 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Day Forecasts from Sparse Observations
Jun 12, 2023



Deep neural networks offer an alternative paradigm for modeling weather conditions. The ability of neural models to make a prediction in less than a second once the data is available and to do so with very high temporal and spatial resolution, and the ability to learn directly from atmospheric observations, are just some of these models' unique advantages. Neural models trained using atmospheric observations, the highest fidelity and lowest latency data, have to date achieved good performance only up to twelve hours of lead time when compared with state-of-the-art probabilistic Numerical Weather Prediction models and only for the sole variable of precipitation. In this paper, we present MetNet-3 that extends significantly both the lead time range and the variables that an observation based neural model can predict well. MetNet-3 learns from both dense and sparse data sensors and makes predictions up to 24 hours ahead for precipitation, wind, temperature and dew point. MetNet-3 introduces a key densification technique that implicitly captures data assimilation and produces spatially dense forecasts in spite of the network training on extremely sparse targets. MetNet-3 has a high temporal and spatial resolution of, respectively, up to 2 minutes and 1 km as well as a low operational latency. We find that MetNet-3 is able to outperform the best single- and multi-member NWPs such as HRRR and ENS over the CONUS region for up to 24 hours ahead setting a new performance milestone for observation based neural models. MetNet-3 is operational and its forecasts are served in Google Search in conjunction with other models.
On the surprising tradeoff between ImageNet accuracy and perceptual similarity
Mar 09, 2022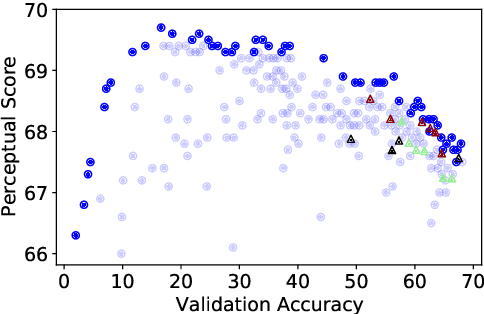
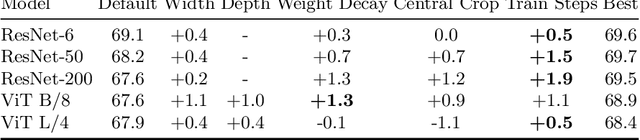
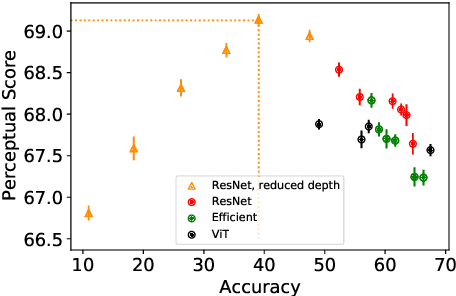
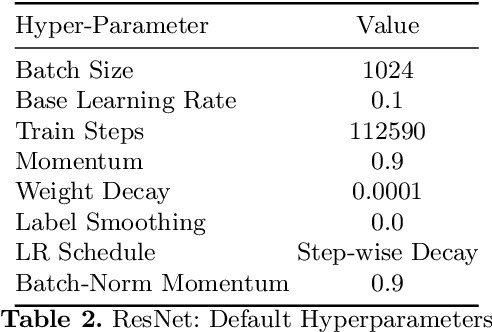
Perceptual distances between images, as measured in the space of pre-trained deep features, have outperformed prior low-level, pixel-based metrics on assessing image similarity. While the capabilities of older and less accurate models such as AlexNet and VGG to capture perceptual similarity are well known, modern and more accurate models are less studied. First, we observe a surprising inverse correlation between ImageNet accuracy and Perceptual Scores of modern networks such as ResNets, EfficientNets, and Vision Transformers: that is better classifiers achieve worse Perceptual Scores. Then, we perform a large-scale study and examine the ImageNet accuracy/Perceptual Score relationship on varying the depth, width, number of training steps, weight decay, label smoothing, and dropout. Higher accuracy improves Perceptual Score up to a certain point, but we uncover a Pareto frontier between accuracies and Perceptual Score in the mid-to-high accuracy regime. We explore this relationship further using distortion invariance, spatial frequency sensitivity, and alternative perceptual functions. Interestingly we discover shallow ResNets, trained for less than 5 epochs only on ImageNet, whose emergent Perceptual Score matches the prior best networks trained directly on supervised human perceptual judgements.
