 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Extensible Embodied Capabilities with Tools
May 26, 2026Most existing embodied intelligence methods formulate perception, reasoning, planning, and control within a unified parameterized policy. Yet these capabilities are inherently hierarchical and heterogeneous, making them difficult to reliably learn and modularize within a single model. We propose a capability externalization approach that decouples heterogeneous capabilities into independently optimized tools, dynamically invoked at inference time. To this end, we introduce Embodied Tool Protocol (ETP), a standardized protocol for embodied tool registration, discovery, invocation, and execution, and curate 100+ validated tools spanning perception, cognition, reasoning, and execution as the tool base. Building on this, we construct EmbodiedToolBench to evaluate both whether tool augmentation improves embodied performance and how well current models use tools across tool-necessity recognition, tool selection, tool execution, and tool-chain composition. Experiments across simulation and real-world platforms confirm that capability externalization consistently improves embodied performance (avg. gain 31% on EB-ALFRED and 36% on EB-Navigation), yet reveal a clear boundary: gains are substantial for cognition and perception but are limited for execution-type capabilities. Moreover, our analysis reveals that knowing when, which, and how to invoke tools remains a persistent challenge across all models, thereby highlighting embodied tool competence as a critical direction for future research.
Multi-Channel Differential ASR for Robust Wearer Speech Recognition on Smart Glasses
Sep 17, 2025With the growing adoption of wearable devices such as smart glasses for AI assistants, wearer speech recognition (WSR) is becoming increasingly critical to next-generation human-computer interfaces. However, in real environments, interference from side-talk speech remains a significant challenge to WSR and may cause accumulated errors for downstream tasks such as natural language processing. In this work, we introduce a novel multi-channel differential automatic speech recognition (ASR) method for robust WSR on smart glasses. The proposed system takes differential inputs from different frontends that complement each other to improve the robustness of WSR, including a beamformer, microphone selection, and a lightweight side-talk detection model. Evaluations on both simulated and real datasets demonstrate that the proposed system outperforms the traditional approach, achieving up to an 18.0% relative reduction in word error rate.
MASV: Speaker Verification with Global and Local Context Mamba
Dec 14, 2024


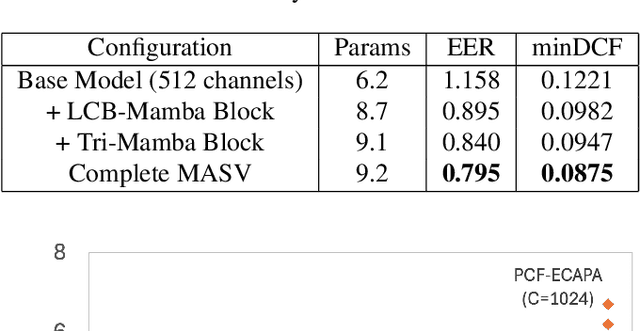
Deep learning models like Convolutional Neural Networks and transformers have shown impressive capabilities in speech verification, gaining considerable attention in the research community. However, CNN-based approaches struggle with modeling long-sequence audio effectively, resulting in suboptimal verification performance. On the other hand, transformer-based methods are often hindered by high computational demands, limiting their practicality. This paper presents the MASV model, a novel architecture that integrates the Mamba module into the ECAPA-TDNN framework. By introducing the Local Context Bidirectional Mamba and Tri-Mamba block, the model effectively captures both global and local context within audio sequences. Experimental results demonstrate that the MASV model substantially enhances verification performance, surpassing existing models in both accuracy and efficiency.
Query-by-Example Keyword Spotting Using Spectral-Temporal Graph Attentive Pooling and Multi-Task Learning
Aug 27, 2024



Existing keyword spotting (KWS) systems primarily rely on predefined keyword phrases. However, the ability to recognize customized keywords is crucial for tailoring interactions with intelligent devices. In this paper, we present a novel Query-by-Example (QbyE) KWS system that employs spectral-temporal graph attentive pooling and multi-task learning. This framework aims to effectively learn speaker-invariant and linguistic-informative embeddings for QbyE KWS tasks. Within this framework, we investigate three distinct network architectures for encoder modeling: LiCoNet, Conformer and ECAPA_TDNN. The experimental results on a substantial internal dataset of $629$ speakers have demonstrated the effectiveness of the proposed QbyE framework in maximizing the potential of simpler models such as LiCoNet. Particularly, LiCoNet, which is 13x more efficient, achieves comparable performance to the computationally intensive Conformer model (1.98% vs. 1.63\% FRR at 0.3 FAs/Hr).
Disentangled Training with Adversarial Examples For Robust Small-footprint Keyword Spotting
Aug 23, 2024



