 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectional Source Separation for Robust Speech Recognition on Smart Glasses
Sep 20, 2023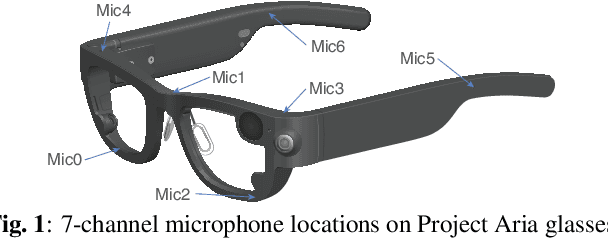
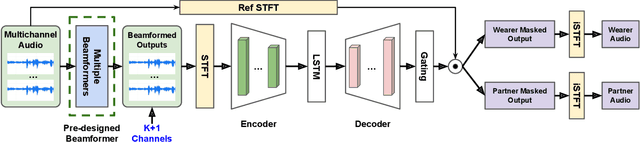
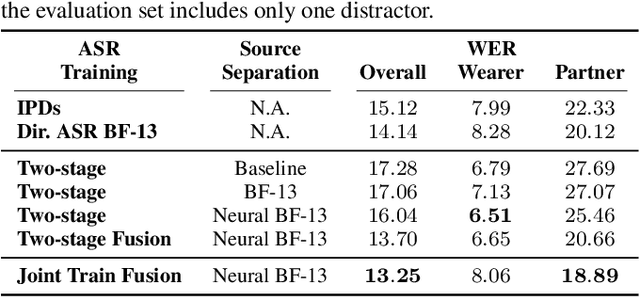
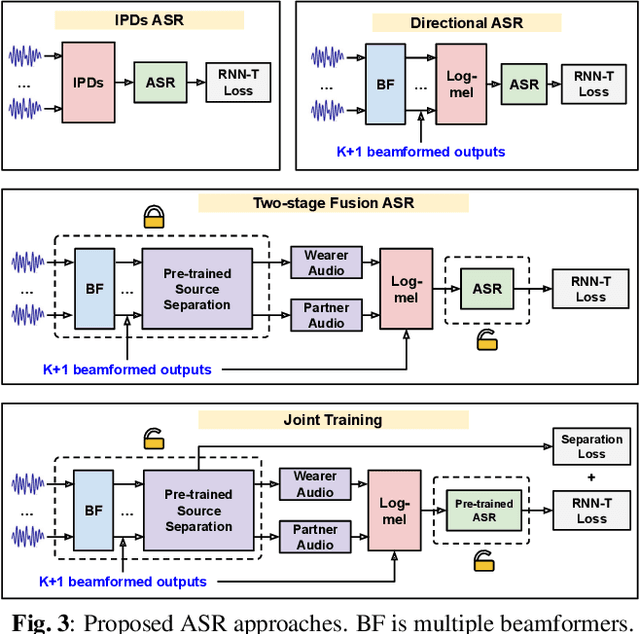
Modern smart glasses leverage advanced audio sensing and machine learning technologies to offer real-time transcribing and captioning services, considerably enriching human experiences in daily communications. However, such systems frequently encounter challenges related to environmental noises, resulting in degradation to speech recognition and speaker change detection. To improve voice quality, this work investigates directional source separation using the multi-microphone array. We first explore multiple beamformers to assist source separation modeling by strengthening the directional properties of speech signals. In addition to relying on predetermined beamformers, we investigate neural beamforming in multi-channel source separation, demonstrating that automatic learning directional characteristics effectively improves separation quality. We further compare the ASR performance leveraging separated outputs to noisy inputs. Our results show that directional source separation benefits ASR for the wearer but not for the conversation partner. Lastly, we perform the joint training of the directional source separation and ASR model, achieving the best overall ASR performance.