Skillful Twelve Hour Precipitation Forecasts using Large Context Neural Networks
Nov 14, 2021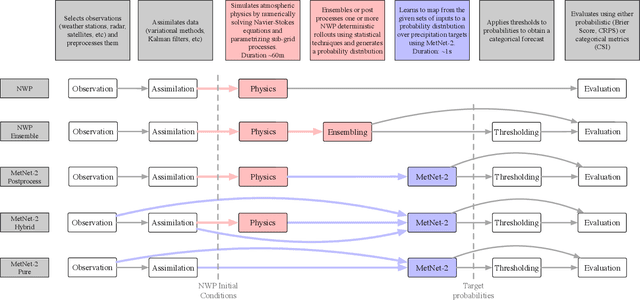
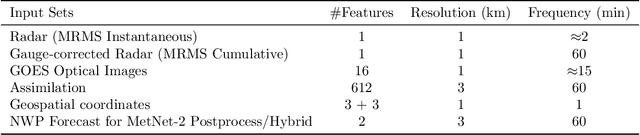
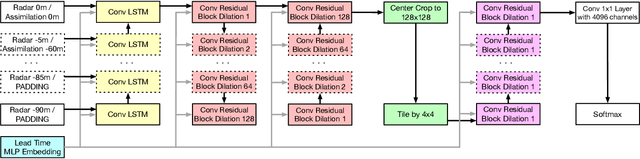

The problem of forecasting weather has been scientifically studied for centuries due to its high impact on human lives, transportation, food production and energy management, among others. Current operational forecasting models are based on physics and use supercomputers to simulate the atmosphere to make forecasts hours and days in advance. Better physics-based forecasts require improvements in the models themselves, which can be a substantial scientific challenge, as well as improvements in the underlying resolution, which can be computationally prohibitive. An emerging class of weather models based on neural networks represents a paradigm shift in weather forecasting: the models learn the required transformations from data instead of relying on hand-coded physics and are computationally efficient. For neural models, however, each additional hour of lead time poses a substantial challenge as it requires capturing ever larger spatial contexts and increases the uncertainty of the prediction. In this work, we present a neural network that is capable of large-scale precipitation forecasting up to twelve hours ahead and, starting from the same atmospheric state, the model achieves greater skill than the state-of-the-art physics-based models HRRR and HREF that currently operate in the Continental United States. Interpretability analyses reinforce the observation that the model learns to emulate advanced physics principles. These results represent a substantial step towards establishing a new paradigm of efficient forecasting with neural networks.
