 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the performances of ASR models on English and Spanish accents
Dec 22, 2022Speech to text models tend to be trained and evaluated against a single target accent. This is especially true for English for which native speakers from the United States became the main benchmark. In this work, we are going to show how two simple methods: pre-trained embeddings and auxiliary classification losses can improve the performance of ASR systems. We are looking for upgrades as universal as possible and therefore we will explore their impact on several models architectures and several languages.
Improving Data Driven Inverse Text Normalization using Data Augmentation
Jul 20, 2022
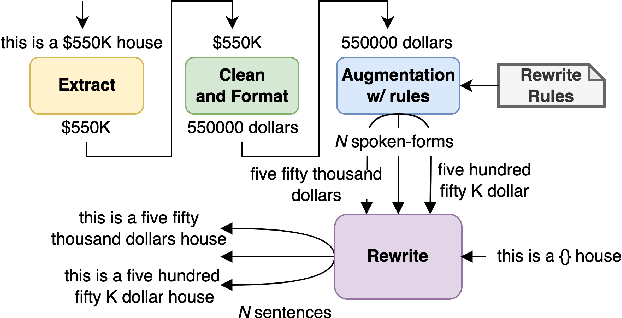

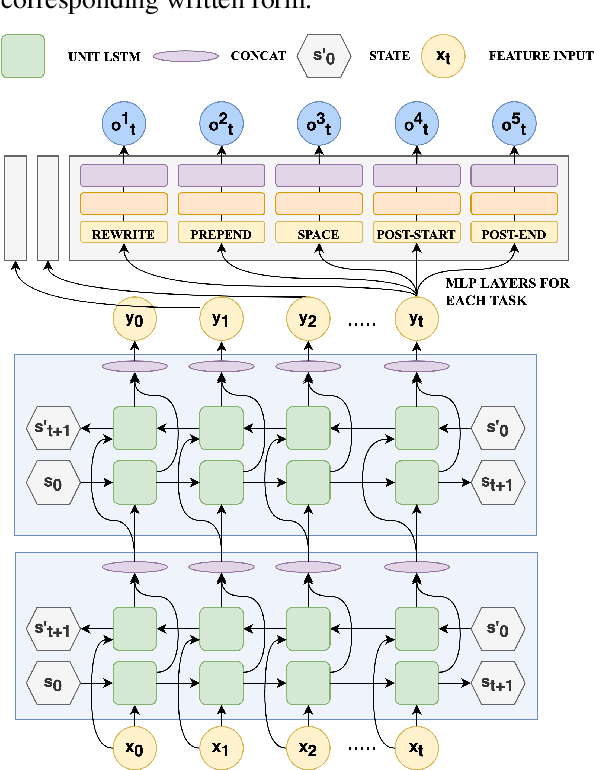
Inverse text normalization (ITN) is used to convert the spoken form output of an automatic speech recognition (ASR) system to a written form. Traditional handcrafted ITN rules can be complex to transcribe and maintain. Meanwhile neural modeling approaches require quality large-scale spoken-written pair examples in the same or similar domain as the ASR system (in-domain data), to train. Both these approaches require costly and complex annotations. In this paper, we present a data augmentation technique that effectively generates rich spoken-written numeric pairs from out-of-domain textual data with minimal human annotation. We empirically demonstrate that ITN model trained using our data augmentation technique consistently outperform ITN model trained using only in-domain data across all numeric surfaces like cardinal, currency, and fraction, by an overall accuracy of 14.44%.
