 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACE: A Time-Relational Approximate Cubing Engine for Fast Data Insights
Jan 12, 2024A large class of data questions can be modeled as identifying important slices of data driven by user defined metrics. This paper presents TRACE, a Time-Relational Approximate Cubing Engine that enables interactive analysis on such slices with a low upfront cost - both in space and computation. It does this by materializing the most important parts of the cube over time enabling interactive querying for a large class of analytical queries e.g. what part of my business has the highest revenue growth ([SubCategory=Sports Equipment, Gender=Female]), what slices are lagging in revenue per user ([State=CA, Age=20-30]). Many user defined metrics are supported including common aggregations such as SUM, COUNT, DISTINCT COUNT and more complex ones such as AVERAGE. We implemented and deployed TRACE for a variety of business use cases.
Training Text-To-Speech Systems From Synthetic Data: A Practical Approach For Accent Transfer Tasks
Aug 28, 2022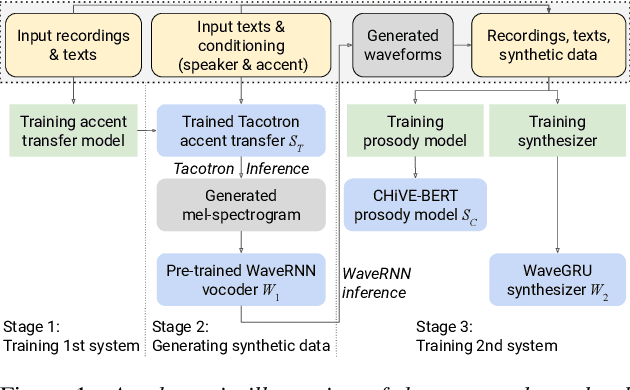
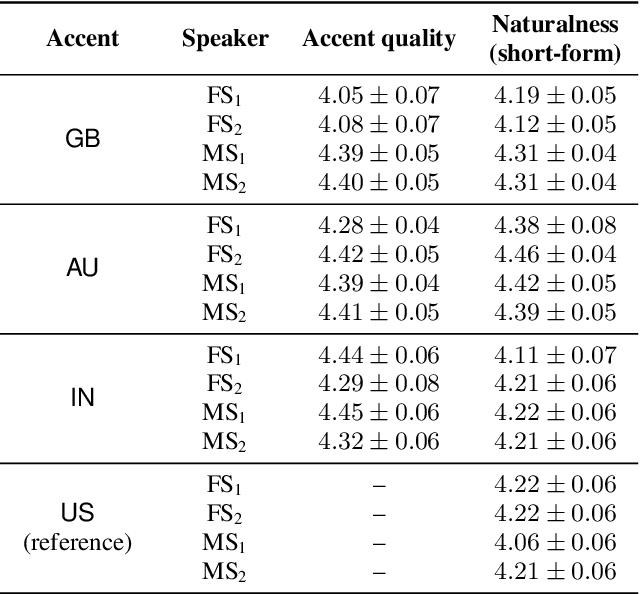
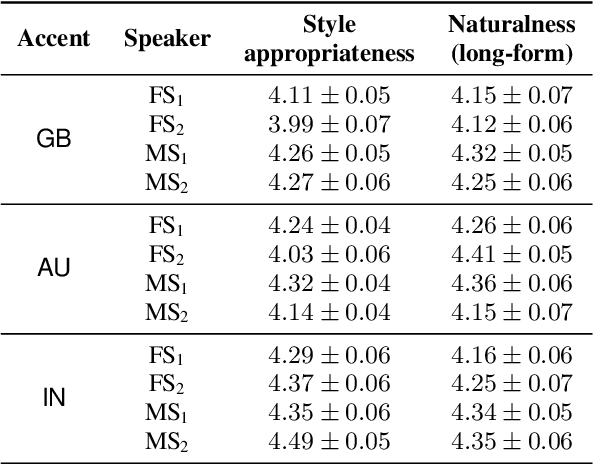
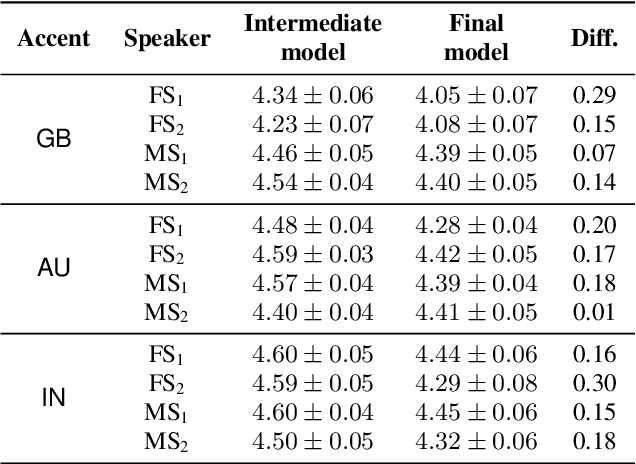
Transfer tasks in text-to-speech (TTS) synthesis - where one or more aspects of the speech of one set of speakers is transferred to another set of speakers that do not feature these aspects originally - remains a challenging task. One of the challenges is that models that have high-quality transfer capabilities can have issues in stability, making them impractical for user-facing critical tasks. This paper demonstrates that transfer can be obtained by training a robust TTS system on data generated by a less robust TTS system designed for a high-quality transfer task; in particular, a CHiVE-BERT monolingual TTS