 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving fine-grained understanding in image-text pre-training
Jan 18, 2024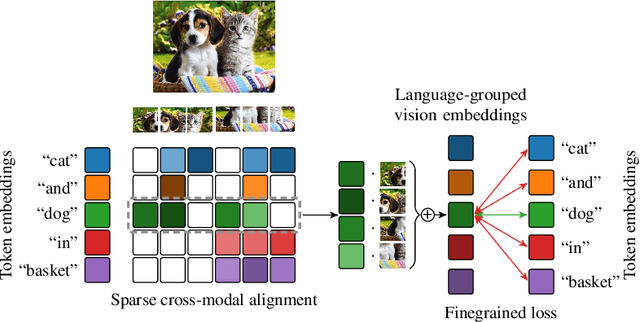
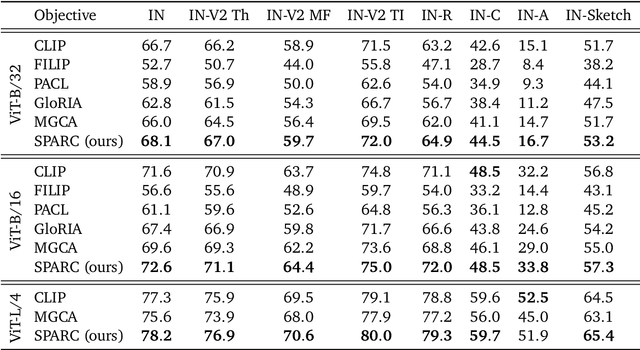
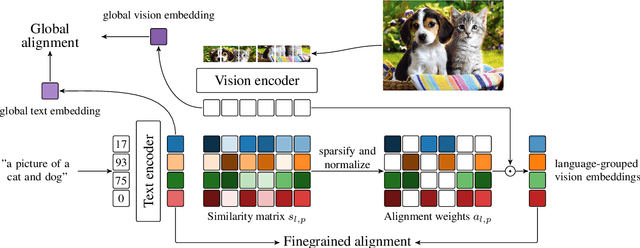
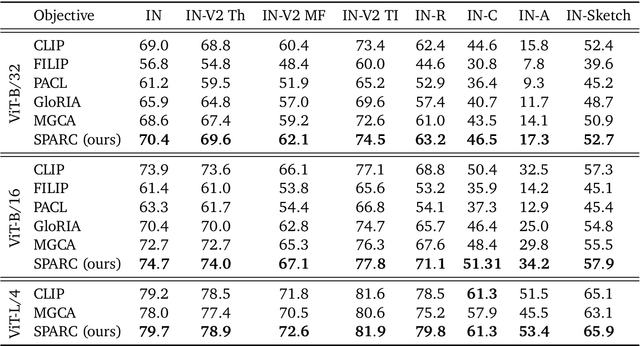
We introduce SPARse Fine-grained Contrastive Alignment (SPARC), a simple method for pretraining more fine-grained multimodal representations from image-text pairs. Given that multiple image patches often correspond to single words, we propose to learn a grouping of image patches for every token in the caption. To achieve this, we use a sparse similarity metric between image patches and language tokens and compute for each token a language-grouped vision embedding as the weighted average of patches. The token and language-grouped vision embeddings are then contrasted through a fine-grained sequence-wise loss that only depends on individual samples and does not require other batch samples as negatives. This enables more detailed information to be learned in a computationally inexpensive manner. SPARC combines this fine-grained loss with a contrastive loss between global image and text embeddings to learn representations that simultaneously encode global and local information. We thoroughly evaluate our proposed method and show improved performance over competing approaches both on image-level tasks relying on coarse-grained information, e.g. classification, as well as region-level tasks relying on fine-grained information, e.g. retrieval, object detection, and segmentation. Moreover, SPARC improves model faithfulness and captioning in foundational vision-language models.