Scaling ASR Improves Zero and Few Shot Learning
Nov 29, 2021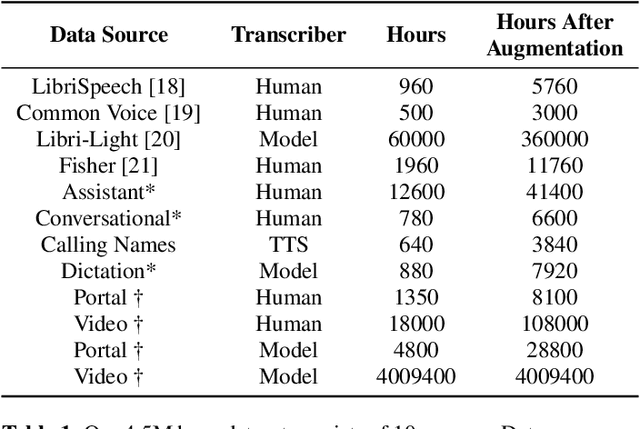
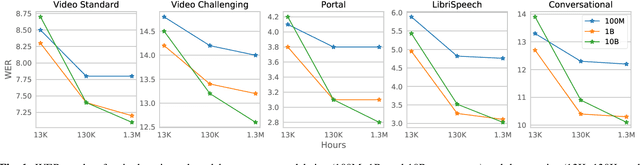
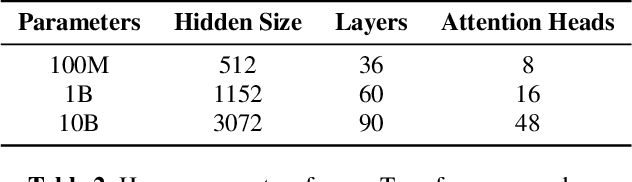
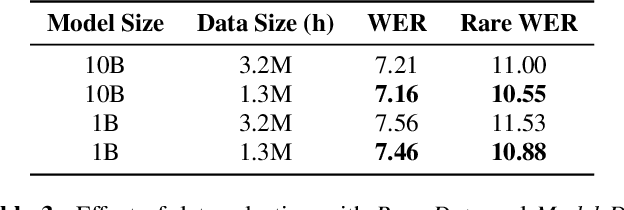
With 4.5 million hours of English speech from 10 different sources across 120 countries and models of up to 10 billion parameters, we explore the frontiers of scale for automatic speech recognition. We propose data selection techniques to efficiently scale training data to find the most valuable samples in massive datasets. To efficiently scale model sizes, we leverage various optimizations such as sparse transducer loss and model sharding. By training 1-10B parameter universal English ASR models, we push the limits of speech recognition performance across many domains. Furthermore, our models learn powerful speech representations with zero and few-shot capabilities on novel domains and styles of speech, exceeding previous results across multiple in-house and public benchmarks. For speakers with disorders due to brain damage, our best zero-shot and few-shot models achieve 22% and 60% relative improvement on the AphasiaBank test set, respectively, while realizing the best performance on public social media videos. Furthermore, the same universal model reaches equivalent performance with 500x less in-domain data on the SPGISpeech financial-domain dataset.
XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale
Nov 19, 2021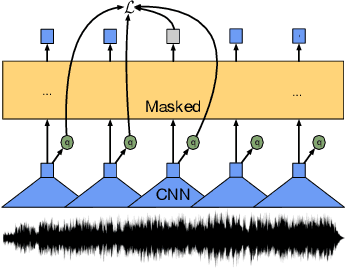
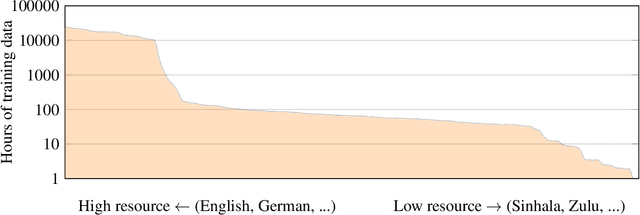

This paper presents XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0. We train models with up to 2B parameters on nearly half a million hours of publicly available speech audio in 128 languages, an order of magnitude more public data than the largest known prior work. Our evaluation covers a wide range of tasks, domains, data regimes and languages, both high and low-resource. On the CoVoST-2 speech translation benchmark, we improve the previous state of the art by an average of 7.4 BLEU over 21 translation directions into English. For speech recognition, XLS-R improves over the best known prior work on BABEL, MLS, CommonVoice as well as VoxPopuli, lowering error rates by 14-34% relative on average. XLS-R also sets a new state of the art on VoxLingua107 language identification. Moreover, we show that with sufficient model size, cross-lingual pretraining can outperform English-only pretraining when translating English speech into other languages, a setting which favors monolingual pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.