Gradual Domain Adaptation in the Wild:When Intermediate Distributions are Absent
Jun 10, 2021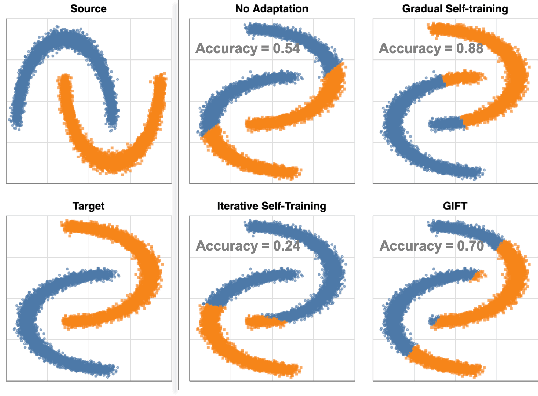
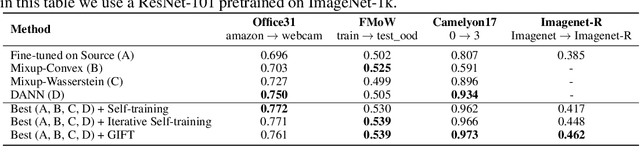

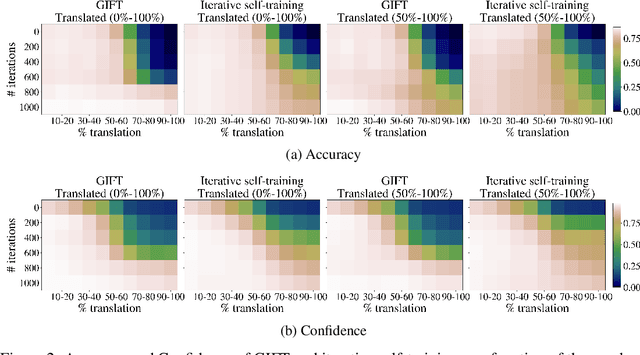
We focus on the problem of domain adaptation when the goal is shifting the model towards the target distribution, rather than learning domain invariant representations. It has been shown that under the following two assumptions: (a) access to samples from intermediate distributions, and (b) samples being annotated with the amount of change from the source distribution, self-training can be successfully applied on gradually shifted samples to adapt the model toward the target distribution. We hypothesize having (a) is enough to enable iterative self-training to slowly adapt the model to the target distribution, by making use of an implicit curriculum. In the case where (a) does not hold, we observe that iterative self-training falls short. We propose GIFT, a method that creates virtual samples from intermediate distributions by interpolating representations of examples from source and target domains. We evaluate an iterative-self-training method on datasets with natural distribution shifts, and show that when applied on top of other domain adaptation methods, it improves the performance of the model on the target dataset. We run an analysis on a synthetic dataset to show that in the presence of (a) iterative-self-training naturally forms a curriculum of samples. Furthermore, we show that when (a) does not hold, GIFT performs better than iterative self-training.
Colorization Transformer
Mar 07, 2021

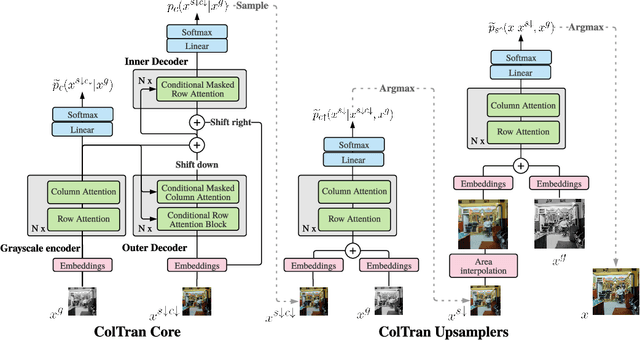
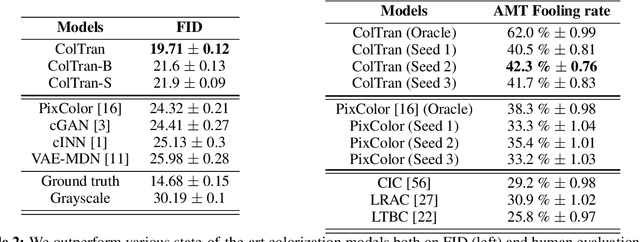
We present the Colorization Transformer, a novel approach for diverse high fidelity image colorization based on self-attention. Given a grayscale image, the colorization proceeds in three steps. We first use a conditional autoregressive transformer to produce a low resolution coarse coloring of the grayscale image. Our architecture adopts conditional transformer layers to effectively condition