system is trained on the output of a Tacotron model designed for accent transfer. While some quality loss is inevitable with this approach, experimental results show that the models trained on synthetic data this way can produce high quality audio displaying accent transfer, while preserving speaker characteristics such as speaking style.
Examining Scaling and Transfer of Language Model Architectures for Machine Translation
Feb 16, 2022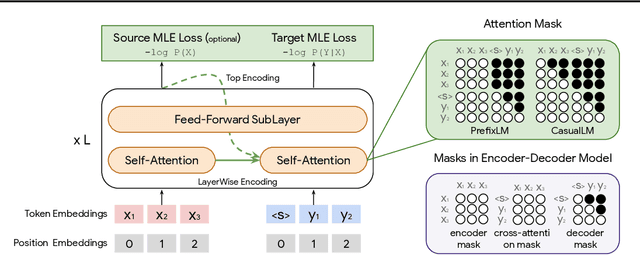

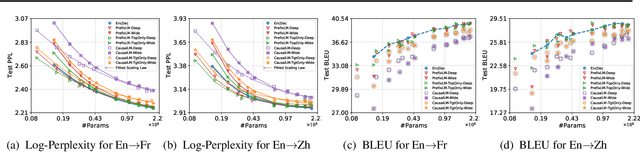
Natural language understanding and generation models follow one of the two dominant architectural paradigms: language models (LMs) that process concatenated sequences in a single stack of layers, and encoder-decoder models (EncDec) that utilize separate layer stacks for input and output processing. In machine translation, EncDec has long been the favoured approach, but with few studies investigating the performance of LMs. In this work, we thoroughly examine the role of several architectural design choices on the performance of LMs on bilingual, (massively) multilingual and zero-shot translation tasks, under systematic variations of data conditions and model sizes. Our results show that: (i) Different LMs have different scaling properties, where architectural differences often have a significant impact on model performance at small scales, but the performance gap narrows as the number of parameters increases, (ii) Several design choices, including causal masking and language-modeling objectives for the source sequence, have detrimental effects on translation quality, and (iii) When paired with full-visible masking for source sequences, LMs could perform on par with EncDec on supervised bilingual and multilingual translation tasks, and improve greatly on zero-shot directions by facilitating the reduction of off-target translations.
Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Apr 13, 2021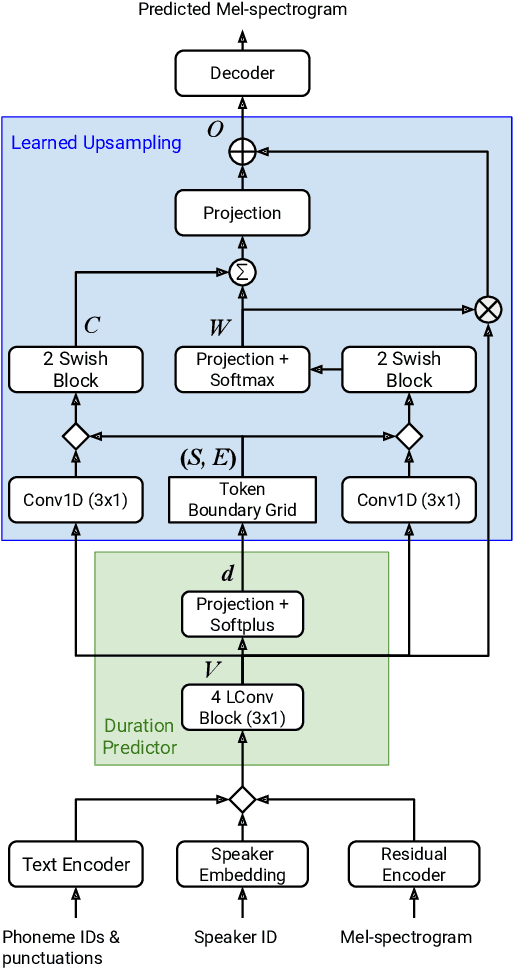
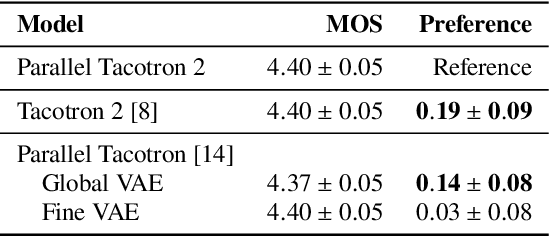
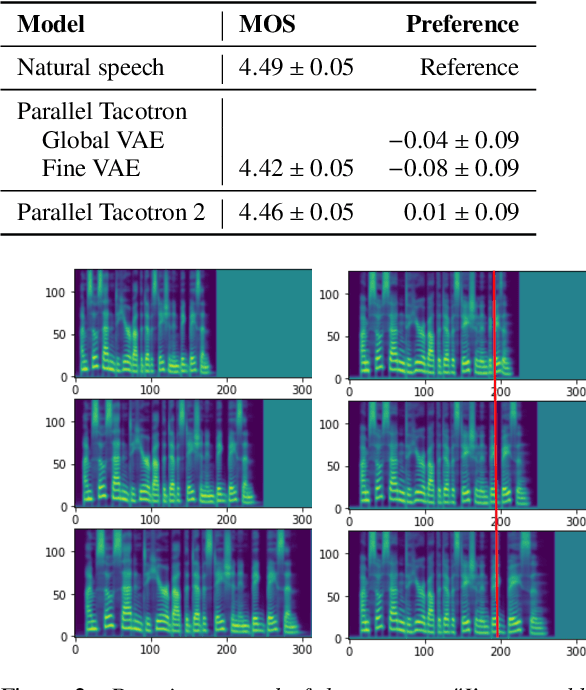

This paper introduces Parallel Tacotron 2, a non-autoregressive neural text-to-speech model with a fully differentiable duration model which does not require supervised duration signals. The duration model is based on a novel attention mechanism and an iterative reconstruction loss based on Soft Dynamic Time Warping, this model can learn token-frame alignments as well as token durations automatically. Experimental results show that Parallel Tacotron 2 outperforms baselines in subjective naturalness in several diverse multi speaker evaluations. Its duration control capability is also demonstrated.
PnG BERT: Augmented BERT on Phonemes and Graphemes for Neural TTS
Apr 02, 2021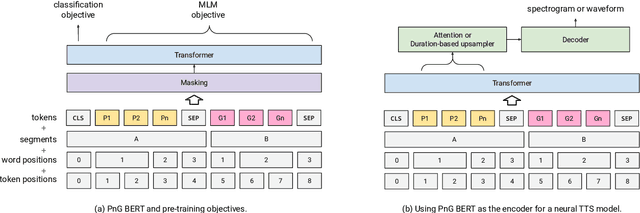
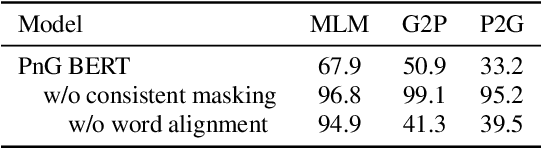
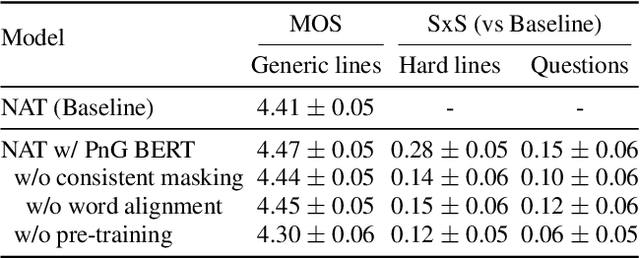
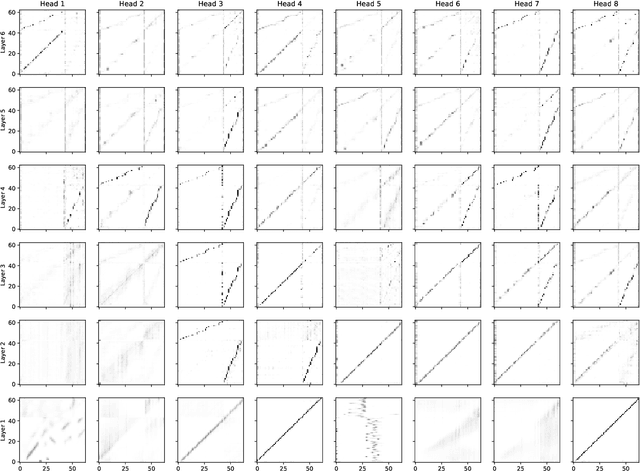
This paper introduces PnG BERT, a new encoder model for neural TTS. This model is augmented from the original BERT model, by taking both phoneme and grapheme representations of text as input, as well as the word-level alignment between them. It can be pre-trained on a large text corpus in a self-supervised manner, and fine-tuned in a TTS task. Experimental results show that a neural TTS model using a pre-trained PnG BERT as its encoder yields more natural prosody and more accurate pronunciation than a baseline model using only phoneme