 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Training Text-To-Speech Systems From Synthetic Data: A Practical Approach For Accent Transfer Tasks
Aug 28, 2022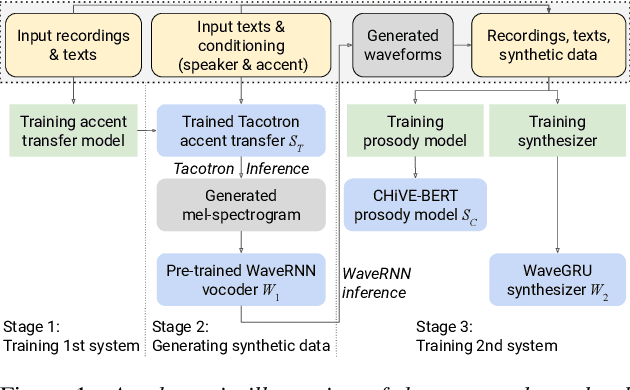
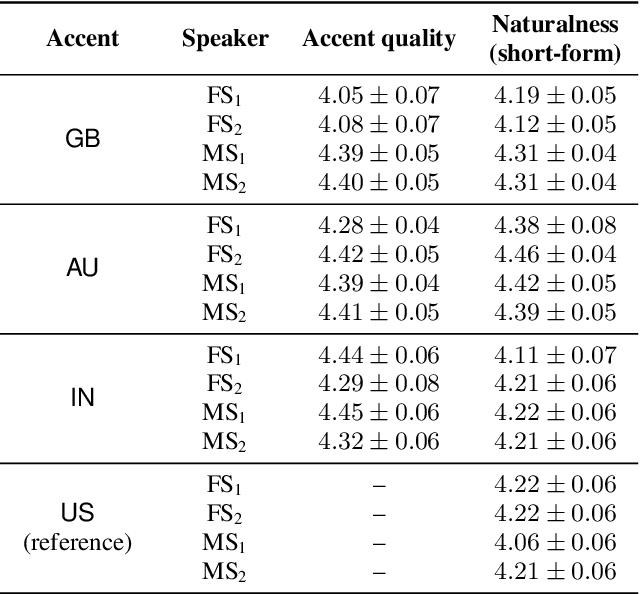
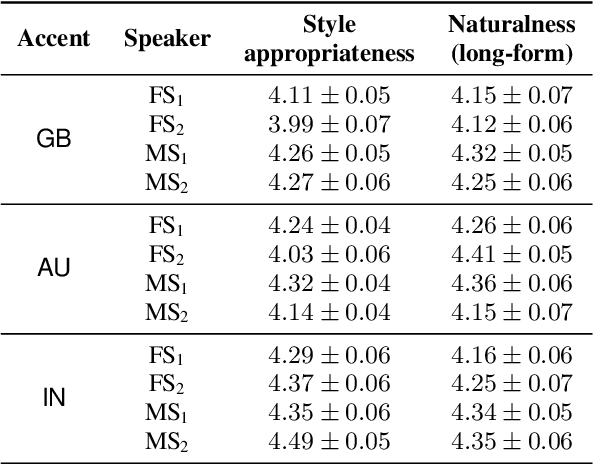
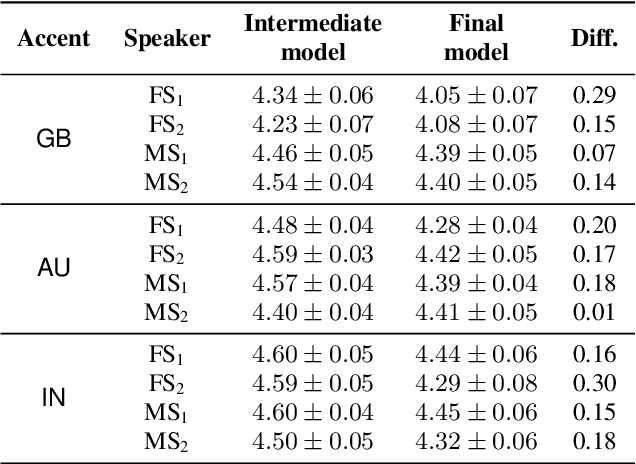
Transfer tasks in text-to-speech (TTS) synthesis - where one or more aspects of the speech of one set of speakers is transferred to another set of speakers that do not feature these aspects originally - remains a challenging task. One of the challenges is that models that have high-quality transfer capabilities can have issues in stability, making them impractical for user-facing critical tasks. This paper demonstrates that transfer can be obtained by training a robust TTS system on data generated by a less robust TTS system designed for a high-quality transfer task; in particular, a CHiVE-BERT monolingual TTS system is trained on the output of a Tacotron model designed for accent transfer. While some quality loss is inevitable with this approach, experimental results show that the models trained on synthetic data this way can produce high quality audio displaying accent transfer, while preserving speaker characteristics such as speaking style.
