 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-QALM: A Benchmark to Assess Clinical Reading Comprehension and Knowledge Recall in Large Language Models via Question Answering
Jun 06, 2024

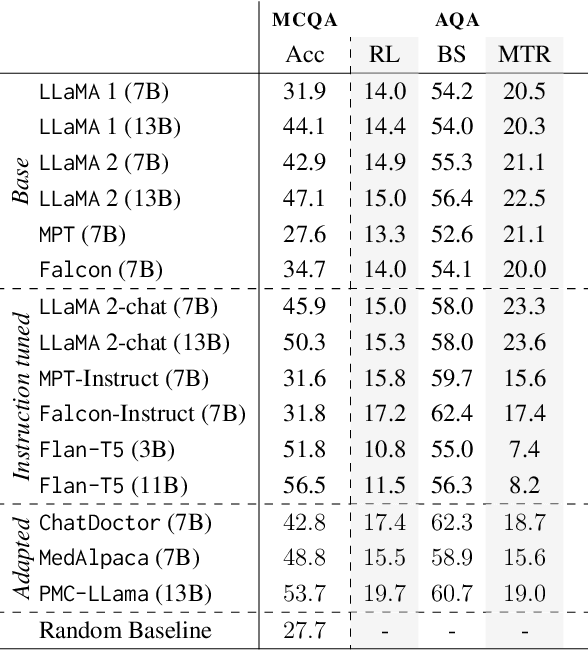

There is vivid research on adapting Large Language Models (LLMs) to perform a variety of tasks in high-stakes domains such as healthcare. Despite their popularity, there is a lack of understanding of the extent and contributing factors that allow LLMs to recall relevant knowledge and combine it with presented information in the clinical and biomedical domain: a fundamental pre-requisite for success on down-stream tasks. Addressing this gap, we use Multiple Choice and Abstractive Question Answering to conduct a large-scale empirical study on 22 datasets in three generalist and three specialist biomedical sub-domains. Our multifaceted analysis of the performance of 15 LLMs, further broken down by sub-domain, source of knowledge and model architecture, uncovers success factors such as instruction tuning that lead to improved recall and comprehension. We further show that while recently proposed domain-adapted models may lack adequate knowledge, directly fine-tuning on our collected medical knowledge datasets shows encouraging results, even generalising to unseen specialist sub-domains. We complement the quantitative results with a skill-oriented manual error analysis, which reveals a significant gap between the models' capabilities to simply recall necessary knowledge and to integrate it with the presented context. To foster research and collaboration in this field we share M-QALM, our resources, standardised methodology, and evaluation results, with the research community to facilitate further advancements in clinical knowledge representation learning within language models.
PULSAR at MEDIQA-Sum 2023: Large Language Models Augmented by Synthetic Dialogue Convert Patient Dialogues to Medical Records
Jul 05, 2023


This paper describes PULSAR, our system submission at the ImageClef 2023 MediQA-Sum task on summarising patient-doctor dialogues into clinical records. The proposed framework relies on domain-specific pre-training, to produce a specialised language model which is trained on task-specific natural data augmented by synthetic data generated by a black-box LLM. We find limited evidence towards the efficacy of domain-specific pre-training and data augmentation, while scaling up the language model yields the best performance gains. Our approach was ranked second and third among 13 submissions on task B of the challenge. Our code is available at https://github.com/yuping-wu/PULSAR.
