 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorized Blank Thresholding for Improved Runtime Efficiency of Neural Transducers
Nov 02, 2022We show how factoring the RNN-T's output distribution can significantly reduce the computation cost and power consumption for on-device ASR inference with no loss in accuracy. With the rise in popularity of neural-transducer type models like the RNN-T for on-device ASR, optimizing RNN-T's runtime efficiency is of great interest. While previous work has primarily focused on the optimization of RNN-T's acoustic encoder and predictor, this paper focuses the attention on the joiner. We show that despite being only a small part of RNN-T, the joiner has a large impact on the overall model's runtime efficiency. We propose to factorize the joiner into blank and non-blank portions for the purpose of skipping the more expensive non-blank computation when the blank probability exceeds a certain threshold. Since the blank probability can be computed very efficiently and the RNN-T output is dominated by blanks, our proposed method leads to a 26-30% decoding speed-up and 43-53% reduction in on-device power consumption, all the while incurring no accuracy degradation and being relatively simple to implement.
Improving Data Driven Inverse Text Normalization using Data Augmentation
Jul 20, 2022
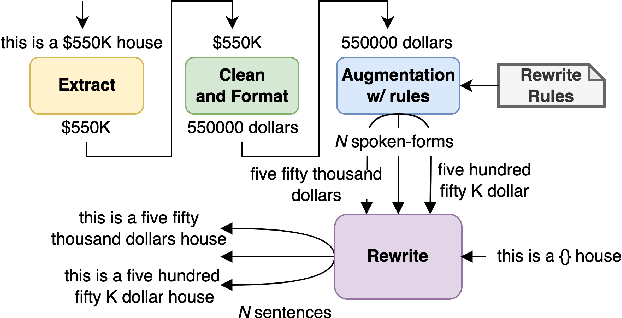

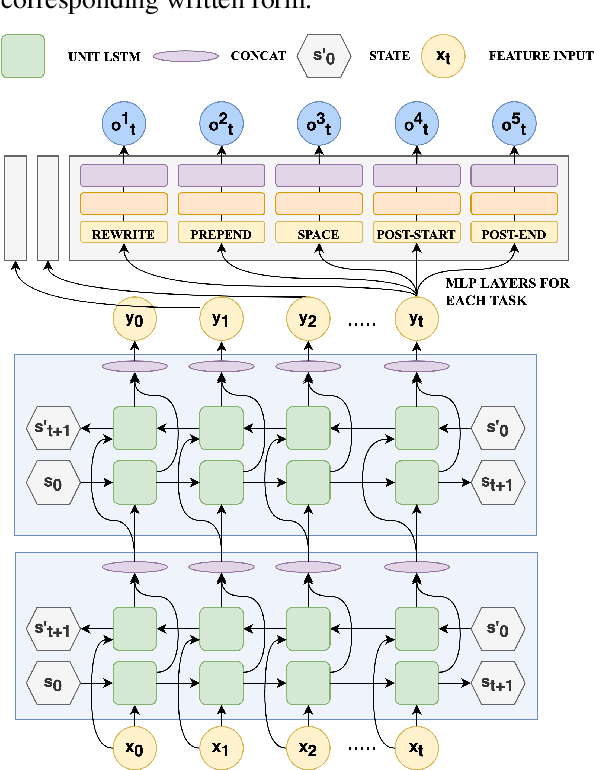
Inverse text normalization (ITN) is used to convert the spoken form output of an automatic speech recognition (ASR) system to a written form. Traditional handcrafted ITN rules can be complex to transcribe and maintain. Meanwhile neural modeling approaches require quality large-scale spoken-written pair examples in the same or similar domain as the ASR system (in-domain data), to train. Both these approaches require costly and complex annotations. In this paper, we present a data augmentation technique that effectively generates rich spoken-written numeric pairs from out-of-domain textual data with minimal human annotation. We empirically demonstrate that ITN model trained using our data augmentation technique consistently outperform ITN model trained using only in-domain data across all numeric surfaces like cardinal, currency, and fraction, by an overall accuracy of 14.44%.