A keyword spotting (KWS) engine that is continuously running on device is exposed to various speech signals that are usually unseen before. It is a challenging problem to build a small-footprint and high-performing KWS model with robustness under different acoustic environments. In this paper, we explore how to effectively apply adversarial examples to improve KWS robustness. We propose datasource-aware disentangled learning with adversarial examples to reduce the mismatch between the original and adversarial data as well as the mismatch across original training datasources. The KWS model architecture is based on depth-wise separable convolution and a simple attention module. Experimental results demonstrate that the proposed learning strategy improves false reject rate by $40.31%$ at $1%$ false accept rate on the internal dataset, compared to the strongest baseline without using adversarial examples. Our best-performing system achieves $98.06%$ accuracy on the Google Speech Commands V1 dataset.
Lightweight Conceptual Dictionary Learning for Text Classification Using Information Compression
Apr 28, 2024



We propose a novel, lightweight supervised dictionary learning framework for text classification based on data compression and representation. This two-phase algorithm initially employs the Lempel-Ziv-Welch (LZW) algorithm to construct a dictionary from text datasets, focusing on the conceptual significance of dictionary elements. Subsequently, dictionaries are refined considering label data, optimizing dictionary atoms to enhance discriminative power based on mutual information and class distribution. This process generates discriminative numerical representations, facilitating the training of simple classifiers such as SVMs and neural networks. We evaluate our algorithm's information-theoretic performance using information bottleneck principles and introduce the information plane area rank (IPAR) as a novel metric to quantify the information-theoretic performance. Tested on six benchmark text datasets, our algorithm competes closely with top models, especially in limited-vocabulary contexts, using significantly fewer parameters. \review{Our algorithm closely matches top-performing models, deviating by only ~2\% on limited-vocabulary datasets, using just 10\% of their parameters. However, it falls short on diverse-vocabulary datasets, likely due to the LZW algorithm's constraints with low-repetition data. This contrast highlights its efficiency and limitations across different dataset types.
FADI-AEC: Fast Score Based Diffusion Model Guided by Far-end Signal for Acoustic Echo Cancellation
Jan 08, 2024Despite the potential of diffusion models in speech enhancement, their deployment in Acoustic Echo Cancellation (AEC) has been restricted. In this paper, we propose DI-AEC, pioneering a diffusion-based stochastic regeneration approach dedicated to AEC. Further, we propose FADI-AEC, fast score-based diffusion AEC framework to save computational demands, making it favorable for edge devices. It stands out by running the score model once per frame, achieving a significant surge in processing efficiency. Apart from that, we introduce a novel noise generation technique where far-end signals are utilized, incorporating both far-end and near-end signals to refine the score model's accuracy. We test our proposed method on the ICASSP2023 Microsoft deep echo cancellation challenge evaluation dataset, where our method outperforms some of the end-to-end methods and other diffusion based echo cancellation methods.
Directional Source Separation for Robust Speech Recognition on Smart Glasses
Sep 20, 2023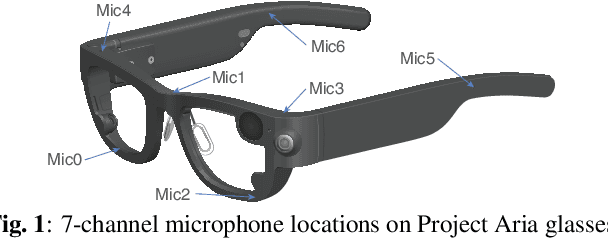
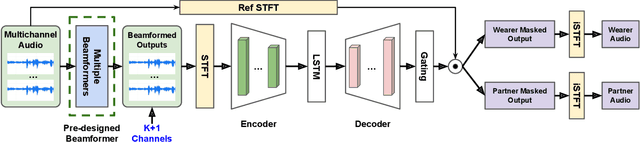
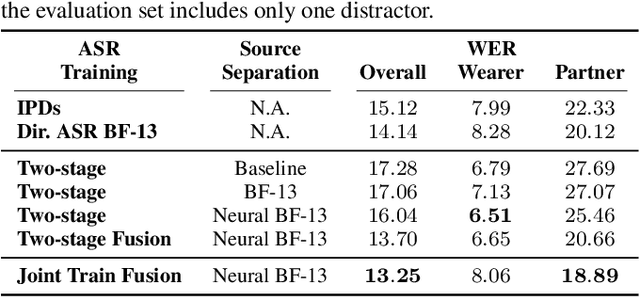
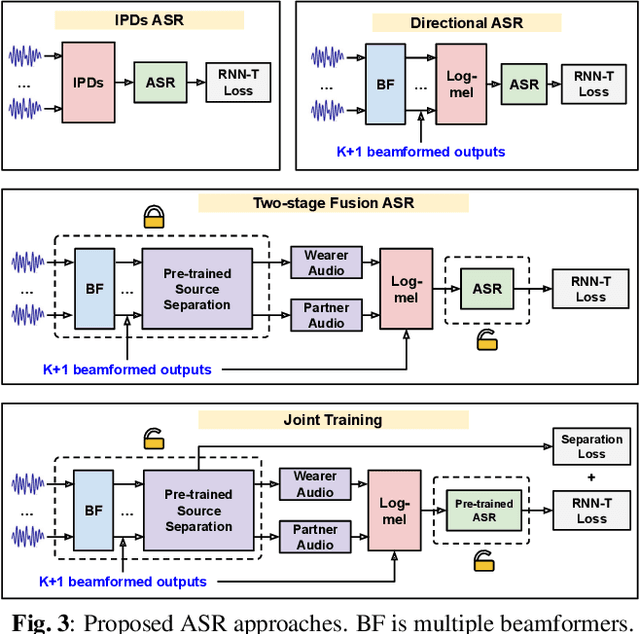
Modern smart glasses leverage advanced audio sensing and machine learning technologies to offer real-time transcribing and captioning services, considerably enriching human experiences in daily communications. However, such systems frequently encounter challenges related to environmental noises, resulting in degradation to speech recognition and speaker change detection. To improve voice quality, this work investigates directional source separation using the multi-microphone array. We first explore multiple beamformers to assist source separation modeling by strengthening the directional properties of speech signals. In addition to relying on predetermined beamformers, we investigate neural beamforming in multi-channel source separation, demonstrating that automatic learning directional characteristics effectively improves separation quality. We further compare the ASR performance leveraging separated outputs to noisy inputs. Our results show that directional source separation benefits ASR for the wearer but not for the conversation partner. Lastly, we perform the joint training of the directional source separation and ASR model, achieving the best overall ASR performance.
Handling the Alignment for Wake Word Detection: A Comparison Between Alignment-Based, Alignment-Free and Hybrid Approaches
Feb 17, 2023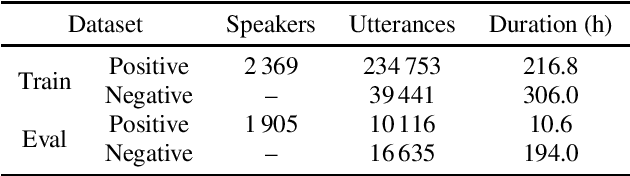
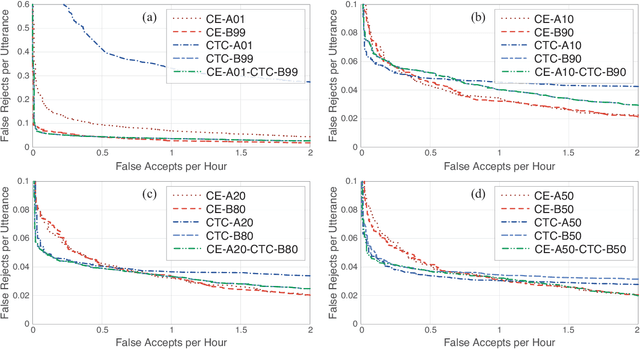
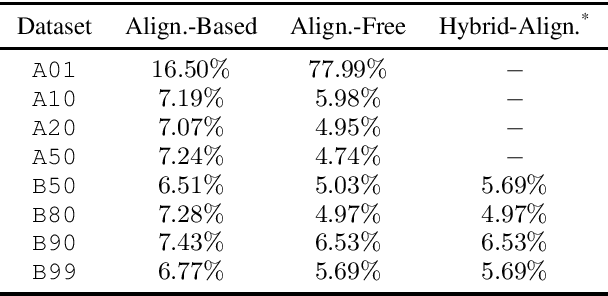

