 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCM-LoRA: A Universal Stable-Diffusion Acceleration Module
Nov 09, 2023



Latent Consistency Models (LCMs) have achieved impressive performance in accelerating text-to-image generative tasks, producing high-quality images with minimal inference steps. LCMs are distilled from pre-trained latent diffusion models (LDMs), requiring only ~32 A100 GPU training hours. This report further extends LCMs' potential in two aspects: First, by applying LoRA distillation to Stable-Diffusion models including SD-V1.5, SSD-1B, and SDXL, we have expanded LCM's scope to larger models with significantly less memory consumption, achieving superior image generation quality. Second, we identify the LoRA parameters obtained through LCM distillation as a universal Stable-Diffusion acceleration module, named LCM-LoRA. LCM-LoRA can be directly plugged into various Stable-Diffusion fine-tuned models or LoRAs without training, thus representing a universally applicable accelerator for diverse image generation tasks. Compared with previous numerical PF-ODE solvers such as DDIM, DPM-Solver, LCM-LoRA can be viewed as a plug-in neural PF-ODE solver that possesses strong generalization abilities. Project page: https://github.com/luosiallen/latent-consistency-model.
One is More: Diverse Perspectives within a Single Network for Efficient DRL
Oct 29, 2023

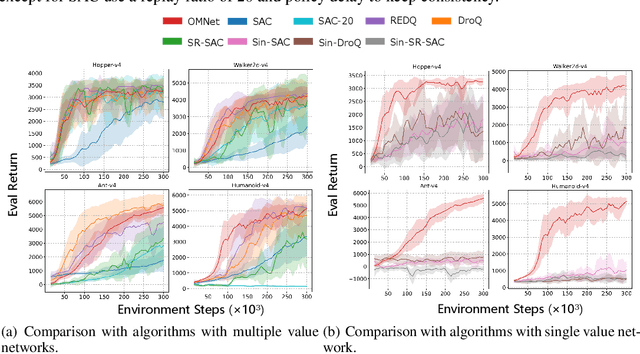
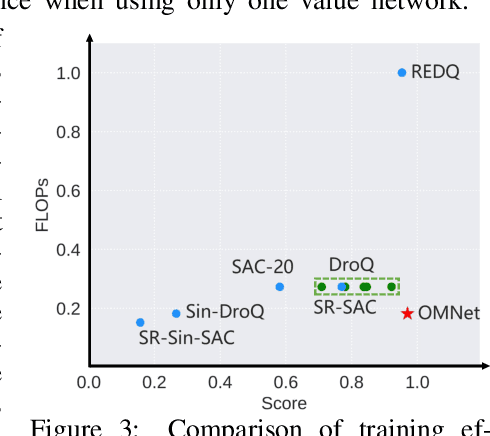
Deep reinforcement learning has achieved remarkable performance in various domains by leveraging deep neural networks for approximating value functions and policies. However, using neural networks to approximate value functions or policy functions still faces challenges, including low sample efficiency and overfitting. In this paper, we introduce OMNet, a novel learning paradigm utilizing multiple subnetworks within a single network, offering diverse outputs efficiently. We provide a systematic pipeline, including initialization, training, and sampling with OMNet. OMNet can be easily applied to various deep reinforcement learning algorithms with minimal additional overhead. Through comprehensive evaluations conducted on MuJoCo benchmark, our findings highlight OMNet's ability to strike an effective balance between performance and computational cost.
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Oct 06, 2023



Latent Diffusion models (LDMs) have achieved remarkable results in synthesizing high-resolution images. However, the iterative sampling process is computationally intensive and leads to slow generation. Inspired by Consistency Models (song et al.), we propose Latent Consistency Models (LCMs), enabling swift inference with minimal steps on any pre-trained LDMs, including Stable Diffusion (rombach et al). Viewing the guided reverse diffusion process as solving an augmented probability flow ODE (PF-ODE), LCMs are designed to directly predict the solution of such ODE in latent space, mitigating the need for numerous iterations and allowing rapid, high-fidelity sampling. Efficiently distilled from pre-trained classifier-free guided diffusion models, a high-quality 768 x 768 2~4-step LCM takes only 32 A100 GPU hours for training. Furthermore, we introduce Latent Consistency Fine-tuning (LCF), a novel method that is tailored for fine-tuning LCMs on customized image datasets. Evaluation on the LAION-5B-Aesthetics dataset demonstrates that LCMs achieve state-of-the-art text-to-image generation performance with few-step inference. Project Page: https://latent-consistency-models.github.io/
RLx2: Training a Sparse Deep Reinforcement Learning Model from Scratch
May 30, 2022
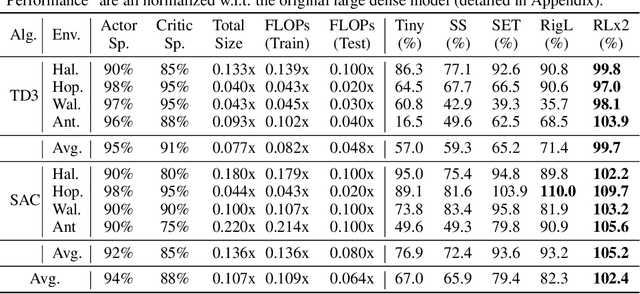
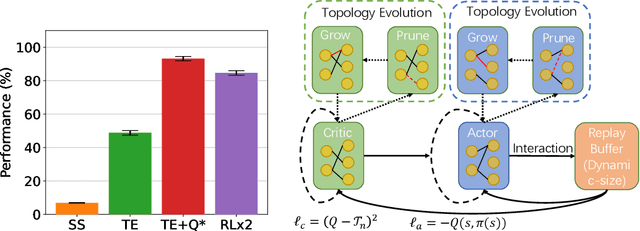

Training deep reinforcement learning (DRL) models usually requires high computation costs. Therefore, compressing DRL models possesses immense potential for training acceleration and model deployment. However, existing methods that generate small models mainly adopt the knowledge distillation based approach by iteratively training a dense network, such that the training process still demands massive computing resources. Indeed, sparse training from scratch in DRL has not been well explored and is particularly challenging due to non-stationarity in bootstrap training. In this work, we propose a novel sparse DRL training framework, "the \textbf{R}igged \textbf{R}einforcement \textbf{L}earning \textbf{L}ottery" (RLx2), which is capable of training a DRL agent \emph{using an ultra-sparse network throughout} for off-policy reinforcement learning. The systematic RLx2 framework contains three key components: gradient-based topology evolution, multi-step Temporal Difference (TD) targets, and dynamic-capacity replay buffer. RLx2 enables efficient topology exploration and robust Q-value estimation simultaneously. We demonstrate state-of-the-art sparse training performance in several continuous control tasks using RLx2, showing $7.5\times$-$20\times$ model compression with less than $3\%$ performance degradation, and up to $20\times$ and $50\times$ FLOPs reduction for training and inference, respectively.