Towards transformation-resilient provenance detection of digital media
Nov 14, 2020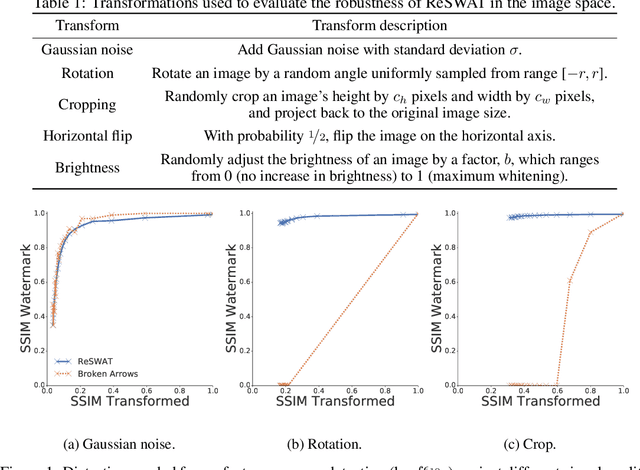
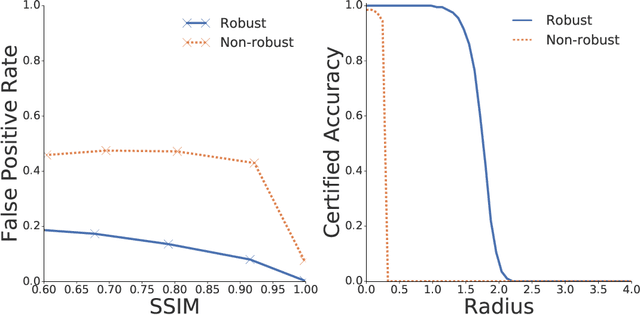

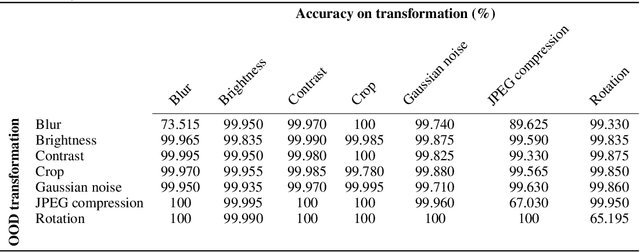
Advancements in deep generative models have made it possible to synthesize images, videos and audio signals that are difficult to distinguish from natural signals, creating opportunities for potential abuse of these capabilities. This motivates the problem of tracking the provenance of signals, i.e., being able to determine the original source of a signal. Watermarking the signal at the time of signal creation is a potential solution, but current techniques are brittle and watermark detection mechanisms can easily be bypassed by applying post-processing transformations (cropping images, shifting pitch in the audio etc.). In this paper, we introduce ReSWAT (Resilient Signal Watermarking via Adversarial Training), a framework for learning transformation-resilient watermark detectors that are able to detect a watermark even after a signal has been through several post-processing transformations. Our detection method can be applied to domains with continuous data representations such as images, videos or sound signals. Experiments on watermarking image and audio signals show that our method can reliably detect the provenance of a signal, even if it has been through several post-processing transformations, and improve upon related work in this setting. Furthermore, we show that for specific kinds of transformations (perturbations bounded in the L2 norm), we can even get formal guarantees on the ability of our model to detect the watermark. We provide qualitative examples of watermarked image and audio samples in https://drive.google.com/open?id=1-yZ0WIGNu2Iez7UpXBjtjVgZu3jJjFga.