Towards Measuring Fairness in Speech Recognition: Casual Conversations Dataset Transcriptions
Nov 18, 2021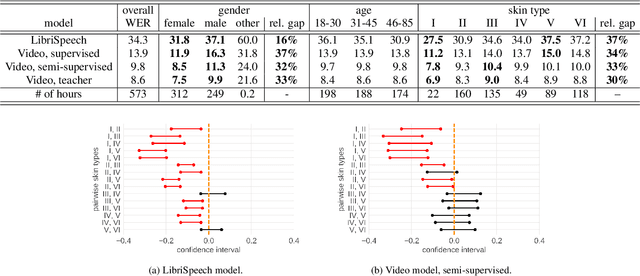

It is well known that many machine learning systems demonstrate bias towards specific groups of individuals. This problem has been studied extensively in the Facial Recognition area, but much less so in Automatic Speech Recognition (ASR). This paper presents initial Speech Recognition results on "Casual Conversations" -- a publicly released 846 hour corpus designed to help researchers evaluate their computer vision and audio models for accuracy across a diverse set of metadata, including age, gender, and skin tone. The entire corpus has been manually transcribed, allowing for detailed ASR evaluations across these metadata. Multiple ASR models are evaluated, including models trained on LibriSpeech, 14,000 hour transcribed, and over 2 million hour untranscribed social media videos. Significant differences in word error rate across gender and skin tone are observed at times for all models. We are releasing human transcripts from the Casual Conversations dataset to encourage the community to develop a variety of techniques to reduce these statistical biases.
Conformer-Based Self-Supervised Learning for Non-Speech Audio Tasks
Nov 10, 2021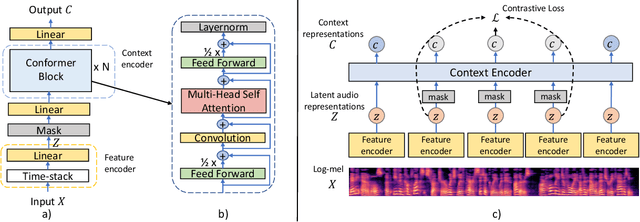
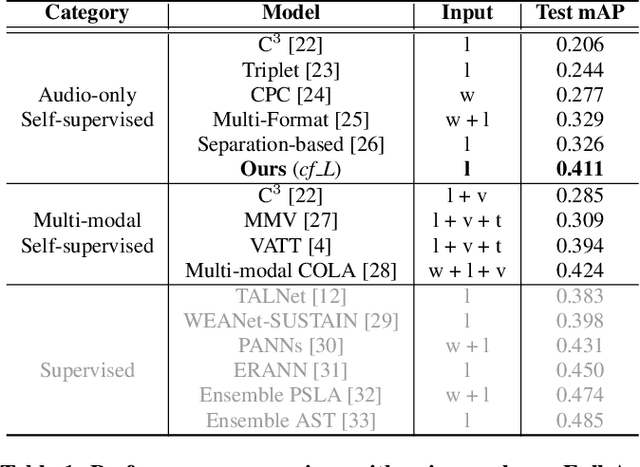

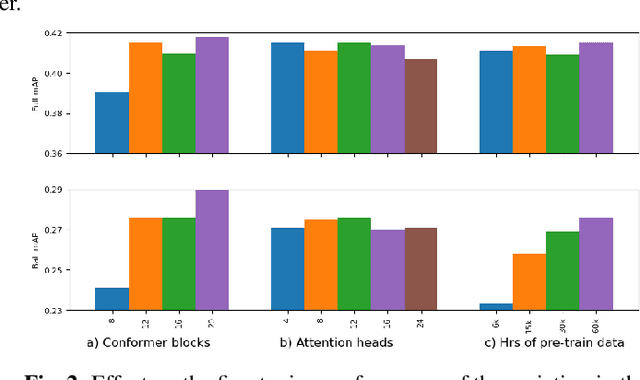
Representation learning from unlabeled data has been of major interest in artificial intelligence research. While self-supervised speech representation learning has been popular in the speech research community, very few works have comprehensively analyzed audio representation learning for non-speech audio tasks. In this paper, we propose a self-supervised audio representation learning method and apply it to a variety of downstream non-speech audio tasks. We combine the well-known wav2vec 2.0 framework, which has shown success in self-supervised learning for speech tasks, with parameter-efficient conformer architectures. Our self-supervised pre-training can reduce the need for labeled data by two-thirds. On the AudioSet benchmark, we achieve a mean average precision (mAP) score of 0.415, which is a new state-of-the-art on this dataset through audio-only self-supervised learning. Our fine-tuned conformers also surpass or match the performance of previous systems pre-trained in a supervised way on several downstream tasks. We further discuss the important design considerations for both pre-training and fine-tuning.