input with no pre-training. Subjective side-by-side preference evaluations show that raters have no statistically significant preference between the speech synthesized using a PnG BERT and ground truth recordings from professional speakers.
Non-Attentive Tacotron: Robust and Controllable Neural TTS Synthesis Including Unsupervised Duration Modeling
Oct 08, 2020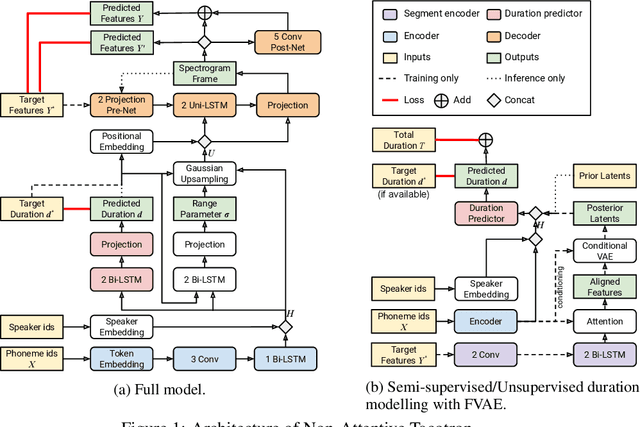

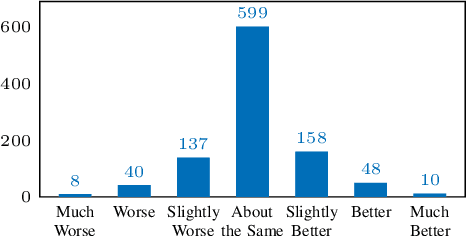

This paper presents Non-Attentive Tacotron based on the Tacotron 2 text-to-speech model, replacing the attention mechanism with an explicit duration predictor. This improves robustness significantly as measured by unaligned duration ratio and word deletion rate, two metrics introduced in this paper for large-scale robustness evaluation using a pre-trained speech recognition model. With the use of Gaussian upsampling, Non-Attentive Tacotron achieves a 5-scale mean opinion score for naturalness of 4.41, slightly outperforming Tacotron 2. The duration predictor enables both utterance-wide and per-phoneme control of duration at inference time. When accurate target durations are scarce or unavailable in the training data, we propose a method using a fine-grained variational auto-encoder to train the duration predictor in a semi-supervised or unsupervised manner, with results almost as good as supervised training.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019
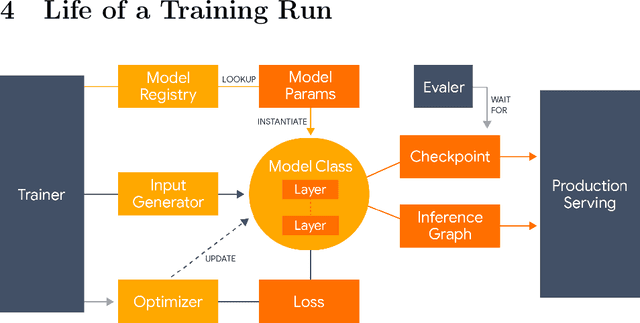
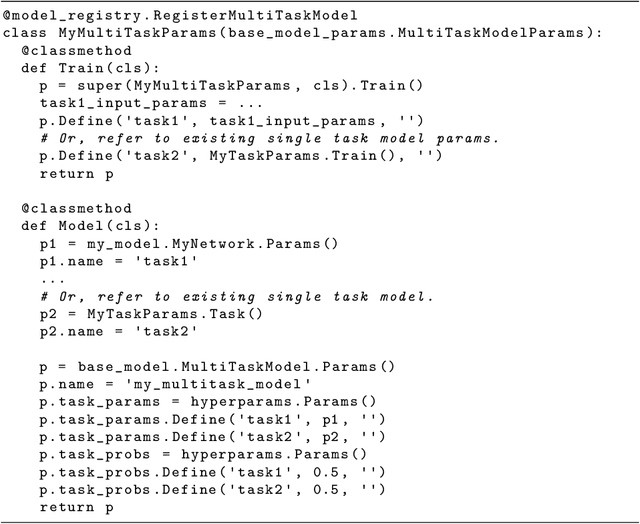
Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