High Fidelity Speech Synthesis with Adversarial Networks
Sep 26, 2019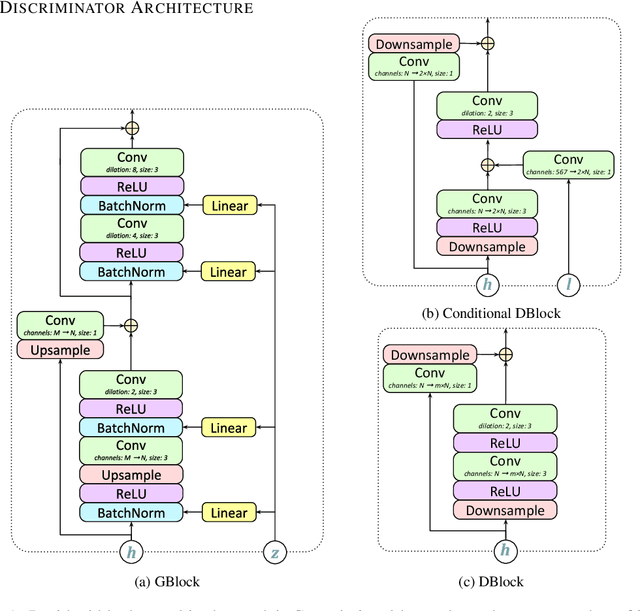
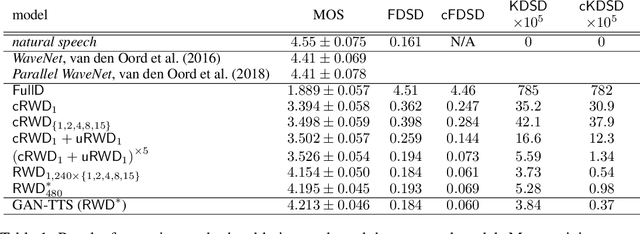
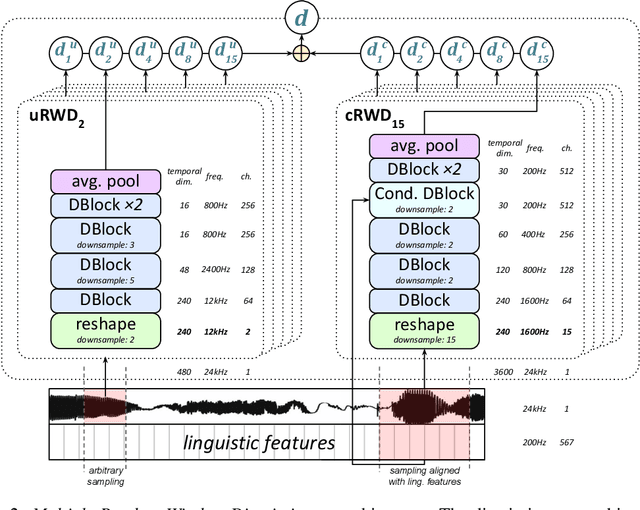

Generative adversarial networks have seen rapid development in recent years and have led to remarkable improvements in generative modelling of images. However, their application in the audio domain has received limited attention, and autoregressive models, such as WaveNet, remain the state of the art in generative modelling of audio signals such as human speech. To address this paucity, we introduce GAN-TTS, a Generative Adversarial Network for Text-to-Speech. Our architecture is composed of a conditional feed-forward generator producing raw speech audio, and an ensemble of discriminators which operate on random windows of different sizes. The discriminators analyse the audio both in terms of general realism, as well as how well the audio corresponds to the utterance that should be pronounced. To measure the performance of GAN-TTS, we employ both subjective human evaluation (MOS - Mean Opinion Score), as well as novel quantitative metrics (Fr\'echet DeepSpeech Distance and Kernel DeepSpeech Distance), which we find to be well correlated with MOS. We show that GAN-TTS is capable of generating high-fidelity speech with naturalness comparable to the state-of-the-art models, and unlike autoregressive models, it is highly parallelisable thanks to an efficient feed-forward generator. Listen to GAN-TTS reading this abstract at https://storage.googleapis.com/deepmind-media/research/abstract.wav.
Efficient Neural Audio Synthesis
Jun 25, 2018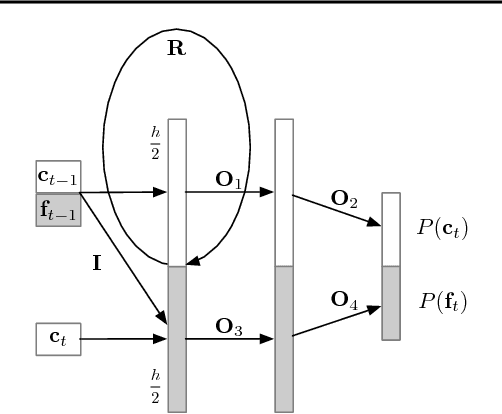

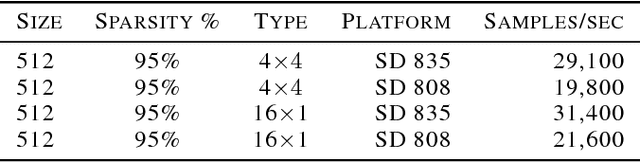
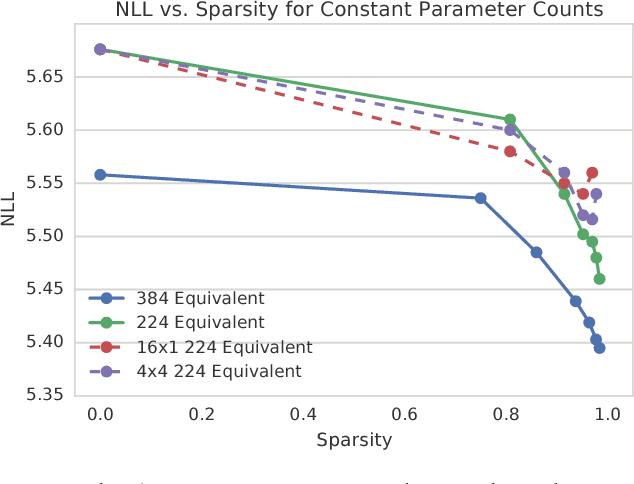
Sequential models achieve state-of-the-art results in audio, visual and textual domains with respect to both estimating the data distribution and generating high-quality samples. Efficient sampling for this class of models has however remained an elusive problem. With a focus on text-to-speech synthesis, we describe a set of general