A translational pathway of deep learning methods in GastroIntestinal Endoscopy
Oct 12, 2020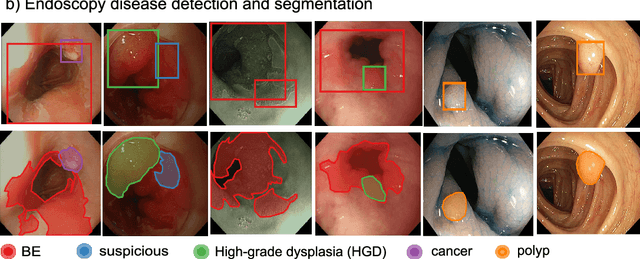
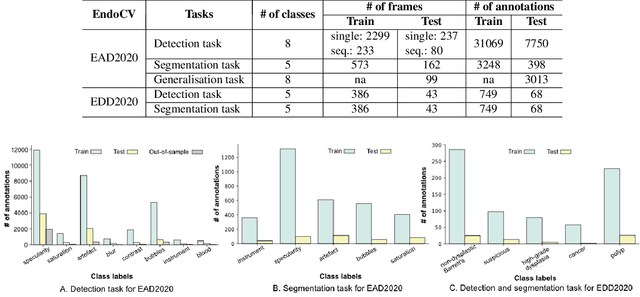
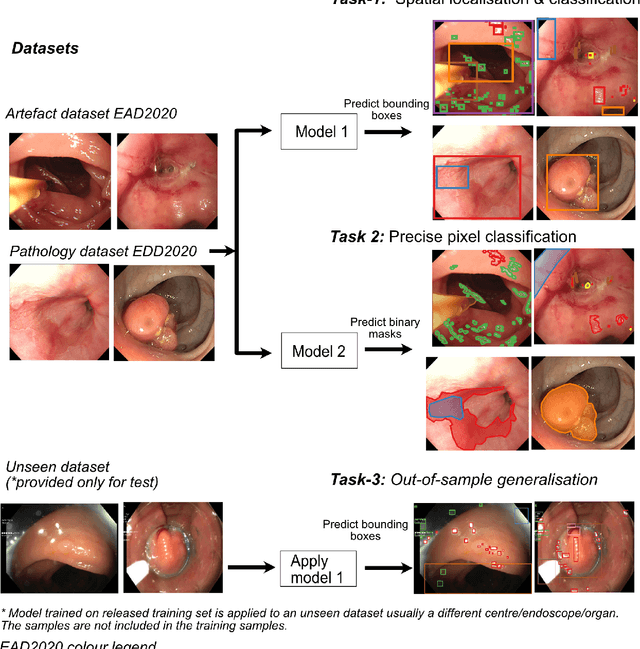
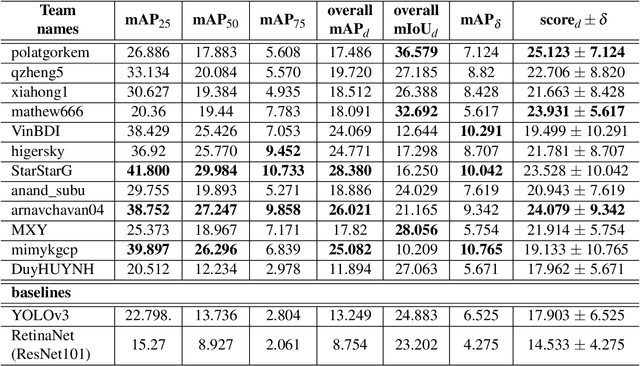
The Endoscopy Computer Vision Challenge (EndoCV) is a crowd-sourcing initiative to address eminent problems in developing reliable computer aided detection and diagnosis endoscopy systems and suggest a pathway for clinical translation of technologies. Whilst endoscopy is a widely used diagnostic and treatment tool for hollow-organs, there are several core challenges often faced by endoscopists, mainly: 1) presence of multi-class artefacts that hinder their visual interpretation, and 2) difficulty in identifying subtle precancerous precursors and cancer abnormalities. Artefacts often affect the robustness of deep learning methods applied to the gastrointestinal tract organs as they can be confused with tissue of interest. EndoCV2020 challenges are designed to address research questions in these remits. In this paper, we present a summary of methods developed by the top 17 teams and provide an objective comparison of state-of-the-art methods and methods designed by the participants for two sub-challenges: i) artefact detection and segmentation (EAD2020), and ii) disease detection and segmentation (EDD2020). Multi-center, multi-organ, multi-class, and multi-modal clinical endoscopy datasets were compiled for both EAD2020 and EDD2020 sub-challenges. An out-of-sample generalisation ability of detection algorithms was also evaluated. Whilst most teams focused on accuracy improvements, only a few methods hold credibility for clinical usability. The best performing teams provided solutions to tackle class imbalance, and variabilities in size, origin, modality and occurrences by exploring data augmentation, data fusion, and optimal class thresholding techniques.