Accent-Robust Automatic Speech Recognition Using Supervised and Unsupervised Wav2vec Embeddings
Oct 08, 2021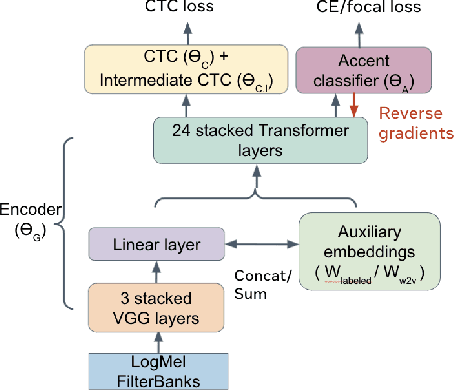
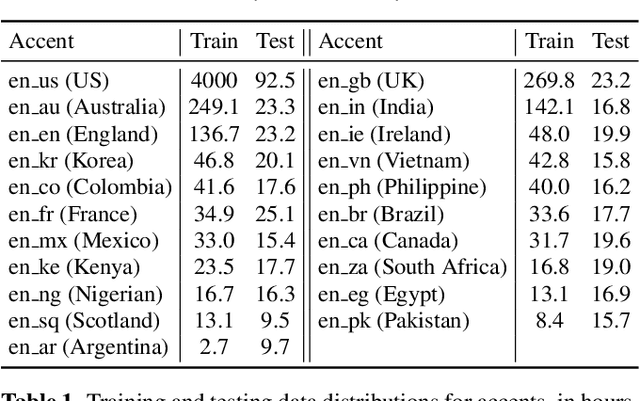
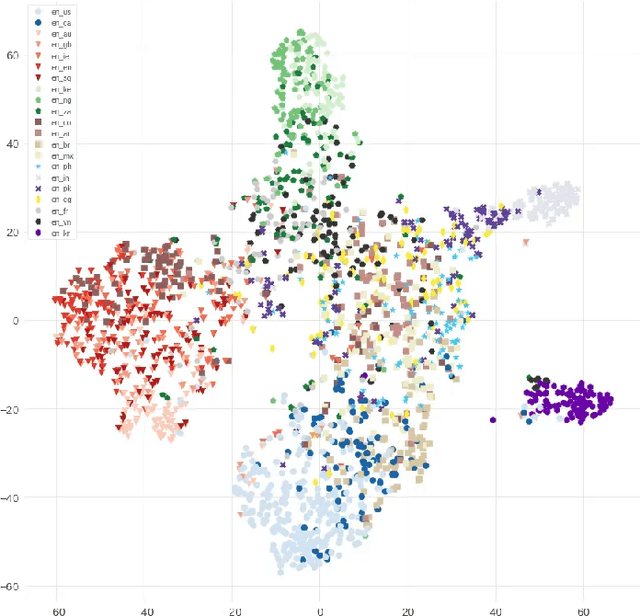

Speech recognition models often obtain degraded performance when tested on speech with unseen accents. Domain-adversarial training (DAT) and multi-task learning (MTL) are two common approaches for building accent-robust ASR models. ASR models using accent embeddings is another approach for improving robustness to accents. In this study, we perform systematic comparisons of DAT and MTL approaches using a large volume of English accent corpus (4000 hours of US English speech and 1244 hours of 20 non-US-English accents speech). We explore embeddings trained under supervised and unsupervised settings: a separate embedding matrix trained using accent labels, and embeddings extracted from a fine-tuned wav2vec model. We find that our DAT model trained with supervised embeddings achieves the best performance overall and consistently provides benefits for all testing datasets, and our MTL model trained with wav2vec embeddings are helpful learning accent-invariant features and improving novel/unseen accents. We also illustrate that wav2vec embeddings have more advantages for building accent-robust ASR when no accent labels are available for training supervised embeddings.
