 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLx2: Training a Sparse Deep Reinforcement Learning Model from Scratch
Paper and Code

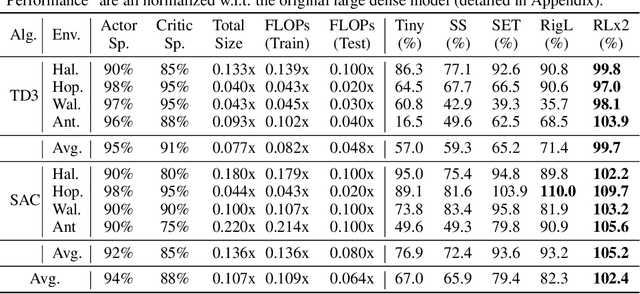
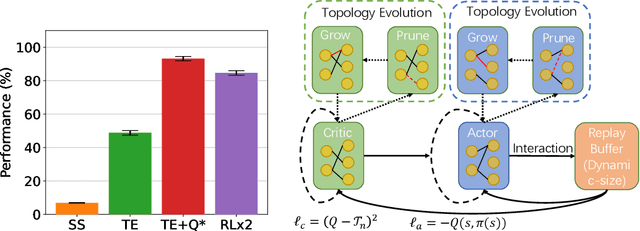

Training deep reinforcement learning (DRL) models usually requires high computation costs. Therefore, compressing DRL models possesses immense potential for training acceleration and model deployment. However, existing methods that generate small models mainly adopt the knowledge distillation based approach by iteratively training a dense network, such that the training process still demands massive computing resources. Indeed, sparse training from scratch in DRL has not been well explored and is particularly challenging due to non-stationarity in bootstrap training. In this work, we propose a novel sparse DRL training framework, "the \textbf{R}igged \textbf{R}einforcement \textbf{L}earning \textbf{L}ottery" (RLx2), which is capable of training a DRL agent \emph{using an ultra-sparse network throughout} for off-policy reinforcement learning. The systematic RLx2 framework contains three key components: gradient-based topology evolution, multi-step Temporal Difference (TD) targets, and dynamic-capacity replay buffer. RLx2 enables efficient topology exploration and robust Q-value estimation simultaneously. We demonstrate state-of-the-art sparse training performance in several continuous control tasks using RLx2, showing $7.5\times$-$20\times$ model compression with less than $3\%$ performance degradation, and up to $20\times$ and $50\times$ FLOPs reduction for training and inference, respectively.