 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiCo-Net: Linearized Convolution Network for Hardware-efficient Keyword Spotting
Nov 09, 2022



This paper proposes a hardware-efficient architecture, Linearized Convolution Network (LiCo-Net) for keyword spotting. It is optimized specifically for low-power processor units like microcontrollers. ML operators exhibit heterogeneous efficiency profiles on power-efficient hardware. Given the exact theoretical computation cost, int8 operators are more computation-effective than float operators, and linear layers are often more efficient than other layers. The proposed LiCo-Net is a dual-phase system that uses the efficient int8 linear operators at the inference phase and applies streaming convolutions at the training phase to maintain a high model capacity. The experimental results show that LiCo-Net outperforms single-value decomposition filter (SVDF) on hardware efficiency with on-par detection performance. Compared to SVDF, LiCo-Net reduces cycles by 40% on HiFi4 DSP.
On the quantization of recurrent neural networks
Jan 14, 2021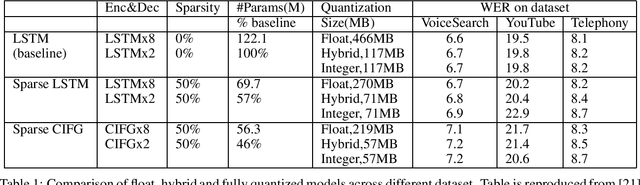
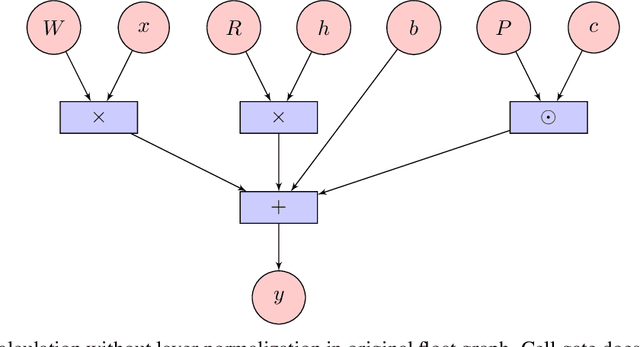
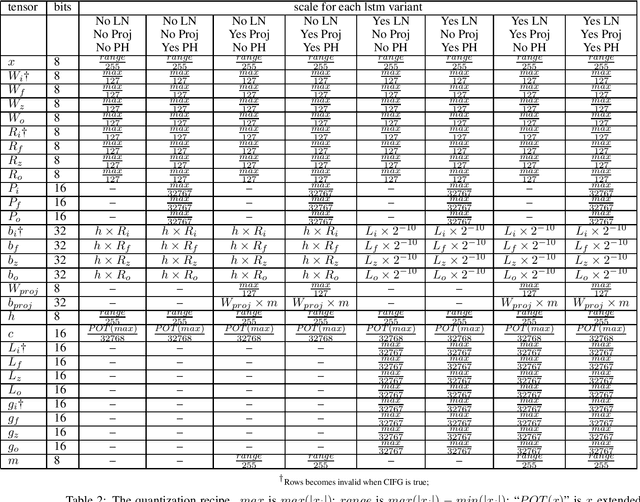
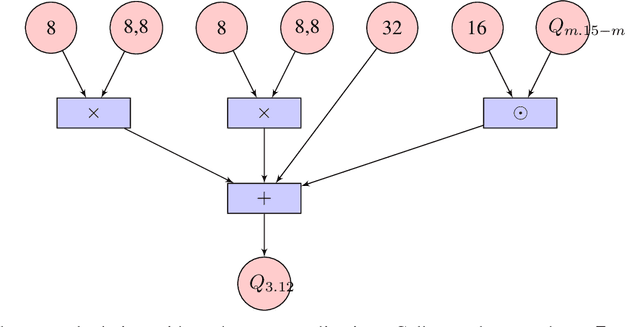
Integer quantization of neural networks can be defined as the approximation of the high precision computation of the canonical neural network formulation, using reduced integer precision. It plays a significant role in the efficient deployment and execution of machine learning (ML) systems, reducing memory consumption and leveraging typically faster computations. In this work, we present an integer-only quantization strategy for Long Short-Term Memory (LSTM) neural network topologies, which themselves are the foundation of many production ML systems. Our quantization strategy is accurate (e.g. works well with quantization post-training), efficient and fast to execute (utilizing 8 bit integer weights and mostly 8 bit activations), and is able to target a variety of hardware (by leveraging instructions sets available in common CPU architectures, as well as available neural accelerators).