Improved Language Identification Through Cross-Lingual Self-Supervised Learning
Aug 04, 2021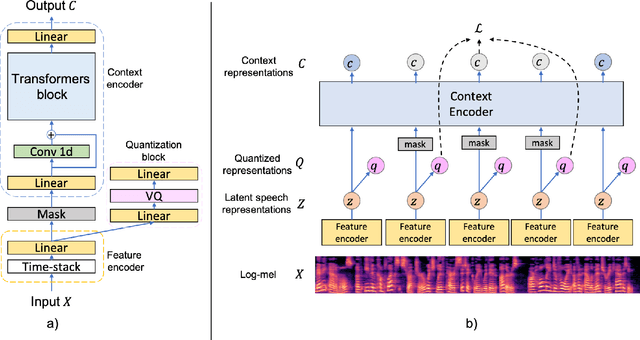
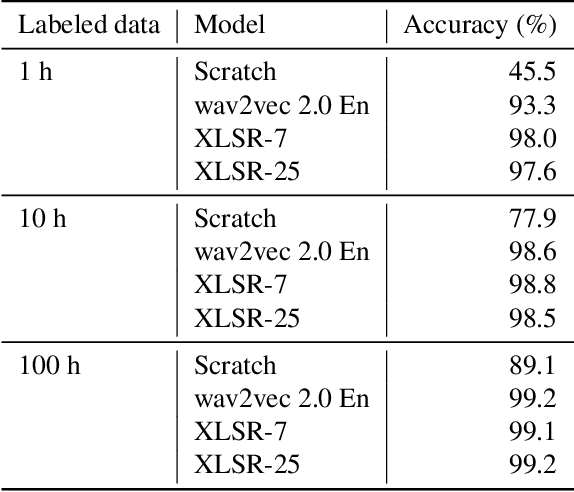
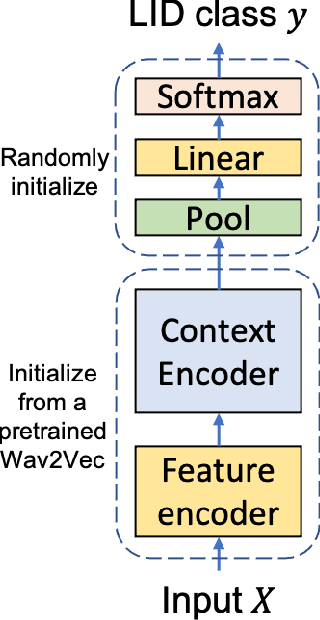
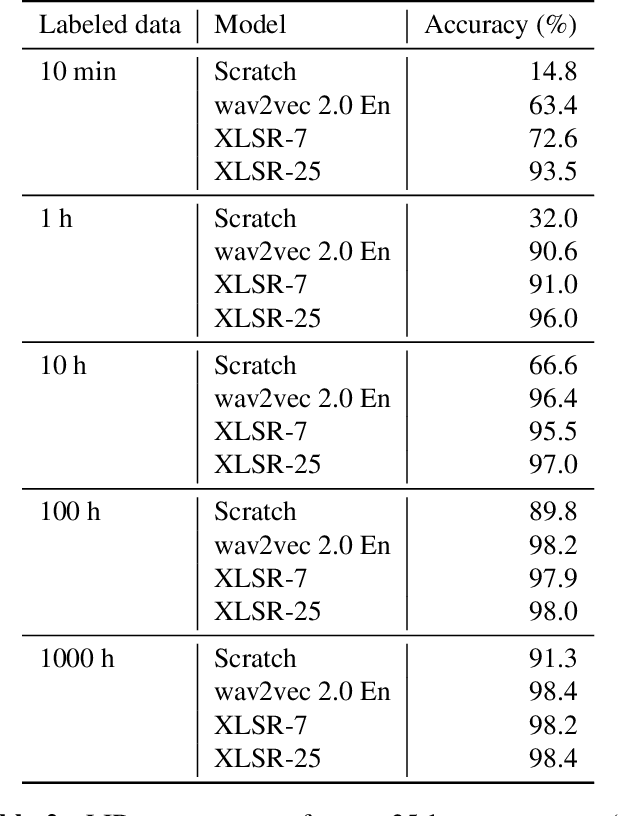
Language identification greatly impacts the success of downstream tasks such as automatic speech recognition. Recently, self-supervised speech representations learned by wav2vec 2.0 have been shown to be very effective for a range of speech tasks. We extend previous self-supervised work on language identification by experimenting with pre-trained models which were learned on real-world unconstrained speech in multiple languages and not just on English. We show that models pre-trained on many languages perform better and enable language identification systems that require very little labeled data to perform well. Results on a 25 languages setup show that with only 10 minutes of labeled data per language, a cross-lingually pre-trained model can achieve over 93% accuracy.
On lattice-free boosted MMI training of HMM and CTC-based full-context ASR models
Jul 09, 2021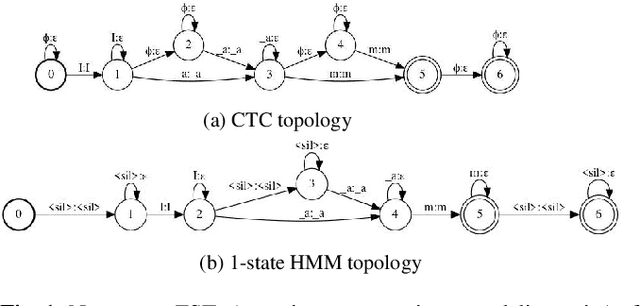
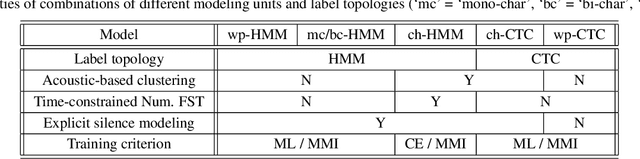
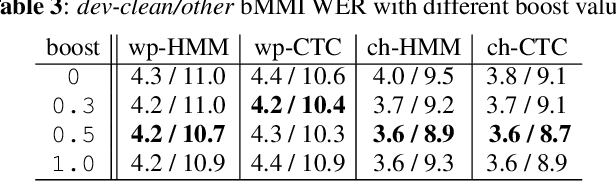