RNN-T For Latency Controlled ASR With Improved Beam Search
Nov 05, 2019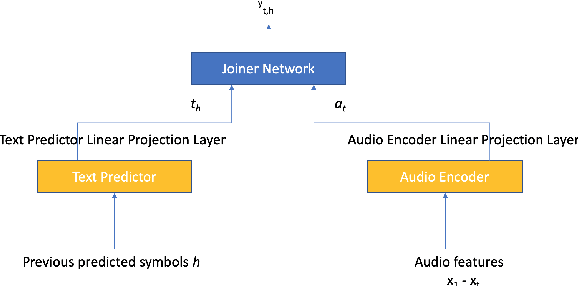

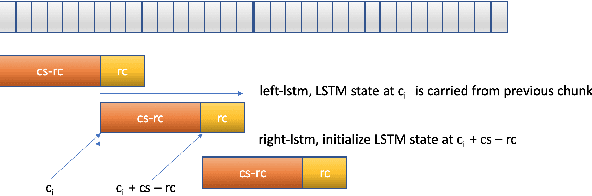
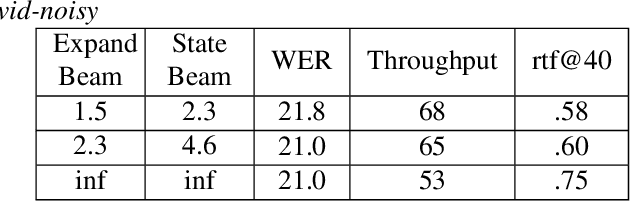
Neural transducer-based systems such as RNN Transducers (RNN-T) for automatic speech recognition (ASR) blend the individual components of a traditional hybrid ASR systems (acoustic model, language model, punctuation model, inverse text normalization) into one single model. This greatly simplifies training and inference and hence makes RNN-T a desirable choice for ASR systems. In this work, we investigate use of RNN-T in applications that require a tune-able latency budget during inference time. We also improved the decoding speed of the originally proposed RNN-T beam search algorithm. We evaluated our proposed system on English videos ASR dataset and show that neural RNN-T models can achieve comparable WER and better computational efficiency compared to a well tuned hybrid ASR baseline.
Transformer-Transducer: End-to-End Speech Recognition with Self-Attention
Oct 28, 2019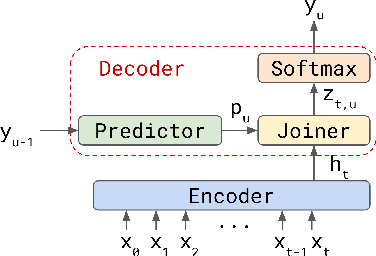
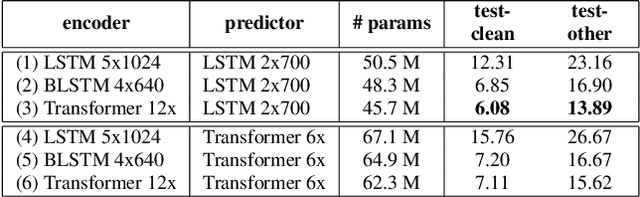
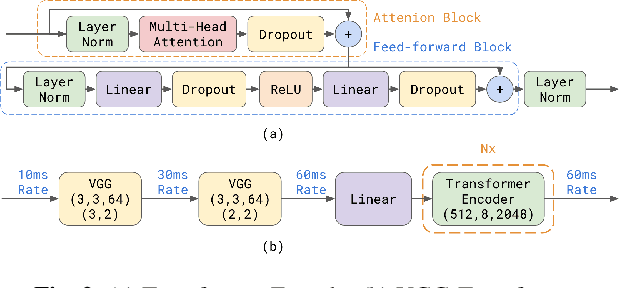
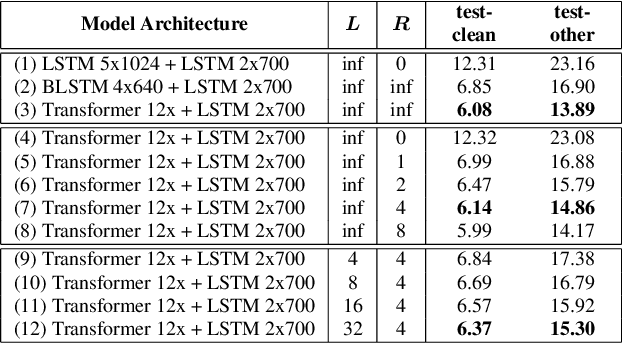
We explore options to use Transformer networks in neural transducer for end-to-end speech recognition. Transformer networks use self-attention for sequence modeling and comes with advantages in parallel computation and capturing contexts. We propose 1) using VGGNet with causal convolution to incorporate positional information and reduce frame rate for efficient inference 2) using truncated self-attention to enable streaming for Transformer and reduce computational complexity. All experiments are conducted on the public LibriSpeech corpus. The proposed Transformer-Transducer outperforms neural transducer with LSTM/BLSTM networks and achieved word error rates of 6.37 % on the test-clean set and 15.30 % on the test-other set, while remaining streamable, compact with 45.7M parameters for the entire system, and computationally efficient with complexity of O(T), where T is input sequence length.