A Streaming On-Device End-to-End Model Surpassing Server-Side Conventional Model Quality and Latency
Mar 28, 2020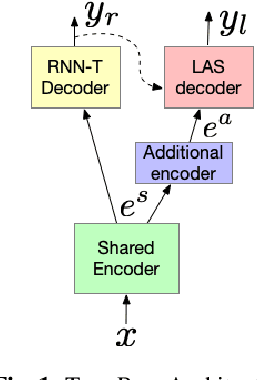
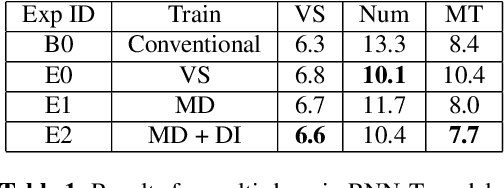
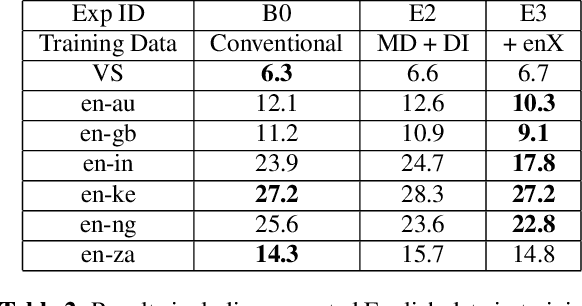
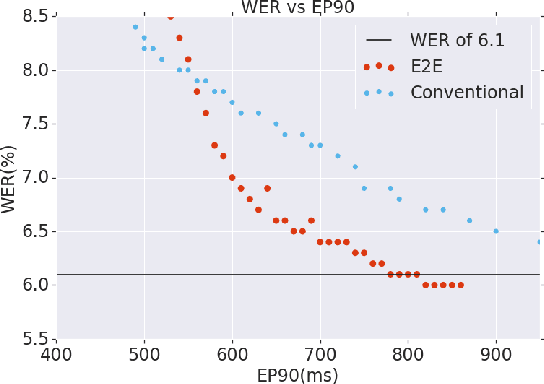
Thus far, end-to-end (E2E) models have not been shown to outperform state-of-the-art conventional models with respect to both quality, i.e., word error rate (WER), and latency, i.e., the time the hypothesis is finalized after the user stops speaking. In this paper, we develop a first-pass Recurrent Neural Network Transducer (RNN-T) model and a second-pass Listen, Attend, Spell (LAS) rescorer that surpasses a conventional model in both quality and latency. On the quality side, we incorporate a large number of utterances across varied domains to increase acoustic diversity and the vocabulary seen by the model. We also train with accented English speech to make the model more robust to different pronunciations. In addition, given the increased amount of training data, we explore a varied learning rate schedule. On the latency front, we explore using the end-of-sentence decision emitted by the RNN-T model to close the microphone, and also introduce various optimizations to improve the speed of LAS rescoring. Overall, we find that RNN-T+LAS offers a better WER and latency tradeoff compared to a conventional model. For example, for the same latency, RNN-T+LAS obtains a 8% relative improvement in WER, while being more than 400-times smaller in model size.