grayscale input. Two subsequent fully parallel networks upsample the coarse colored low resolution image into a finely colored high resolution image. Sampling from the Colorization Transformer produces diverse colorings whose fidelity outperforms the previous state-of-the-art on colorising ImageNet based on FID results and based on a human evaluation in a Mechanical Turk test. Remarkably, in more than 60% of cases human evaluators prefer the highest rated among three generated colorings over the ground truth. The code and pre-trained checkpoints for Colorization Transformer are publicly available at https://github.com/google-research/google-research/tree/master/coltran
Towards Causal Representation Learning
Feb 22, 2021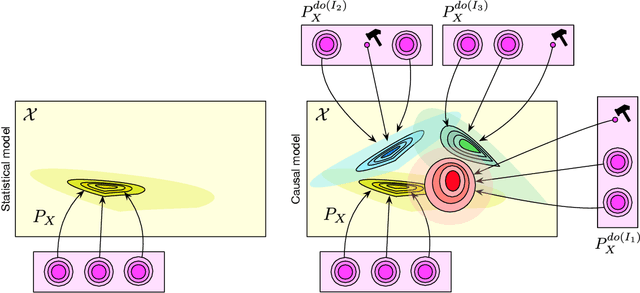

The two fields of machine learning and graphical causality arose and developed separately. However, there is now cross-pollination and increasing interest in both fields to benefit from the advances of the other. In the present paper, we review fundamental concepts of causal inference and relate them to crucial open problems of machine learning, including transfer and generalization, thereby assaying how causality can contribute to modern machine learning research. This also applies in the opposite direction: we note that most work in causality starts from the premise that the causal variables are given. A central problem for AI and causality is, thus, causal representation learning, the discovery of high-level causal variables from low-level observations. Finally, we delineate some implications of causality for machine learning and propose key research areas at the intersection of both communities.
A Spectral Energy Distance for Parallel Speech Synthesis
Aug 03, 2020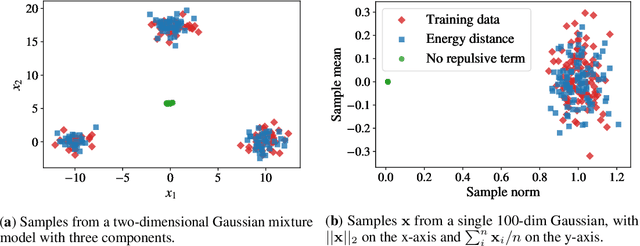
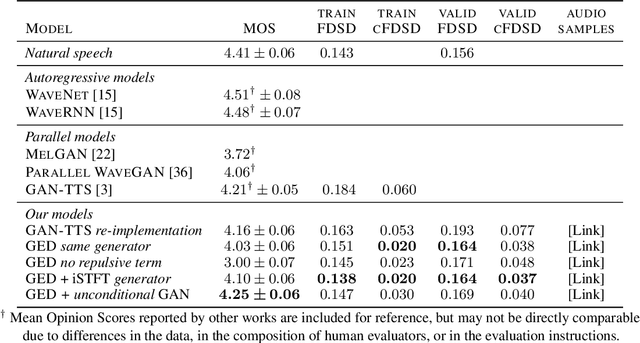
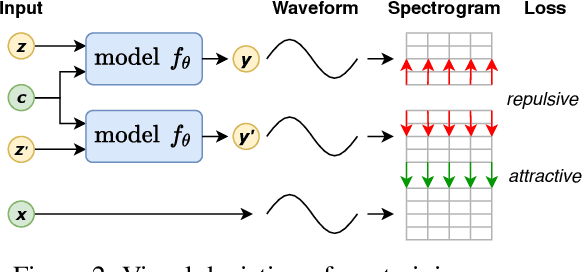
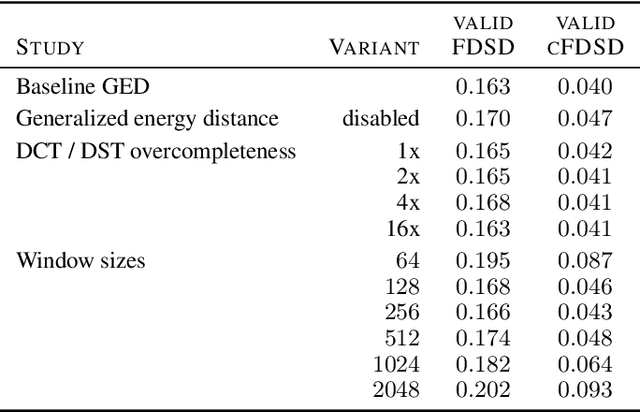