A simple and effective hybrid genetic search for the job sequencing and tool switching problem
Oct 10, 2019
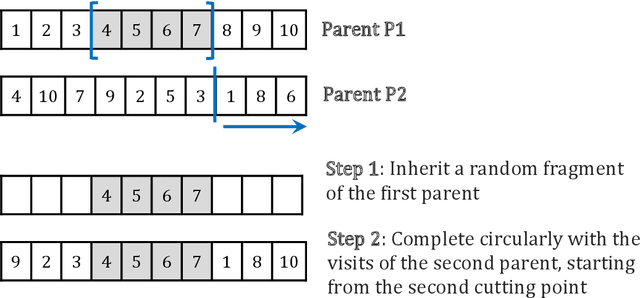
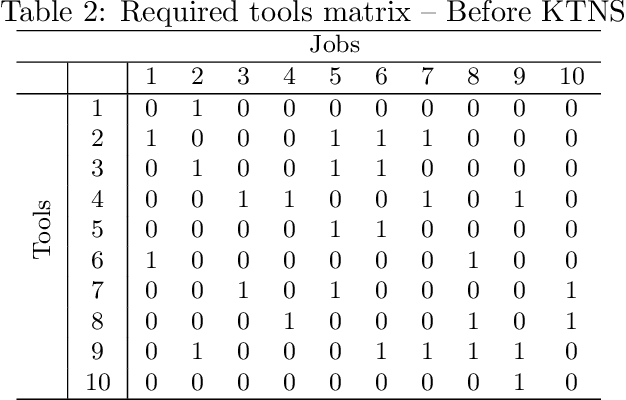
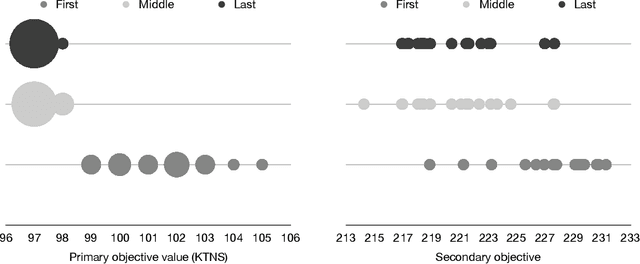
The job sequencing and tool switching problem (SSP) has been extensively studied in the field of operations research, due to its practical relevance and methodological interest. Given a machine that can load a limited amount of tools simultaneously and a number of jobs that require a subset of the available tools, the SSP seeks a job sequence that minimizes the number of tool switches in the machine. To solve this problem, we propose a simple and efficient hybrid genetic search based on a generic solution representation, a tailored decoding operator, efficient local searches and diversity management techniques. To guide the search, we introduce a secondary objective designed to break ties. These techniques allow to explore structurally different solutions and escape local optima. As shown in our computational experiments on classical benchmark instances, our algorithm significantly outperforms all previous approaches while remaining simple to apprehend and easy to implement. We finally report results on a new set of larger instances to stimulate future research and comparative analyses.