Optimizing Speech Recognition For The Edge
Sep 26, 2019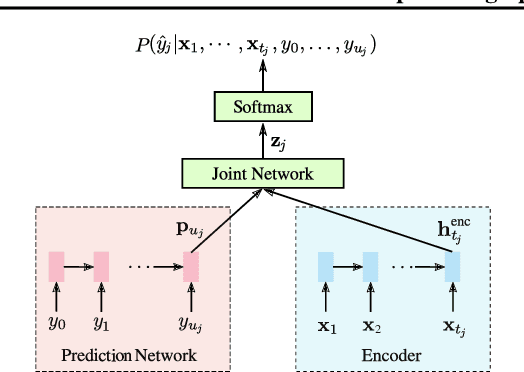



While most deployed speech recognition systems today still run on servers, we are in the midst of a transition towards deployments on edge devices. This leap to the edge is powered by the progression from traditional speech recognition pipelines to end-to-end (E2E) neural architectures, and the parallel development of more efficient neural network topologies and optimization techniques. Thus, we are now able to create highly accurate speech recognizers that are both small and fast enough to execute on typical mobile devices. In this paper, we begin with a baseline RNN-Transducer architecture comprised of Long Short-Term Memory (LSTM) layers. We then experiment with a variety of more computationally efficient layer types, as well as apply optimization techniques like neural connection pruning and parameter quantization to construct a small, high quality, on-device speech recognizer that is an order of magnitude smaller than the baseline system without any optimizations.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019
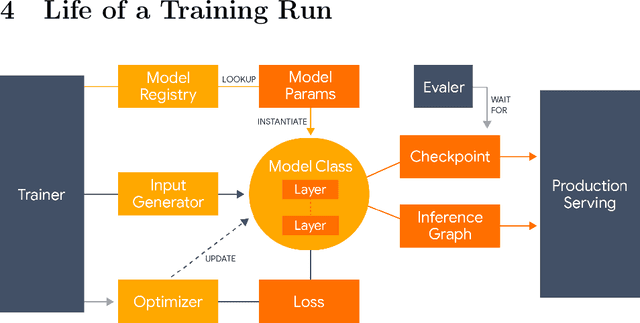
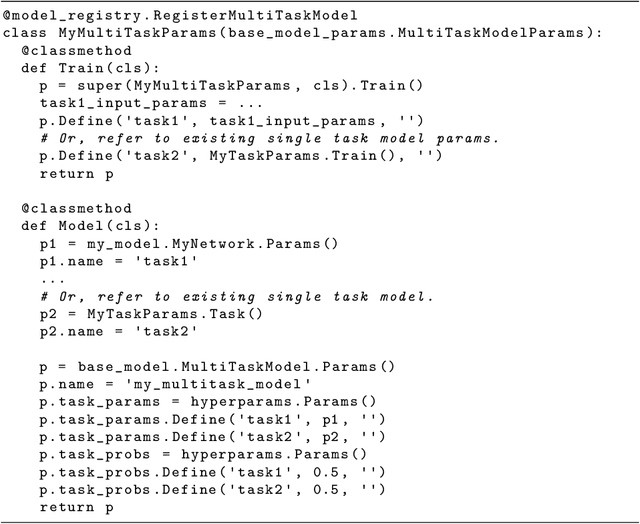
Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
Streaming End-to-end Speech Recognition For Mobile Devices
Nov 15, 2018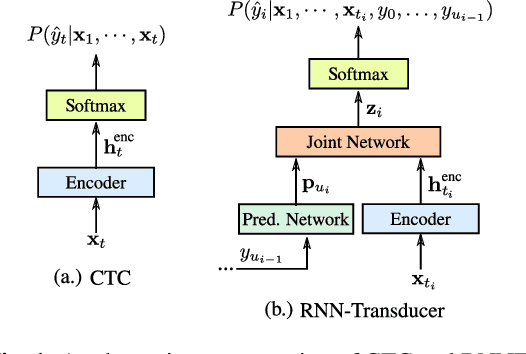
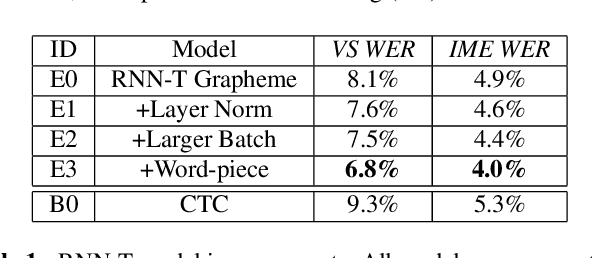
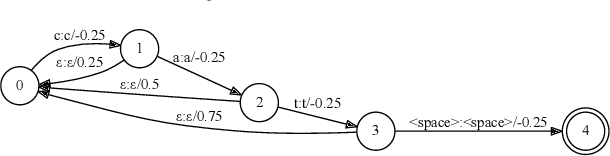
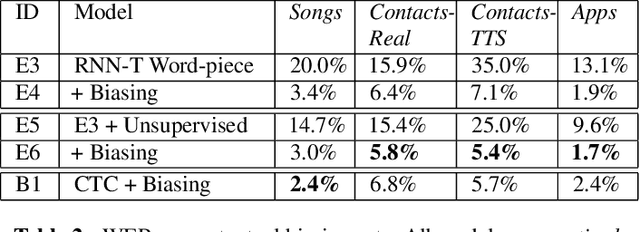
End-to-end (E2E) models, which directly predict output character sequences given input speech, are good candidates for on-device speech recognition. E2E models, however, present numerous challenges: In order to be truly useful, such models must decode speech utterances in a streaming fashion, in real time; they must be robust to the long tail of use cases; they must be able to leverage user-specific context (e.g., contact lists); and above all, they must be extremely accurate. In this work, we describe our efforts at building an E2E speech recognizer using a recurrent neural network transducer. In experimental evaluations, we find that the proposed approach can outperform a conventional CTC-based model in terms of both latency and accuracy in a number of evaluation categories.