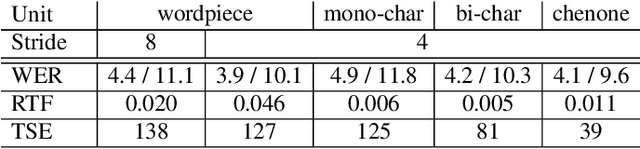
Hybrid automatic speech recognition (ASR) models are typically sequentially trained with CTC or LF-MMI criteria. However, they have vastly different legacies and are usually implemented in different frameworks. In this paper, by decoupling the concepts of modeling units and label topologies and building proper numerator/denominator graphs accordingly, we establish a generalized framework for hybrid acoustic modeling (AM). In this framework, we show that LF-MMI is a powerful training criterion applicable to both limited-context and full-context models, for wordpiece/mono-char/bi-char/chenone units, with both HMM/CTC topologies. From this framework, we propose three novel training schemes: chenone(ch)/wordpiece(wp)-CTC-bMMI, and wordpiece(wp)-HMM-bMMI with different advantages in training performance, decoding efficiency and decoding time-stamp accuracy. The advantages of different training schemes are evaluated comprehensively on Librispeech, and wp-CTC-bMMI and ch-CTC-bMMI are evaluated on two real world ASR tasks to show their effectiveness. Besides, we also show bi-char(bc) HMM-MMI models can serve as better alignment models than traditional non-neural GMM-HMMs.
