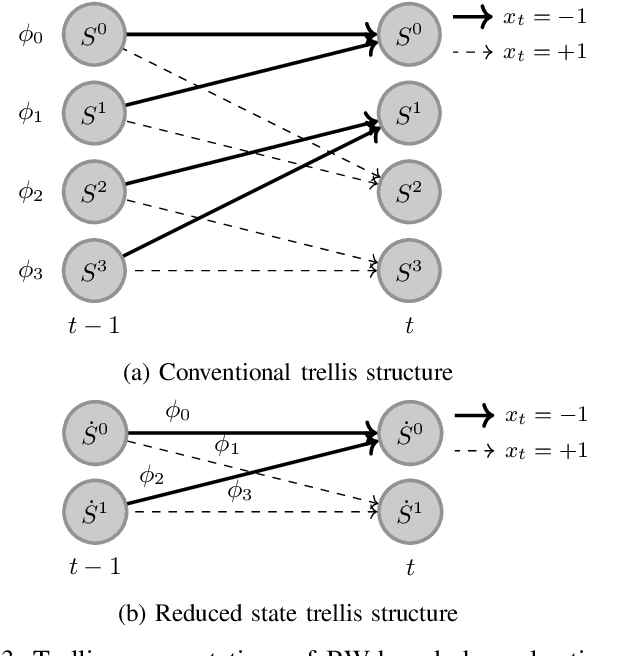
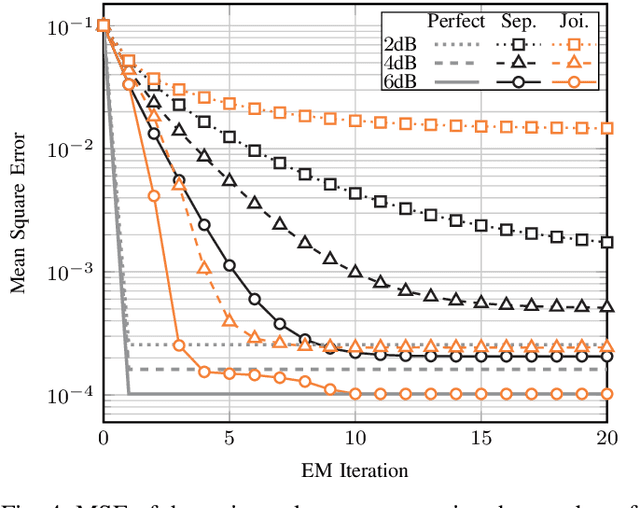
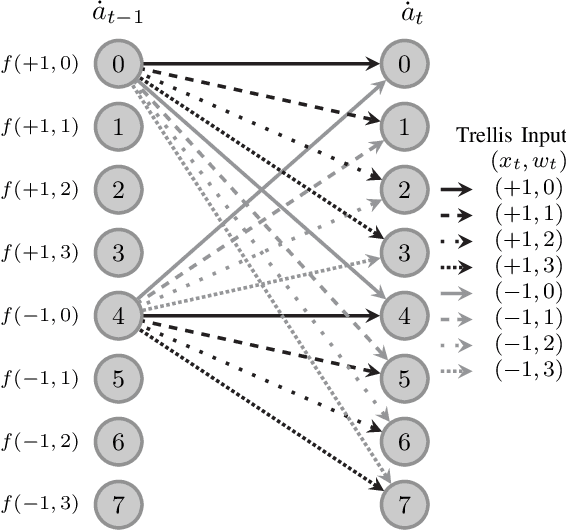
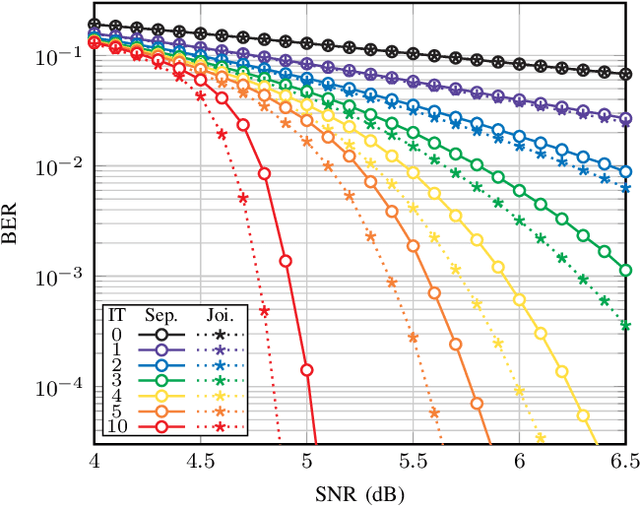
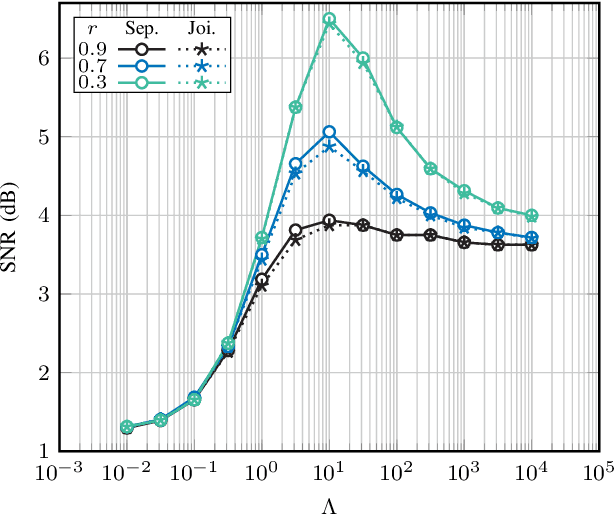
Blind estimation of intersymbol interference channels based on the Baum-Welch (BW) algorithm, a specific implementation of the expectation-maximization (EM) algorithm for training hidden Markov models, is robust and does not require labeled data. However, it is known for its extensive computation cost, slow convergence, and frequently converges to a local maximum. In this paper, we modified the trellis structure of the BW algorithm by associating the channel parameters with two consecutive states. This modification enables us to reduce the number of required states by half while maintaining the same performance. Moreover, to improve the convergence rate and the estimation performance, we construct a joint turbo-BW-equalization system by exploiting the extrinsic information produced by the turbo decoder to refine the BW-based estimator at each EM iteration. Our experiments demonstrate that the joint system achieves convergence in just 4 EM iterations, which is 8 iterations less than a separate system design for a signal-to-noise ratio (SNR) of 6 dB. Additionally, the joint system provides improved estimation accuracy with a mean square error (MSE) of $10^{-4}$. We also identify scenarios where a joint design is not preferable, especially when the channel is noisy (e.g., SNR=2 dB) and the turbo decoder is unable to provide reliable extrinsic information for a BW-based estimator.
On the Design and Performance of Machine Learning Based Error Correcting Decoders
