 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling
Paper and Code
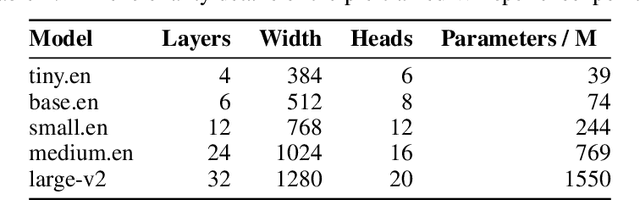
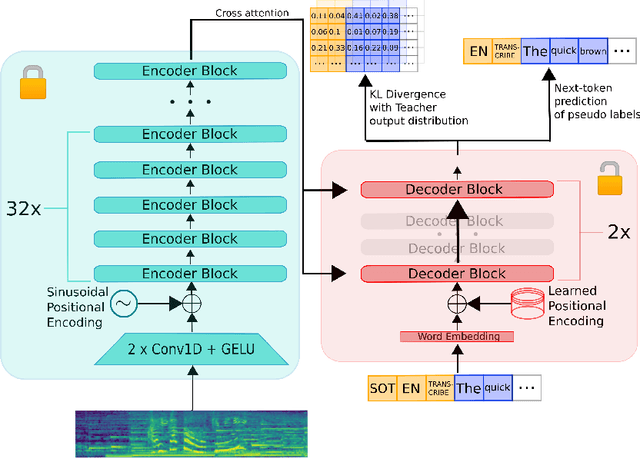
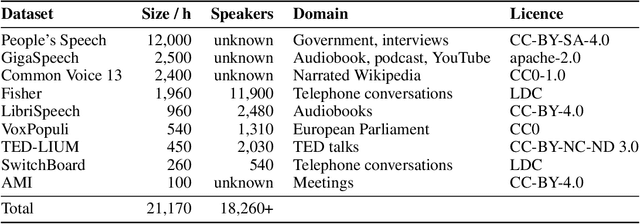
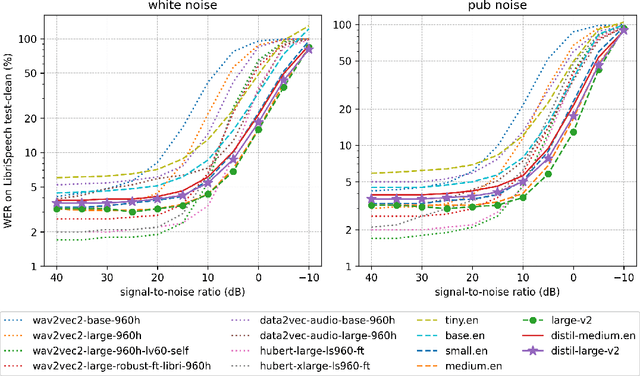
As the size of pre-trained speech recognition models increases, running these large models in low-latency or resource-constrained environments becomes challenging. In this work, we leverage pseudo-labelling to assemble a large-scale open-source dataset which we use to distill the Whisper model into a smaller variant, called Distil-Whisper. Using a simple word error rate (WER) heuristic, we select only the highest quality pseudo-labels for training. The distilled model is 5.8 times faster with 51% fewer parameters, while performing to within 1% WER on out-of-distribution test data in a zero-shot transfer setting. Distil-Whisper maintains the robustness of the Whisper model to difficult acoustic conditions, while being less prone to hallucination errors on long-form audio. Distil-Whisper is designed to be paired with Whisper for speculative decoding, yielding a 2 times speed-up while mathematically ensuring the same outputs as the original model. To facilitate further research in this domain, we make our training code, inference code and models publicly accessible.