 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Complexity of Composite Quantum Hypothesis Testing
Jan 13, 2026This paper investigates symmetric composite binary quantum hypothesis testing (QHT), where the goal is to determine which of two uncertainty sets contains an unknown quantum state. While asymptotic error exponents for this problem are well-studied, the finite-sample regime remains poorly understood. We bridge this gap by characterizing the sample complexity -- the minimum number of state copies required to achieve a target error level. Specifically, we derive lower bounds that generalize the sample complexity of simple QHT and introduce new upper bounds for various uncertainty sets, including of both finite and infinite cardinalities. Notably, our upper and lower bounds match up to universal constants, providing a tight characterization of the sample complexity. Finally, we extend our analysis to the differentially private setting, establishing the sample complexity for privacy-preserving composite QHT.
Quantum-Enhanced Neural Contextual Bandit Algorithms
Jan 06, 2026Stochastic contextual bandits are fundamental for sequential decision-making but pose significant challenges for existing neural network-based algorithms, particularly when scaling to quantum neural networks (QNNs) due to issues such as massive over-parameterization, computational instability, and the barren plateau phenomenon. This paper introduces the Quantum Neural Tangent Kernel-Upper Confidence Bound (QNTK-UCB) algorithm, a novel algorithm that leverages the Quantum Neural Tangent Kernel (QNTK) to address these limitations. By freezing the QNN at a random initialization and utilizing its static QNTK as a kernel for ridge regression, QNTK-UCB bypasses the unstable training dynamics inherent in explicit parameterized quantum circuit training while fully exploiting the unique quantum inductive bias. For a time horizon $T$ and $K$ actions, our theoretical analysis reveals a significantly improved parameter scaling of $Ω((TK)^3)$ for QNTK-UCB, a substantial reduction compared to $Ω((TK)^8)$ required by classical NeuralUCB algorithms for similar regret guarantees. Empirical evaluations on non-linear synthetic benchmarks and quantum-native variational quantum eigensolver tasks demonstrate QNTK-UCB's superior sample efficiency in low-data regimes. This work highlights how the inherent properties of QNTK provide implicit regularization and a sharper spectral decay, paving the way for achieving ``quantum advantage'' in online learning.
QCA-MolGAN: Quantum Circuit Associative Molecular GAN with Multi-Agent Reinforcement Learning
Sep 05, 2025Navigating the vast chemical space of molecular structures to design novel drug molecules with desired target properties remains a central challenge in drug discovery. Recent advances in generative models offer promising solutions. This work presents a novel quantum circuit Born machine (QCBM)-enabled Generative Adversarial Network (GAN), called QCA-MolGAN, for generating drug-like molecules. The QCBM serves as a learnable prior distribution, which is associatively trained to define a latent space aligning with high-level features captured by the GANs discriminator. Additionally, we integrate a novel multi-agent reinforcement learning network to guide molecular generation with desired targeted properties, optimising key metrics such as quantitative estimate of drug-likeness (QED), octanol-water partition coefficient (LogP) and synthetic accessibility (SA) scores in conjunction with one another. Experimental results demonstrate that our approach enhances the property alignment of generated molecules with the multi-agent reinforcement learning agents effectively balancing chemical properties.
On the Generalization of Adversarially Trained Quantum Classifiers
Apr 24, 2025



Quantum classifiers are vulnerable to adversarial attacks that manipulate their input classical or quantum data. A promising countermeasure is adversarial training, where quantum classifiers are trained by using an attack-aware, adversarial loss function. This work establishes novel bounds on the generalization error of adversarially trained quantum classifiers when tested in the presence of perturbation-constrained adversaries. The bounds quantify the excess generalization error incurred to ensure robustness to adversarial attacks as scaling with the training sample size $m$ as $1/\sqrt{m}$, while yielding insights into the impact of the quantum embedding. For quantum binary classifiers employing \textit{rotation embedding}, we find that, in the presence of adversarial attacks on classical inputs $\mathbf{x}$, the increase in sample complexity due to adversarial training over conventional training vanishes in the limit of high dimensional inputs $\mathbf{x}$. In contrast, when the adversary can directly attack the quantum state $\rho(\mathbf{x})$ encoding the input $\mathbf{x}$, the excess generalization error depends on the choice of embedding only through its Hilbert space dimension. The results are also extended to multi-class classifiers. We validate our theoretical findings with numerical experiments.
Neural Contextual Bandits Under Delayed Feedback Constraints
Apr 16, 2025This paper presents a new algorithm for neural contextual bandits (CBs) that addresses the challenge of delayed reward feedback, where the reward for a chosen action is revealed after a random, unknown delay. This scenario is common in applications such as online recommendation systems and clinical trials, where reward feedback is delayed because the outcomes or results of a user's actions (such as recommendations or treatment responses) take time to manifest and be measured. The proposed algorithm, called Delayed NeuralUCB, uses an upper confidence bound (UCB)-based exploration strategy. Under the assumption of independent and identically distributed sub-exponential reward delays, we derive an upper bound on the cumulative regret over a T-length horizon. We further consider a variant of the algorithm, called Delayed NeuralTS, that uses Thompson Sampling-based exploration. Numerical experiments on real-world datasets, such as MNIST and Mushroom, along with comparisons to benchmark approaches, demonstrate that the proposed algorithms effectively manage varying delays and are well-suited for complex real-world scenarios.