techniques for reducing sampling time while maintaining high output quality. We first describe a single-layer recurrent neural network, the WaveRNN, with a dual softmax layer that matches the quality of the state-of-the-art WaveNet model. The compact form of the network makes it possible to generate 24kHz 16-bit audio 4x faster than real time on a GPU. Second, we apply a weight pruning technique to reduce the number of weights in the WaveRNN. We find that, for a constant number of parameters, large sparse networks perform better than small dense networks and this relationship holds for sparsity levels beyond 96%. The small number of weights in a Sparse WaveRNN makes it possible to sample high-fidelity audio on a mobile CPU in real time. Finally, we propose a new generation scheme based on subscaling that folds a long sequence into a batch of shorter sequences and allows one to generate multiple samples at once. The Subscale WaveRNN produces 16 samples per step without loss of quality and offers an orthogonal method for increasing sampling efficiency.
Parallel WaveNet: Fast High-Fidelity Speech Synthesis
Nov 28, 2017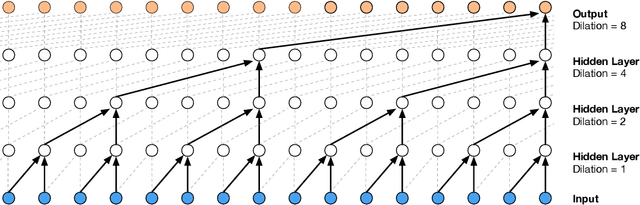
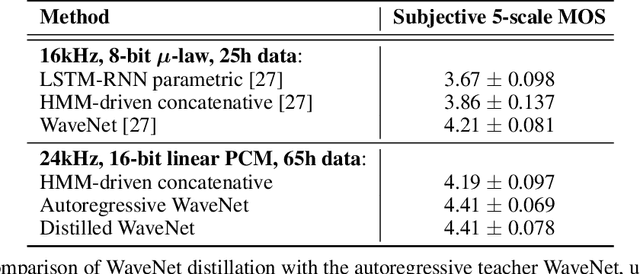
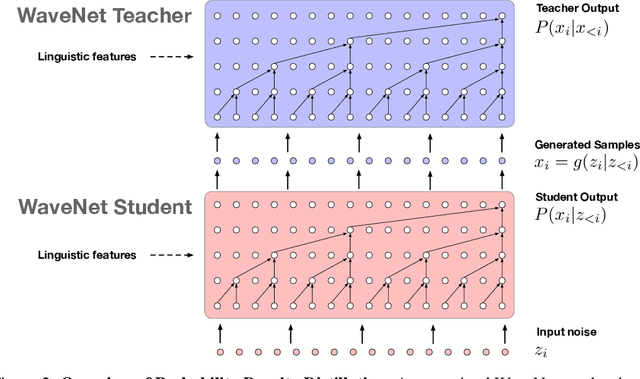
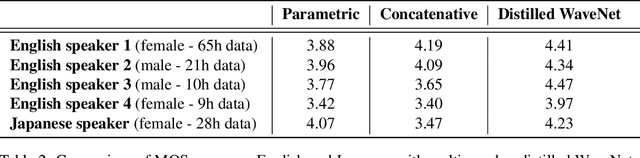
The recently-developed WaveNet architecture is the current state of the art in realistic speech synthesis, consistently rated as more natural sounding for many different languages than any previous system. However, because WaveNet relies on sequential generation of one audio sample at a time, it is poorly suited to today's massively parallel computers, and therefore hard to deploy in a real-time production setting. This paper introduces Probability Density Distillation, a new method for training a parallel feed-forward network from a trained WaveNet with no significant difference in quality. The resulting system is capable of generating high-fidelity speech samples at more than 20 times faster than real-time, and is deployed online by Google Assistant, including serving multiple English and Japanese voices.