A unified heuristic and an annotated bibliography for a large class of earliness-tardiness scheduling problems
Jan 10, 2017
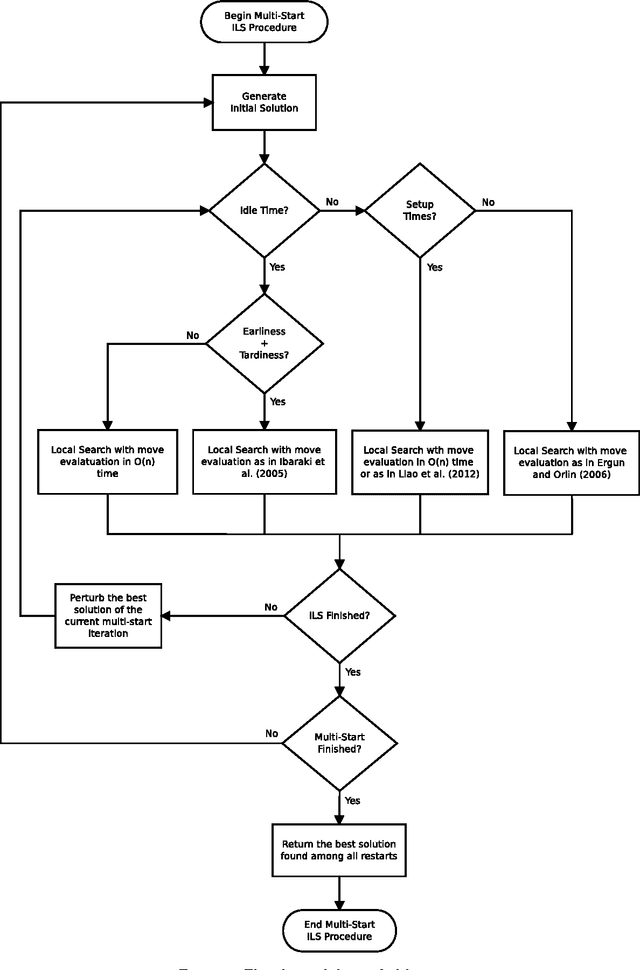
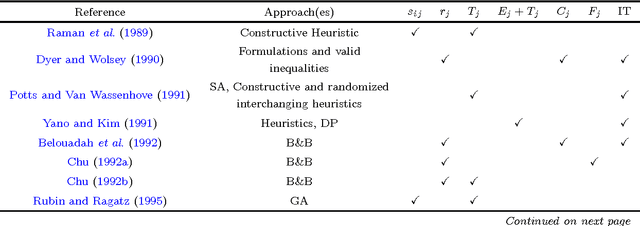

This work proposes a unified heuristic algorithm for a large class of earliness-tardiness (E-T) scheduling problems. We consider single/parallel machine E-T problems that may or may not consider some additional features such as idle time, setup times and release dates. In addition, we also consider those problems whose objective is to minimize either the total (average) weighted completion time or the total (average) weighted flow time, which arise as particular cases when the due dates of all jobs are either set to zero or to their associated release dates, respectively. The developed local search based metaheuristic framework is quite simple, but at the same time relies on sophisticated procedures for efficiently performing local search according to the characteristics of the problem. We present efficient move evaluation approaches for some parallel machine problems that generalize the existing ones for single machine problems. The algorithm was tested in hundreds of instances of several E-T problems and particular cases. The results obtained show that our unified heuristic is capable of producing high quality solutions when compared to the best ones available in the literature that were obtained by specific methods. Moreover, we provide an extensive annotated bibliography on the problems related to those considered in this work, where we not only indicate the approach(es) used in each publication, but we also point out the characteristics of the problem(s) considered. Beyond that, we classify the existing methods in different categories so as to have a better idea of the popularity of each type of solution procedure.