Kaizen: Continuously improving teacher using Exponential Moving Average for semi-supervised speech recognition
Jun 14, 2021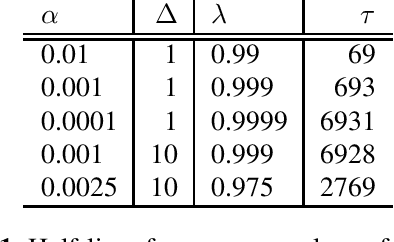
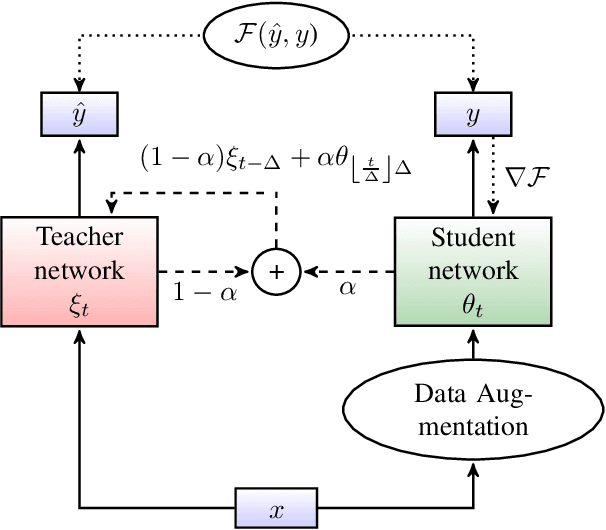
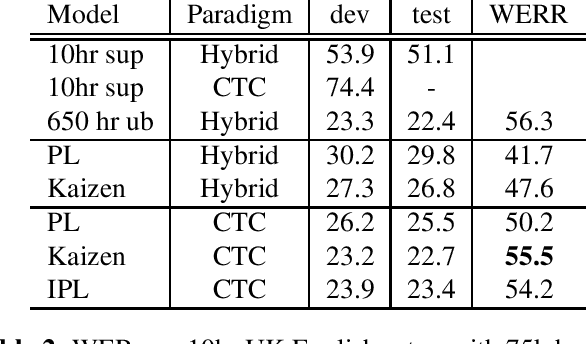
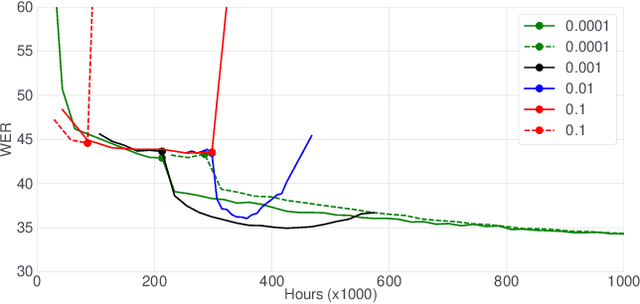
In this paper, we introduce the Kaizen framework that uses a continuously improving teacher to generate pseudo-labels for semi-supervised training. The proposed approach uses a teacher model which is updated as the exponential moving average of the student model parameters. This can be seen as a continuous version of the iterative pseudo-labeling approach for semi-supervised training. It is applicable for different training criteria, and in this paper we demonstrate it for frame-level hybrid hidden Markov model - deep neural network (HMM-DNN) models and sequence-level connectionist temporal classification (CTC) based models. The proposed approach shows more than 10% word error rate (WER) reduction over standard teacher-student training and more than 50\% relative WER reduction over 10 hour supervised baseline when using large scale realistic unsupervised public videos in UK English and Italian languages.