Egocentric Audio-Visual Noise Suppression
Nov 07, 2022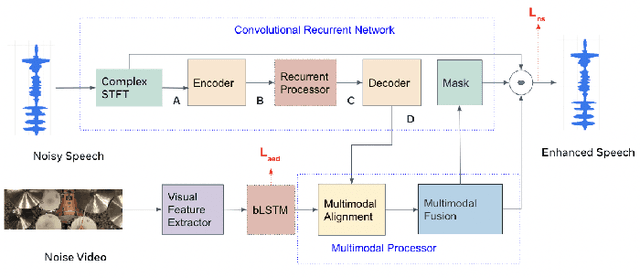
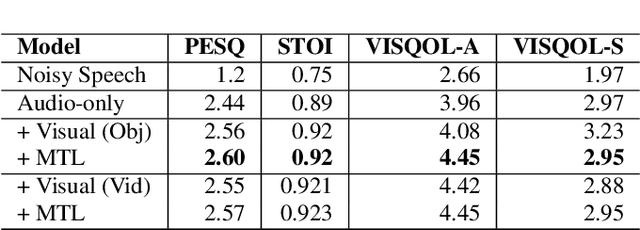
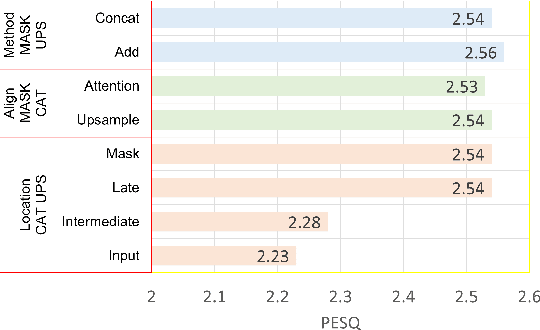

This paper studies audio-visual suppression for egocentric videos -- where the speaker is not captured in the video. Instead, potential noise sources are visible on screen with the camera emulating the off-screen speaker's view of the outside world. This setting is different from prior work in audio-visual speech enhancement that relies on lip and facial visuals. In this paper, we first demonstrate that egocentric visual information is helpful for noise suppression. We compare object recognition and action classification based visual feature extractors, and investigate methods to align audio and visual representations. Then, we examine different fusion strategies for the aligned features, and locations within the noise suppression model to incorporate visual information. Experiments demonstrate that visual features are most helpful when used to generate additive correction masks. Finally, in order to ensure that the visual features are discriminative with respect to different noise types, we introduce a multi-task learning framework that jointly optimizes audio-visual noise suppression and video based acoustic event detection. This proposed multi-task framework outperforms the audio only baseline on all metrics, including a 0.16 PESQ improvement. Extensive ablations reveal the improved performance of the proposed model with multiple active distractors, over all noise types and across different SNRs.
SCA: Streaming Cross-attention Alignment for Echo Cancellation
Nov 01, 2022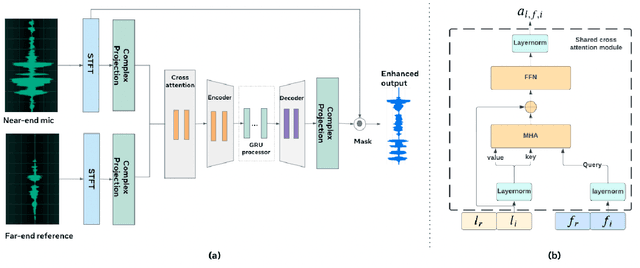

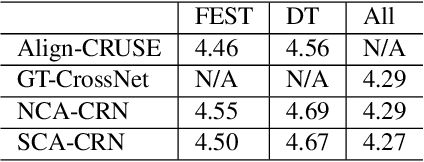
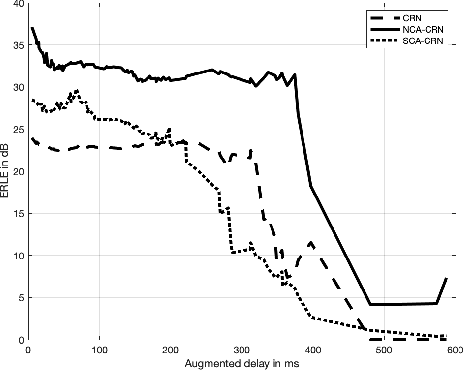
End-to-End deep learning has shown promising results for speech enhancement tasks, such as noise suppression, dereverberation, and speech separation. However, most state-of-the-art methods for echo cancellation are either classical DSP-based or hybrid DSP-ML algorithms. Components such as the delay estimator and adaptive linear filter are based on traditional signal processing concepts, and deep learning algorithms typically only serve to replace the non-linear residual echo suppressor. This paper introduces an end-to-end echo cancellation network with a streaming cross-attention alignment (SCA). Our proposed method can handle unaligned inputs without requiring external alignment and generate high-quality speech without echoes. At the same time, the end-to-end algorithm simplifies the current echo cancellation pipeline for time-variant echo path cases. We test our proposed method on the ICASSP2022 and Interspeech2021 Microsoft deep echo cancellation challenge evaluation dataset, where our method outperforms some of the other hybrid and end-to-end methods.