Speech synthesis is an important practical generative modeling problem that has seen great progress over the last few years, with likelihood-based autoregressive neural models now outperforming traditional concatenative systems. A downside of such autoregressive models is that they require executing tens of thousands of sequential operations per second of generated audio, making them ill-suited for deployment on specialized deep learning hardware. Here, we propose a new learning method that allows us to train highly parallel models of speech, without requiring access to an analytical likelihood function. Our approach is based on a generalized energy distance between the distributions of the generated and real audio. This spectral energy distance is a proper scoring rule with respect to the distribution over magnitude-spectrograms of the generated waveform audio and offers statistical consistency guarantees. The distance can be calculated from minibatches without bias, and does not involve adversarial learning, yielding a stable and consistent method for training implicit generative models. Empirically, we achieve state-of-the-art generation quality among implicit generative models, as judged by the recently-proposed cFDSD metric. When combining our method with adversarial techniques, we also improve upon the recently-proposed GAN-TTS model in terms of Mean Opinion Score as judged by trained human evaluators.
Deep Learning Based Text Classification: A Comprehensive Review
Apr 06, 2020
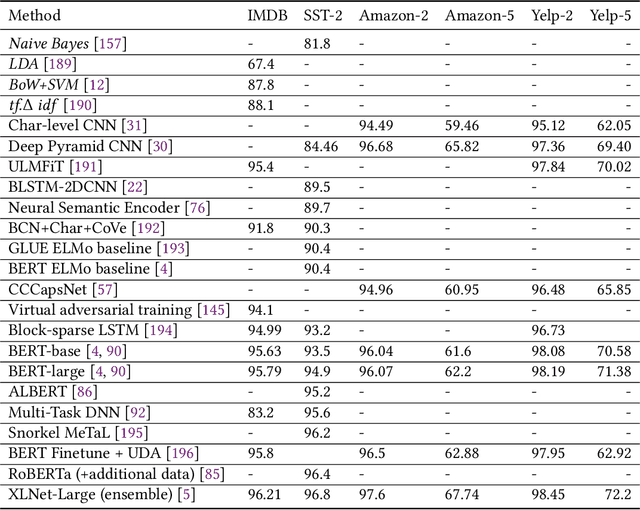
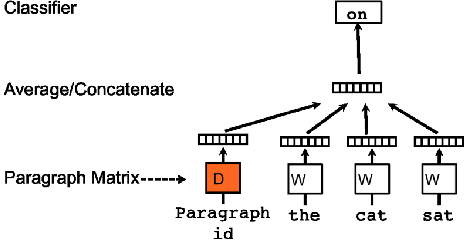
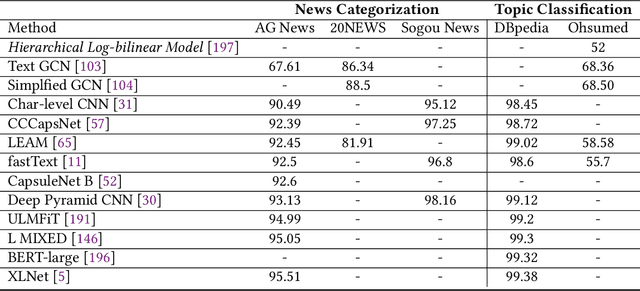
Deep learning based models have surpassed classical machine learning based approaches in various text classification tasks, including sentiment analysis, news categorization, question answering, and natural language inference. In this work, we provide a detailed review of more than 150 deep learning based models for text classification developed in recent years, and discuss their technical contributions, similarities, and strengths. We also provide a summary of more than 40 popular datasets widely used for text classification. Finally, we provide a quantitative analysis of the performance of different deep learning models on popular benchmarks, and discuss future research directions.