A heuristic algorithm for a single vehicle static bike sharing rebalancing problem
May 04, 2016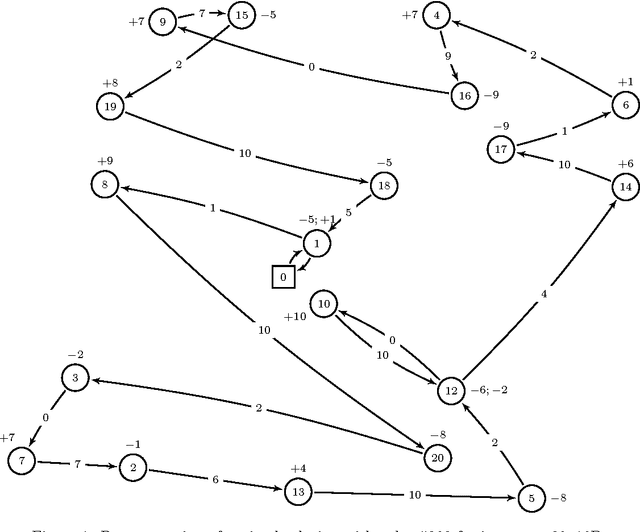
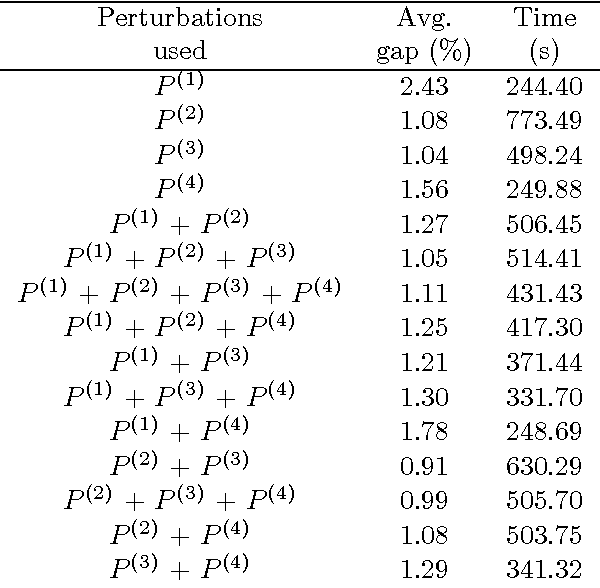
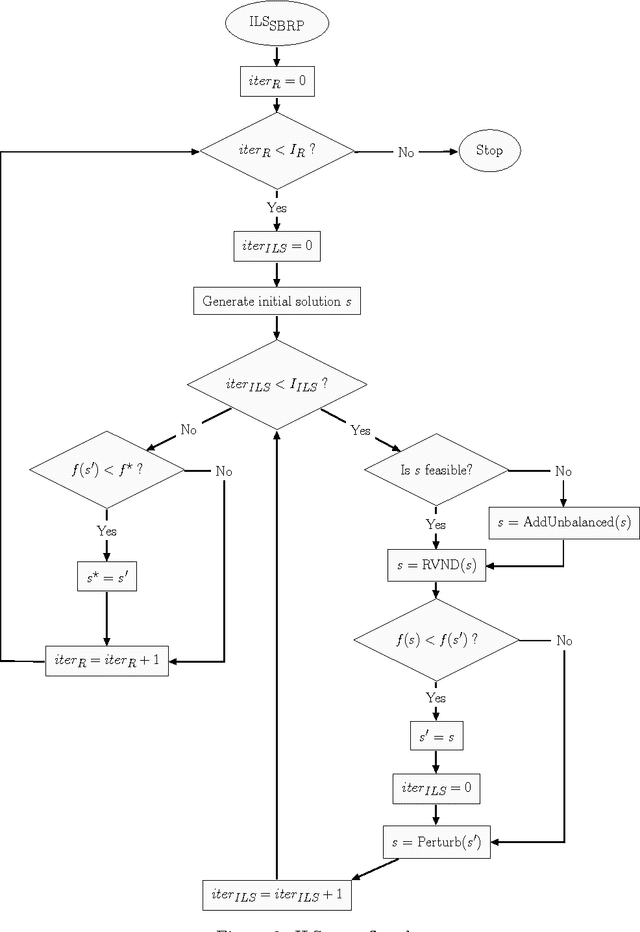
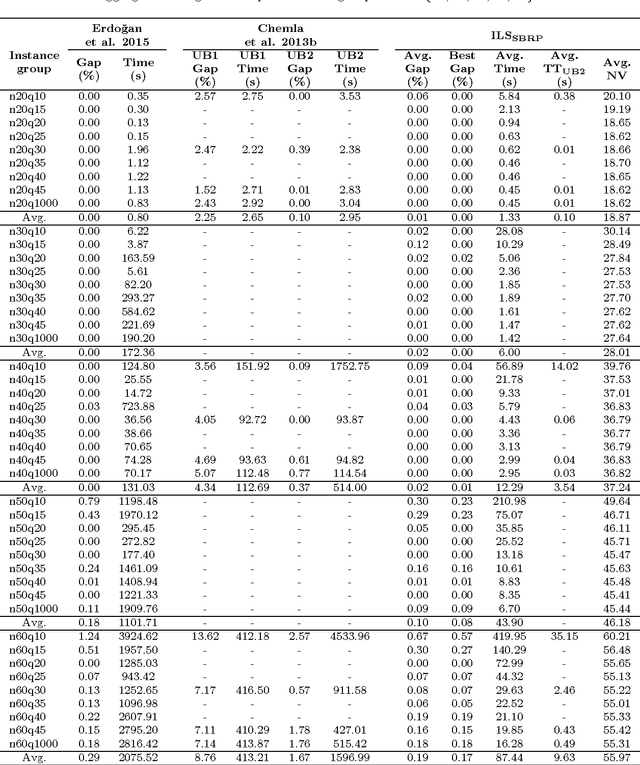
The static bike rebalancing problem (SBRP) concerns the task of repositioning bikes among stations in self-service bike-sharing systems. This problem can be seen as a variant of the one-commodity pickup and delivery vehicle routing problem, where multiple visits are allowed to be performed at each station, i.e., the demand of a station is allowed to be split. Moreover, a vehicle may temporarily drop its load at a station, leaving it in excess or, alternatively, collect more bikes from a station (even all of them), thus leaving it in default. Both cases require further visits in order to meet the actual demands of such station. This paper deals with a particular case of the SBRP, in which only a single vehicle is available and the objective is to find a least-cost route that meets the demand of all stations and does not violate the minimum (zero) and maximum (vehicle capacity) load limits along the tour. Therefore, the number of bikes to be collected or delivered at each station should be appropriately determined in order to respect such constraints. We propose an iterated local search (ILS) based heuristic to solve the problem. The ILS algorithm was tested on 980 benchmark instances from the literature and the results obtained are quite competitive when compared to other existing methods. Moreover, our heuristic was capable of finding most of the known optimal solutions and also of improving the results on a number of open instances.