VAE-QWGAN: Improving Quantum GANs for High Resolution Image Generation
Sep 16, 2024This paper presents a novel hybrid quantum generative model, the VAE-QWGAN, which combines the strengths of a classical Variational AutoEncoder (VAE) with a hybrid Quantum Wasserstein Generative Adversarial Network (QWGAN). The VAE-QWGAN integrates the VAE decoder and QGAN generator into a single quantum model with shared parameters, utilizing the VAE's encoder for latent vector sampling during training. To generate new data from the trained model at inference, input latent vectors are sampled from a Gaussian Mixture Model (GMM), learnt on the training latent vectors. This, in turn, enhances the diversity and quality of generated images. We evaluate the model's performance on MNIST/Fashion-MNIST datasets, and demonstrate improved quality and diversity of generated images compared to existing approaches.
Adversarial Quantum Machine Learning: An Information-Theoretic Generalization Analysis
Jan 31, 2024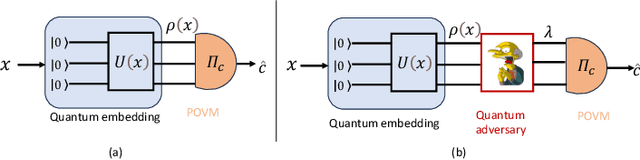
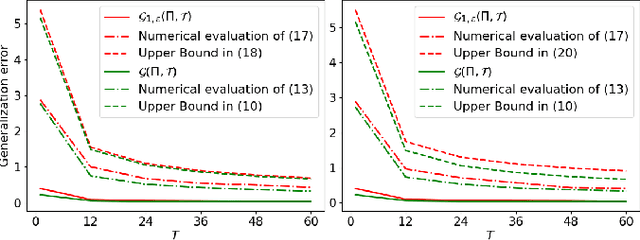
In a manner analogous to their classical counterparts, quantum classifiers are vulnerable to adversarial attacks that perturb their inputs. A promising countermeasure is to train the quantum classifier by adopting an attack-aware, or adversarial, loss function. This paper studies the generalization properties of quantum classifiers that are adversarially trained against bounded-norm white-box attacks. Specifically, a quantum adversary maximizes the classifier's loss by transforming an input state $\rho(x)$ into a state $\lambda$ that is $\epsilon$-close to the original state $\rho(x)$ in $p$-Schatten distance. Under suitable assumptions on the quantum embedding $\rho(x)$, we derive novel information-theoretic upper bounds on the generalization error of adversarially trained quantum classifiers for $p = 1$ and $p = \infty$. The derived upper bounds consist of two terms: the first is an exponential function of the 2-R\'enyi mutual information between classical data and quantum embedding, while the second term scales linearly with the adversarial perturbation size $\epsilon$. Both terms are shown to decrease as $1/\sqrt{T}$ over the training set size $T$ . An extension is also considered in which the adversary assumed during training has different parameters $p$ and $\epsilon$ as compared to the adversary affecting the test inputs. Finally, we validate our theoretical findings with numerical experiments for a synthetic setting.
Thompson Sampling for Stochastic Bandits with Noisy Contexts: An Information-Theoretic Regret Analysis
Jan 21, 2024We explore a stochastic contextual linear bandit problem where the agent observes a noisy, corrupted version of the true context through a noise channel with an unknown noise parameter. Our objective is to design an action policy that can approximate" that of an oracle, which has access to the reward model, the channel parameter, and the predictive distribution of the true context from the observed noisy context. In a Bayesian framework, we introduce a Thompson sampling algorithm for Gaussian bandits with Gaussian context noise. Adopting an information-theoretic analysis, we demonstrate the Bayesian regret of our algorithm concerning the oracle's action policy. We also extend this problem to a scenario where the agent observes the true context with some delay after receiving the reward and show that delayed true contexts lead to lower Bayesian regret. Finally, we empirically demonstrate the performance of the proposed algorithms against baselines.
Statistical Complexity of Quantum Learning
Sep 20, 2023Recent years have seen significant activity on the problem of using data for the purpose of learning properties of quantum systems or of processing classical or quantum data via quantum computing. As in classical learning, quantum learning problems involve settings in which the mechanism generating the data is unknown, and the main goal of a learning algorithm is to ensure satisfactory accuracy levels when only given access to data and, possibly, side information such as expert knowledge. This article reviews the complexity of quantum learning using information-theoretic techniques by focusing on data complexity, copy complexity, and model complexity. Copy complexity arises from the destructive nature of quantum measurements, which irreversibly alter the state to be processed, limiting the information that can be extracted about quantum data. For example, in a quantum system, unlike in classical machine learning, it is generally not possible to evaluate the training loss simultaneously on multiple hypotheses using the same quantum data. To make the paper self-contained and approachable by different research communities, we provide extensive background material on classical results from statistical learning theory, as well as on the distinguishability of quantum states. Throughout, we highlight the differences between quantum and classical learning by addressing both supervised and unsupervised learning, and we provide extensive pointers to the literature.
Bayesian and Multi-Armed Contextual Meta-Optimization for Efficient Wireless Radio Resource Management
Jan 16, 2023



Optimal resource allocation in modern communication networks calls for the optimization of objective functions that are only accessible via costly separate evaluations for each candidate solution. The conventional approach carries out the optimization of resource-allocation parameters for each system configuration, characterized, e.g., by topology and traffic statistics, using global search methods such as Bayesian optimization (BO). These methods tend to require a large number of iterations, and hence a large number of key performance indicator (KPI) evaluations. In this paper, we propose the use of meta-learning to transfer knowledge from data collected from related, but distinct, configurations in order to speed up optimization on new network configurations. Specifically, we combine meta-learning with BO, as well as with multi-armed bandit (MAB) optimization, with the latter having the potential advantage of operating directly on a discrete search space. Furthermore, we introduce novel contextual meta-BO and meta-MAB algorithms, in which transfer of knowledge across configurations occurs at the level of a mapping from graph-based contextual information to resource-allocation parameters. Experiments for the problem of open loop power control (OLPC) parameter optimization for the uplink of multi-cell multi-antenna systems provide insights into the potential benefits of meta-learning and contextual optimization.