Nov 05, 2018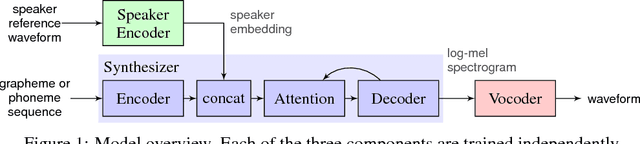

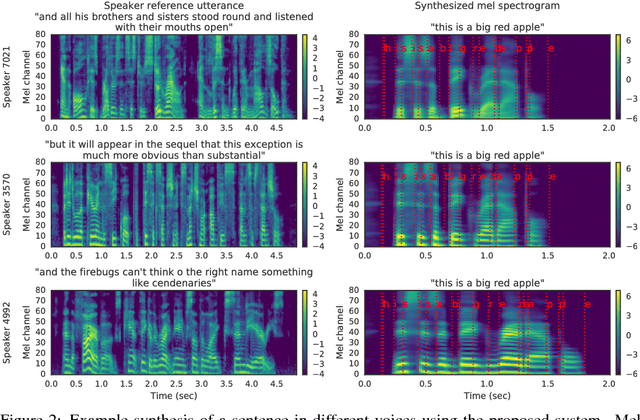
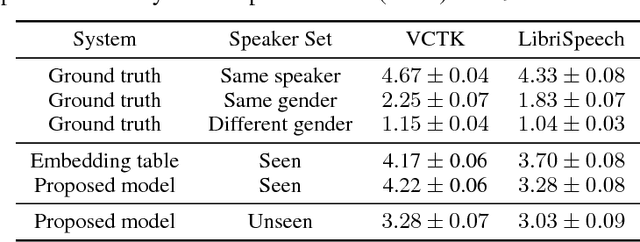
We describe a neural network-based system for text-to-speech (TTS) synthesis that is able to generate speech audio in the voice of many different speakers, including those unseen during training. Our system consists of three independently trained components: (1) a speaker encoder network, trained on a speaker verification task using an independent dataset of noisy speech from thousands of speakers without transcripts, to generate a fixed-dimensional embedding vector from seconds of reference speech from a target speaker; (2) a sequence-to-sequence synthesis network based on Tacotron 2, which generates a mel spectrogram from text, conditioned on the speaker embedding; (3) an auto-regressive WaveNet-based vocoder that converts the mel spectrogram into a sequence of time domain waveform samples. We demonstrate that the proposed model is able to transfer the knowledge of speaker variability learned by the discriminatively-trained speaker encoder to the new task, and is able to synthesize natural speech from speakers that were not seen during training. We quantify the importance of training the speaker encoder on a large and diverse speaker set in order to obtain the best generalization performance. Finally, we show that randomly sampled speaker embeddings can be used to synthesize speech in the voice of novel speakers dissimilar from those used in training, indicating that the model has learned a high quality speaker representation.