Efficient local search limitation strategy for single machine total weighted tardiness scheduling with sequence-dependent setup times
Nov 30, 2015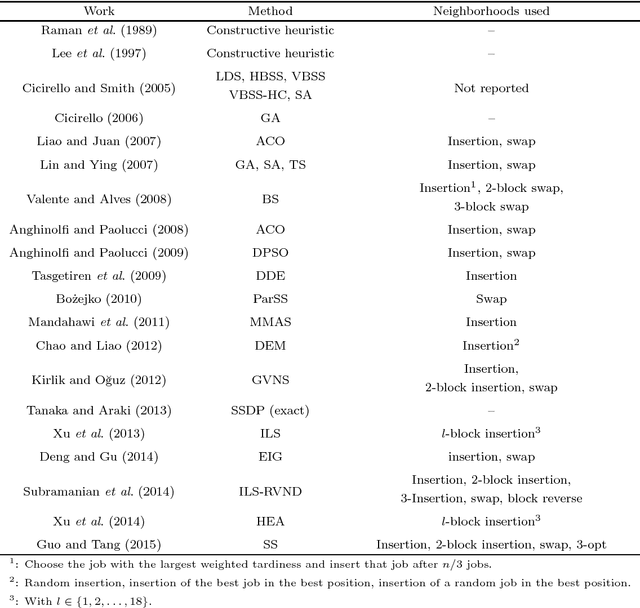

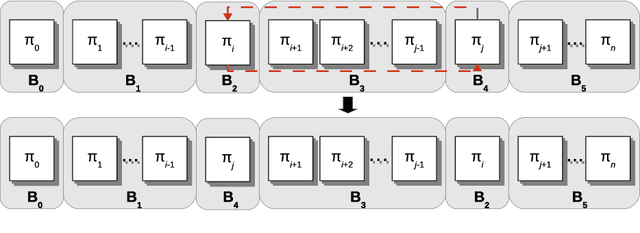
This paper concerns the single machine total weighted tardiness scheduling with sequence-dependent setup times, usually referred as $1|s_{ij}|\sum w_jT_j$. In this $\mathcal{NP}$-hard problem, each job has an associated processing time, due date and a weight. For each pair of jobs $i$ and $j$, there may be a setup time before starting to process $j$ in case this job is scheduled immediately after $i$. The objective is to determine a schedule that minimizes the total weighted tardiness, where the tardiness of a job is equal to its completion time minus its due date, in case the job is completely processed only after its due date, and is equal to zero otherwise. Due to its complexity, this problem is most commonly solved by heuristics. The aim of this work is to develop a simple yet effective limitation strategy that speeds up the local search procedure without a significant loss in the solution quality. Such strategy consists of a filtering mechanism that prevents unpromising moves to be evaluated. The proposed strategy has been embedded in a local search based metaheuristic from the literature and tested in classical benchmark instances. Computational experiments revealed that the limitation strategy enabled the metaheuristic to be extremely competitive when compared to other algorithms from the literature, since it allowed the use of a large number of neighborhood structures without a significant increase in the CPU