MetNet: A Neural Weather Model for Precipitation Forecasting
Mar 30, 2020Weather forecasting is a long standing scientific challenge with direct social and economic impact. The task is suitable for deep neural networks due to vast amounts of continuously collected data and a rich spatial and temporal structure that presents long range dependencies. We introduce MetNet, a neural network that forecasts precipitation up to 8 hours into the future at the high spatial resolution of 1 km$^2$ and at the temporal resolution of 2 minutes with a latency in the order of seconds. MetNet takes as input radar and satellite data and forecast lead time and produces a probabilistic precipitation map. The architecture uses axial self-attention to aggregate the global context from a large input patch corresponding to a million square kilometers. We evaluate the performance of MetNet at various precipitation thresholds and find that MetNet outperforms Numerical Weather Prediction at forecasts of up to 7 to 8 hours on the scale of the continental United States.
Axial Attention in Multidimensional Transformers
Dec 20, 2019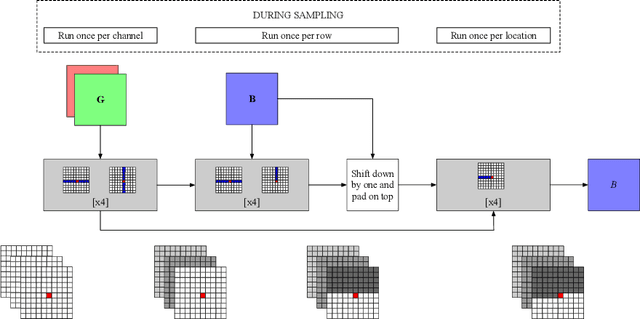

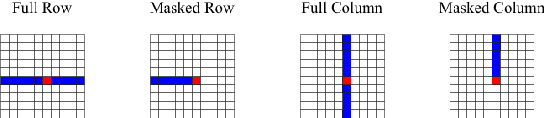
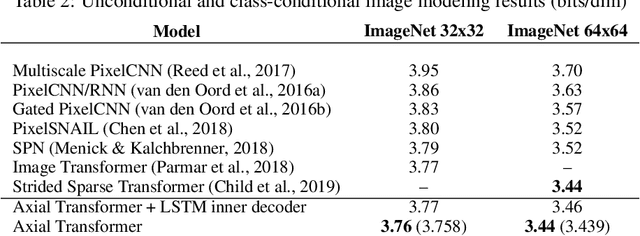
We propose Axial Transformers, a self-attention-based autoregressive model for images and other data organized as high dimensional tensors. Existing autoregressive models either suffer from excessively large computational resource requirements for high dimensional data, or make compromises in terms of distribution expressiveness or ease of implementation in order to decrease resource requirements. Our architecture, by contrast, maintains both full expressiveness over joint distributions over data and ease of implementation with standard deep learning frameworks, while requiring reasonable memory and computation and achieving state-of-the-art results on standard generative modeling benchmarks. Our models are based on axial attention, a simple generalization of self-attention that naturally aligns with the multiple dimensions of the tensors in both the encoding and the decoding settings. Notably the proposed structure of the layers allows for the vast majority of the context to be computed in parallel during decoding without introducing any independence assumptions. This semi-parallel structure goes a long way to making decoding from even a very large Axial Transformer broadly applicable. We demonstrate state-of-the-art results for the Axial Transformer on the ImageNet-32 and ImageNet-64 image benchmarks as well as on the BAIR Robotic Pushing video benchmark. We open source the implementation of Axial Transformers.