Hierarchical Generative Modeling for Controllable Speech Synthesis
Oct 16, 2018
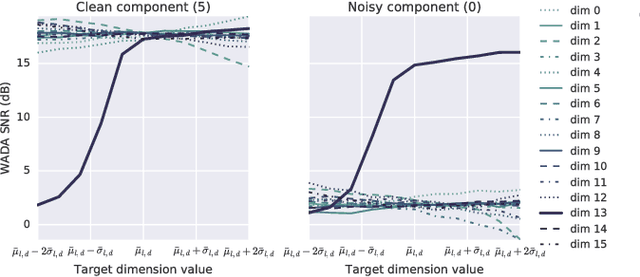
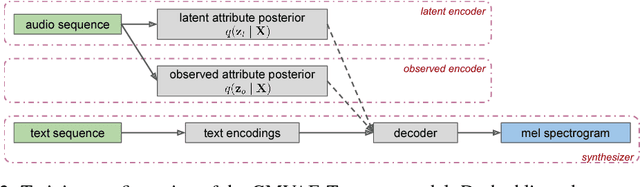

This paper proposes a neural end-to-end text-to-speech (TTS) model which can control latent attributes in the generated speech that are rarely annotated in the training data, such as speaking style, accent, background noise, and recording conditions. The model is formulated as a conditional generative model with two levels of hierarchical latent variables. The first level is a categorical variable, which represents attribute groups (e.g. clean/noisy) and provides interpretability. The second level, conditioned on the first, is a multivariate Gaussian variable, which characterizes specific attribute configurations (e.g. noise level, speaking rate) and enables disentangled fine-grained control over these attributes. This amounts to using a Gaussian mixture model (GMM) for the latent distribution. Extensive evaluation demonstrates its ability to control the aforementioned attributes. In particular, it is capable of consistently synthesizing high-quality clean speech regardless of the quality of the training data for the target speaker.
Neural Program Synthesis with Priority Queue Training
Mar 23, 2018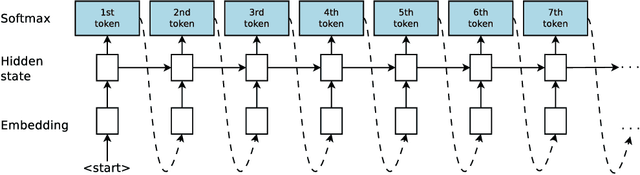


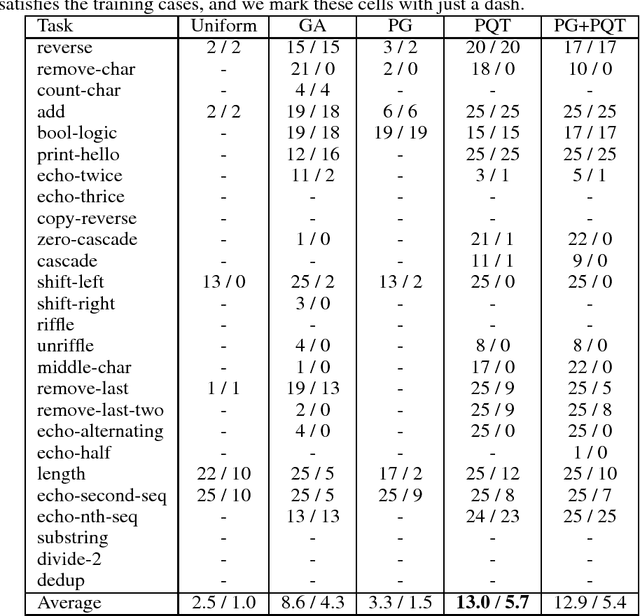
We consider the task of program synthesis in the presence of a reward function over the output of programs, where the goal is to find programs with maximal rewards. We employ an iterative optimization scheme, where we train an RNN on a dataset of K best programs from a priority queue of the generated programs so far. Then, we synthesize new programs and add them to the priority queue by sampling from the RNN. We benchmark our algorithm, called priority queue training (or PQT), against genetic algorithm and reinforcement learning baselines on a simple but expressive Turing complete programming language called BF. Our experimental results show that our simple PQT algorithm significantly outperforms the baselines. By adding a program length penalty to the reward function, we are able to synthesize short, human readable programs.