time and, consequently, high quality solutions could be achieved in a matter of seconds. In addition, we analyzed the effectiveness of the proposed strategy in two other well-known metaheuristics. Further experiments were also carried out on benchmark instances of problem $1|s_{ij}|\sum T_j$.
Hybrid Metaheuristics for the Clustered Vehicle Routing Problem
Apr 26, 2014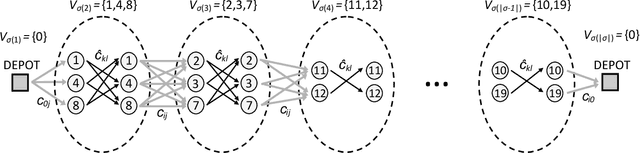
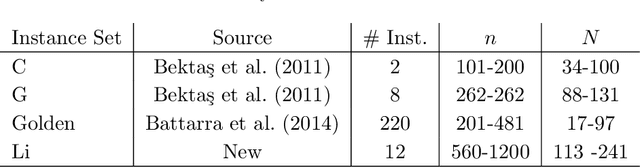
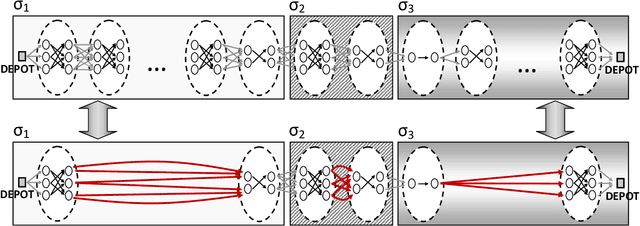
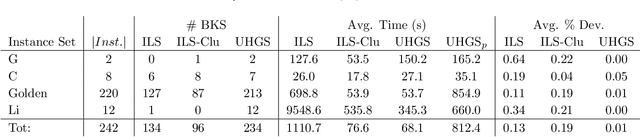
The Clustered Vehicle Routing Problem (CluVRP) is a variant of the Capacitated Vehicle Routing Problem in which customers are grouped into clusters. Each cluster has to be visited once, and a vehicle entering a cluster cannot leave it until all customers have been visited. This article presents two alternative hybrid metaheuristic algorithms for the CluVRP. The first algorithm is based on an Iterated Local Search algorithm, in which only feasible solutions are explored and problem-specific local search moves are utilized. The second algorithm is a Hybrid Genetic Search, for which the shortest Hamiltonian path between each pair of vertices within each cluster should be precomputed. Using this information, a sequence of clusters can be used as a solution representation and large neighborhoods can be efficiently explored by means of bi-directional dynamic programming, sequence concatenations, by using appropriate data structures. Extensive computational experiments are performed on benchmark instances from the literature, as well as new large scale ones. Recommendations on promising algorithm choices are provided relatively to average cluster size.