Oct 21, 2024This paper analyzes the design and competitiveness of four neural network (NN) architectures recently proposed as decoders for forward error correction (FEC) codes. We first consider the so-called single-label neural network (SLNN) and the multi-label neural network (MLNN) decoders which have been reported to achieve near maximum likelihood (ML) performance. Here, we show analytically that SLNN and MLNN decoders can always achieve ML performance, regardless of the code dimensions -- although at the cost of computational complexity -- and no training is in fact required. We then turn our attention to two transformer-based decoders: the error correction code transformer (ECCT) and the cross-attention message passing transformer (CrossMPT). We compare their performance against traditional decoders, and show that ordered statistics decoding outperforms these transformer-based decoders. The results in this paper cast serious doubts on the application of NN-based FEC decoders in the short and medium block length regime.
On the Capacity of Correlated MIMO Phase-Noise Channels: An Electro-Optic Frequency Comb Example
May 09, 2024The capacity of a discrete-time multiple-input-multiple-output channel with correlated phase noises is investigated. In particular, the electro-optic frequency comb system is considered, where the phase noise of each channel is a combination of two independent Wiener phase-noise sources. Capacity upper and lower bounds are derived for this channel and are compared with lower bounds obtained by numerically evaluating the achievable information rates using quadrature amplitude modulation constellations. Capacity upper and lower bounds are provided for the high signal-to-noise ratio (SNR) regime. The multiplexing gain (pre-log) is shown to be $M-1$, where $M$ represents the number of channels. A constant gap between the asymptotic upper and lower bounds is observed, which depends on the number of channels $M$. For the specific case of $M=2$, capacity is characterized up to a term that vanishes as the SNR grows large.