 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
aMUSEd: An Open MUSE Reproduction
Jan 03, 2024



We present aMUSEd, an open-source, lightweight masked image model (MIM) for text-to-image generation based on MUSE. With 10 percent of MUSE's parameters, aMUSEd is focused on fast image generation. We believe MIM is under-explored compared to latent diffusion, the prevailing approach for text-to-image generation. Compared to latent diffusion, MIM requires fewer inference steps and is more interpretable. Additionally, MIM can be fine-tuned to learn additional styles with only a single image. We hope to encourage further exploration of MIM by demonstrating its effectiveness on large-scale text-to-image generation and releasing reproducible training code. We also release checkpoints for two models which directly produce images at 256x256 and 512x512 resolutions.
LCM-LoRA: A Universal Stable-Diffusion Acceleration Module
Nov 09, 2023



Latent Consistency Models (LCMs) have achieved impressive performance in accelerating text-to-image generative tasks, producing high-quality images with minimal inference steps. LCMs are distilled from pre-trained latent diffusion models (LDMs), requiring only ~32 A100 GPU training hours. This report further extends LCMs' potential in two aspects: First, by applying LoRA distillation to Stable-Diffusion models including SD-V1.5, SSD-1B, and SDXL, we have expanded LCM's scope to larger models with significantly less memory consumption, achieving superior image generation quality. Second, we identify the LoRA parameters obtained through LCM distillation as a universal Stable-Diffusion acceleration module, named LCM-LoRA. LCM-LoRA can be directly plugged into various Stable-Diffusion fine-tuned models or LoRAs without training, thus representing a universally applicable accelerator for diverse image generation tasks. Compared with previous numerical PF-ODE solvers such as DDIM, DPM-Solver, LCM-LoRA can be viewed as a plug-in neural PF-ODE solver that possesses strong generalization abilities. Project page: https://github.com/luosiallen/latent-consistency-model.
Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling
Nov 01, 2023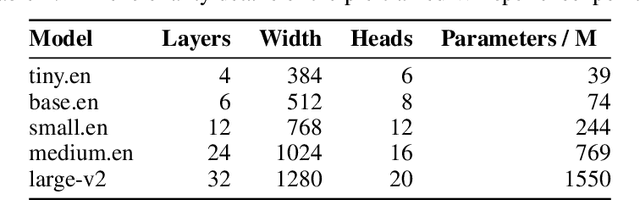
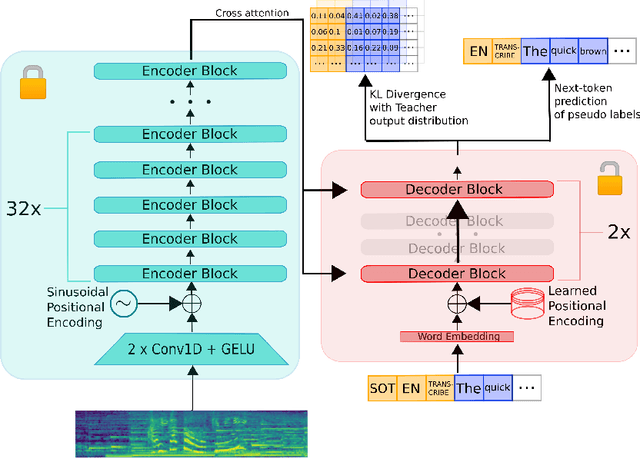
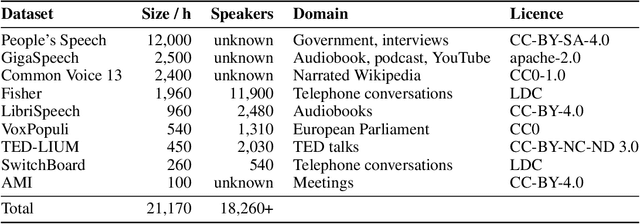
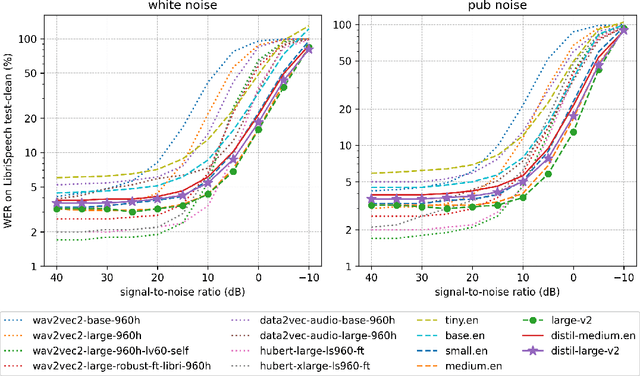
As the size of pre-trained speech recognition models increases, running these large models in low-latency or resource-constrained environments becomes challenging. In this work, we leverage pseudo-labelling to assemble a large-scale open-source dataset which we use to distill the Whisper model into a smaller variant, called Distil-Whisper. Using a simple word error rate (WER) heuristic, we select only the highest quality pseudo-labels for training. The distilled model is 5.8 times faster with 51% fewer parameters, while performing to within 1% WER on out-of-distribution test data in a zero-shot transfer setting. Distil-Whisper maintains the robustness of the Whisper model to difficult acoustic conditions, while being less prone to hallucination errors on long-form audio. Distil-Whisper is designed to be paired with Whisper for speculative decoding, yielding a 2 times speed-up while mathematically ensuring the same outputs as the original model. To facilitate further research in this domain, we make our training code, inference code and models publicly accessible.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
ESB: A Benchmark For Multi-Domain End-to-End Speech Recognition
Oct 24, 2022Speech recognition applications cover a range of different audio and text distributions, with different speaking styles, background noise, transcription punctuation and character casing. However, many speech recognition systems require dataset-specific tuning (audio filtering, punctuation removal and normalisation of casing), therefore assuming a-priori knowledge of both the audio and text distributions. This tuning requirement can lead to systems failing to generalise to other datasets and domains. To promote the development of multi-domain speech systems, we introduce the End-to-end Speech Benchmark (ESB) for evaluating the performance of a single automatic speech recognition (ASR) system across a broad set of speech datasets. Benchmarked systems must use the same data pre- and post-processing algorithm across datasets - assuming the audio and text data distributions are a-priori unknown. We compare a series of state-of-the-art (SoTA) end-to-end (E2E) systems on this benchmark, demonstrating how a single speech system can be applied and evaluated on a wide range of data distributions. We find E2E systems to be effective across datasets: in a fair comparison, E2E systems achieve within 2.6% of SoTA systems tuned to a specific dataset. Our analysis reveals that transcription artefacts, such as punctuation and casing, pose difficulties for ASR systems and should be included in evaluation. We believe E2E benchmarking over a range of datasets promotes the research of multi-domain speech recognition systems. ESB is available at https://huggingface.co/esb.