Autoregressive Diffusion Models
Oct 05, 2021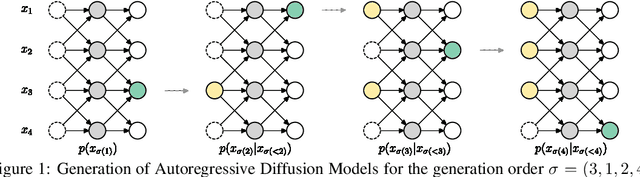

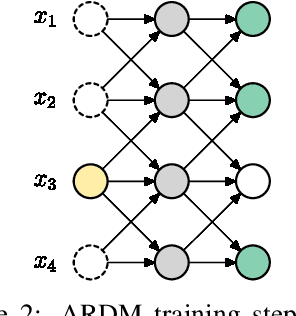

We introduce Autoregressive Diffusion Models (ARDMs), a model class encompassing and generalizing order-agnostic autoregressive models (Uria et al., 2014) and absorbing discrete diffusion (Austin et al., 2021), which we show are special cases of ARDMs under mild assumptions. ARDMs are simple to implement and easy to train. Unlike standard ARMs, they do not require causal masking of model representations, and can be trained using an efficient objective similar to modern probabilistic diffusion models that scales favourably to highly-dimensional data. At test time, ARDMs support parallel generation which can be adapted to fit any given generation budget. We find that ARDMs require significantly fewer steps than discrete diffusion models to attain the same performance. Finally, we apply ARDMs to lossless compression, and show that they are uniquely suited to this task. Contrary to existing approaches based on bits-back coding, ARDMs obtain compelling results not only on complete datasets, but also on compressing single data points. Moreover, this can be done using a modest number of network calls for (de)compression due to the model's adaptable parallel generation.
The Benchmark Lottery
Jul 14, 2021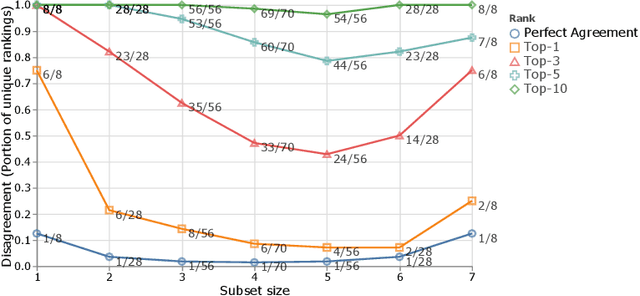

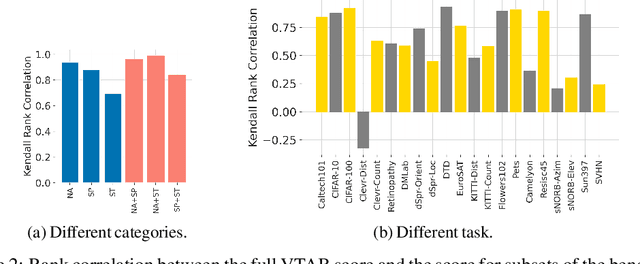
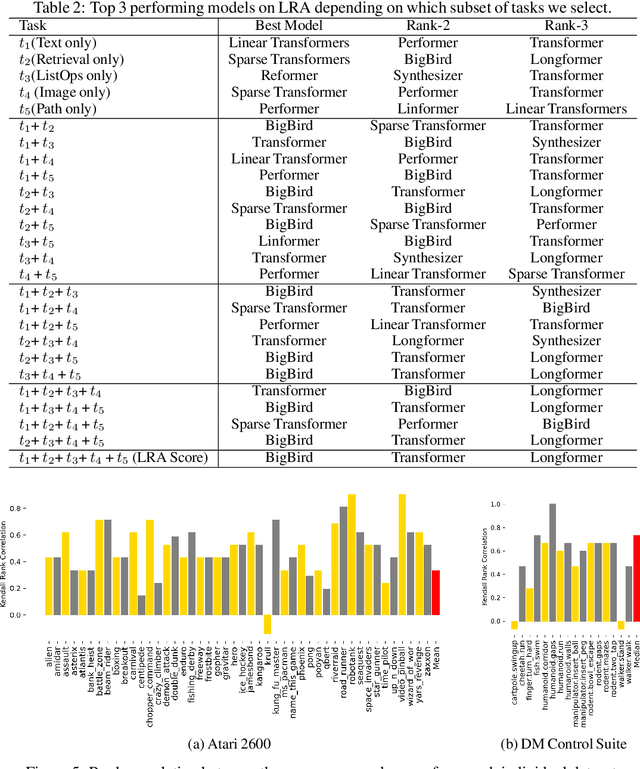
The world of empirical machine learning (ML) strongly relies on benchmarks in order to determine the relative effectiveness of different algorithms and methods. This paper proposes the notion of "a benchmark lottery" that describes the overall fragility of the ML benchmarking process. The benchmark lottery postulates that many factors, other than fundamental algorithmic superiority, may lead to a method being perceived as superior. On multiple benchmark setups that are prevalent in the ML community, we show that the relative performance of algorithms may be altered significantly simply by choosing different benchmark tasks, highlighting the fragility of the current paradigms and potential fallacious interpretation derived from benchmarking ML methods. Given that every benchmark makes a statement about what it perceives to be important, we argue that this might lead to biased progress in the community. We discuss the implications of the observed phenomena and provide recommendations on mitigating them using multiple machine learning domains and communities as use cases, including natural language processing, computer vision, information retrieval, recommender systems, and reinforcement learning.