On the efficient representation and execution of deep acoustic models
Dec 17, 2016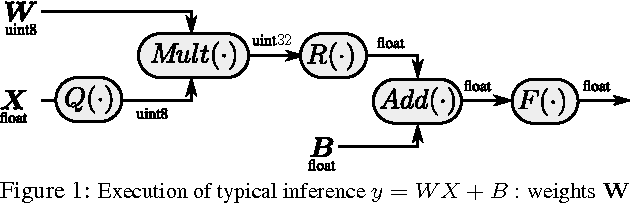

In this paper we present a simple and computationally efficient quantization scheme that enables us to reduce the resolution of the parameters of a neural network from 32-bit floating point values to 8-bit integer values. The proposed quantization scheme leads to significant memory savings and enables the use of optimized hardware instructions for integer arithmetic, thus significantly reducing the cost of inference. Finally, we propose a "quantization aware" training process that applies the proposed scheme during network training and find that it allows us to recover most of the loss in accuracy introduced by quantization. We validate the proposed techniques by applying them to a long short-term memory-based acoustic model on an open-ended large vocabulary speech recognition task.
Personalized Speech recognition on mobile devices
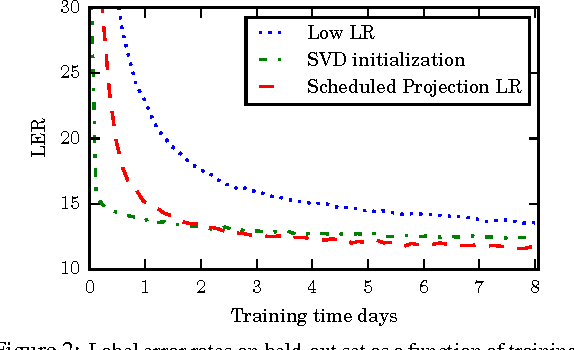
Mar 11, 2016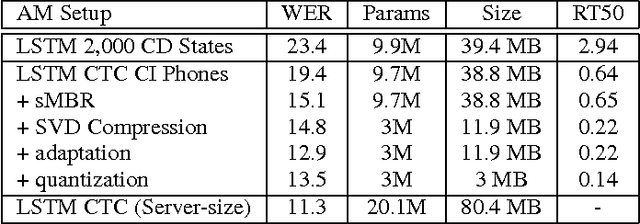
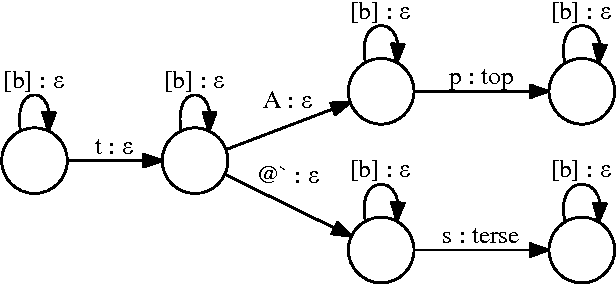

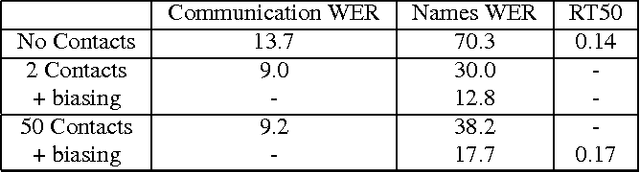
We describe a large vocabulary speech recognition system that is accurate, has low latency, and yet has a small enough memory and computational footprint to run faster than real-time on a Nexus 5 Android smartphone. We employ a quantized Long Short-Term Memory (LSTM) acoustic model trained with connectionist temporal classification (CTC) to directly predict phoneme targets, and further reduce its memory footprint using an SVD-based compression scheme. Additionally, we minimize our memory footprint by using a single language model for both dictation and voice command domains, constructed using Bayesian interpolation. Finally, in order to properly handle device-specific information, such as proper names and other context-dependent information, we inject vocabulary items into the decoder graph and bias the language model on-the-fly. Our system achieves 13.5% word error rate on an open-ended dictation task, running with a median speed that is seven times faster than real-time.