Wake word detection exists in most intelligent homes and portable devices. It offers these devices the ability to "wake up" when summoned at a low cost of power and computing. This paper focuses on understanding alignment's role in developing a wake-word system that answers a generic phrase. We discuss three approaches. The first is alignment-based, where the model is trained with frame-wise cross-entropy. The second is alignment-free, where the model is trained with CTC. The third, proposed by us, is a hybrid solution in which the model is trained with a small set of aligned data and then tuned with a sizeable unaligned dataset. We compare the three approaches and evaluate the impact of the different aligned-to-unaligned ratios for hybrid training. Our results show that the alignment-free system performs better alignment-based for the target operating point, and with a small fraction of the data (20%), we can train a model that complies with our initial constraints.
LiCo-Net: Linearized Convolution Network for Hardware-efficient Keyword Spotting
Nov 09, 2022



This paper proposes a hardware-efficient architecture, Linearized Convolution Network (LiCo-Net) for keyword spotting. It is optimized specifically for low-power processor units like microcontrollers. ML operators exhibit heterogeneous efficiency profiles on power-efficient hardware. Given the exact theoretical computation cost, int8 operators are more computation-effective than float operators, and linear layers are often more efficient than other layers. The proposed LiCo-Net is a dual-phase system that uses the efficient int8 linear operators at the inference phase and applies streaming convolutions at the training phase to maintain a high model capacity. The experimental results show that LiCo-Net outperforms single-value decomposition filter (SVDF) on hardware efficiency with on-par detection performance. Compared to SVDF, LiCo-Net reduces cycles by 40% on HiFi4 DSP.