RNN-T For Latency Controlled ASR With Improved Beam Search
Nov 05, 2019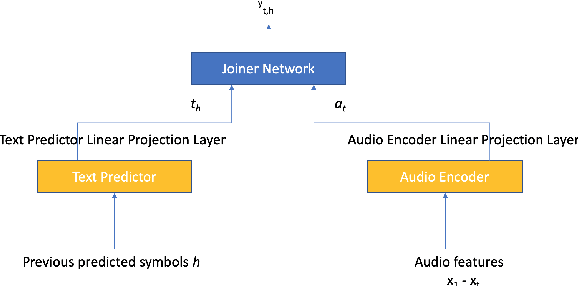

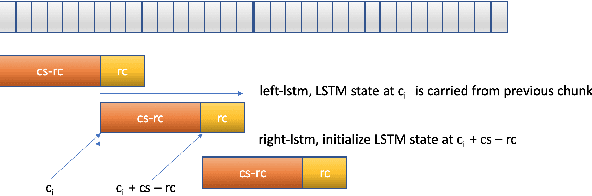
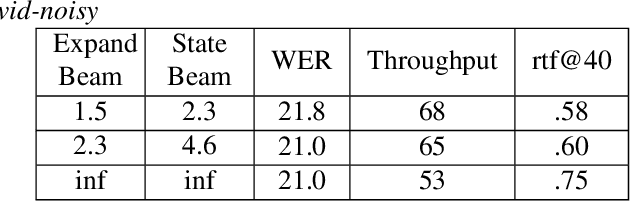
Neural transducer-based systems such as RNN Transducers (RNN-T) for automatic speech recognition (ASR) blend the individual components of a traditional hybrid ASR systems (acoustic model, language model, punctuation model, inverse text normalization) into one single model. This greatly simplifies training and inference and hence makes RNN-T a desirable choice for ASR systems. In this work, we investigate use of RNN-T in applications that require a tune-able latency budget during inference time. We also improved the decoding speed of the originally proposed RNN-T beam search algorithm. We evaluated our proposed system on English videos ASR dataset and show that neural RNN-T models can achieve comparable WER and better computational efficiency compared to a well tuned hybrid ASR baseline.
Transformer-Transducer: End-to-End Speech Recognition with Self-Attention
Oct 28, 2019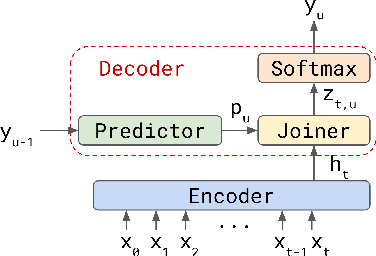
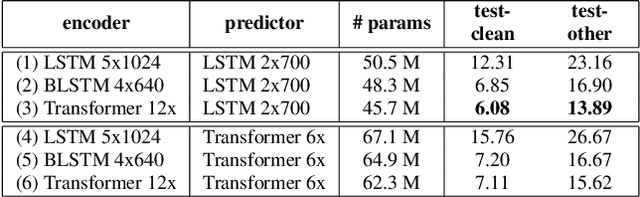
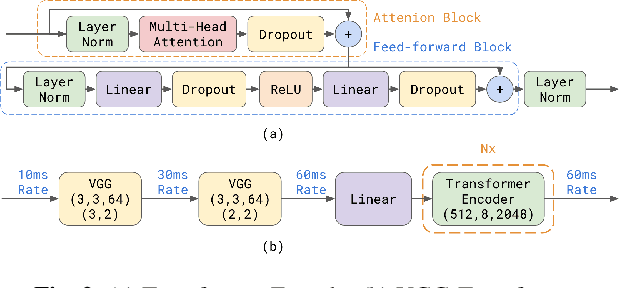
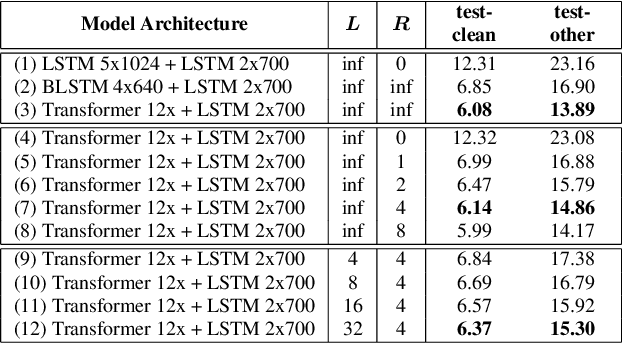
We explore options to use Transformer networks in neural transducer for end-to-end speech recognition. Transformer networks use self-attention for sequence modeling and comes with advantages in parallel computation and capturing contexts. We propose 1) using VGGNet with causal convolution to incorporate positional information and reduce frame rate for efficient inference 2) using truncated self-attention to enable streaming for Transformer and reduce computational complexity. All experiments are conducted on the public LibriSpeech corpus. The proposed Transformer-Transducer outperforms neural transducer with LSTM/BLSTM networks and achieved word error rates of 6.37 % on the test-clean set and 15.30 % on the test-other set, while remaining streamable, compact with 45.7M parameters for the entire system, and computationally efficient with complexity of O(T), where T is input sequence length.