A Spectral Energy Distance for Parallel Speech Synthesis
Aug 03, 2020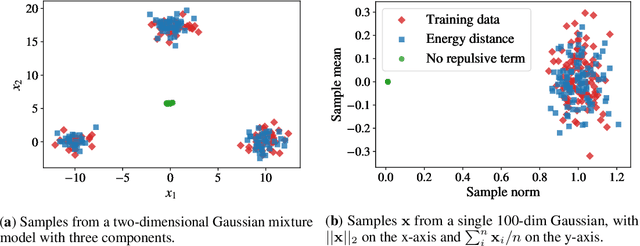
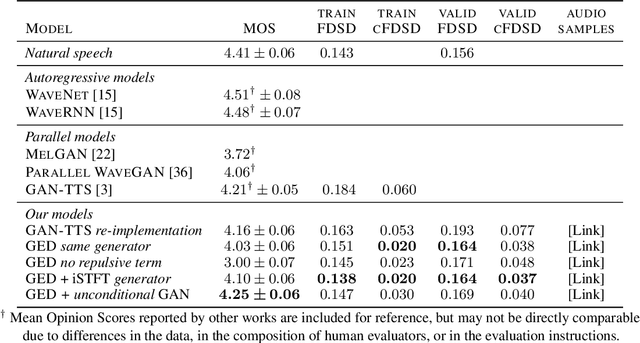
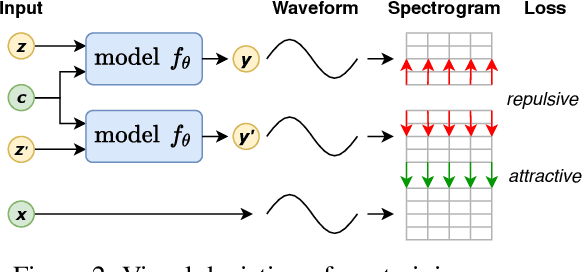
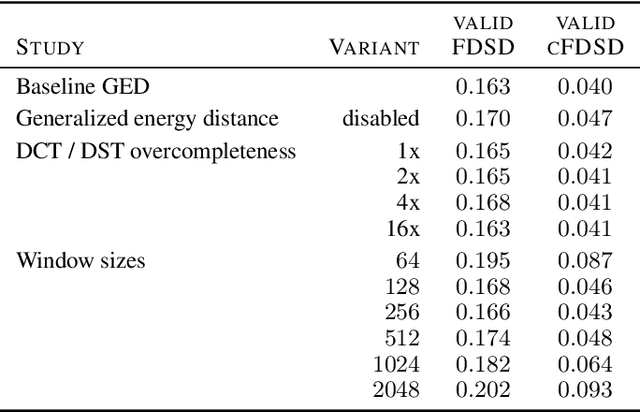
Speech synthesis is an important practical generative modeling problem that has seen great progress over the last few years, with likelihood-based autoregressive neural models now outperforming traditional concatenative systems. A downside of such autoregressive models is that they require executing tens of thousands of sequential operations per second of generated audio, making them ill-suited for deployment on specialized deep learning hardware. Here, we propose a new learning method that allows us to train highly parallel models of speech, without requiring access to an analytical likelihood function. Our approach is based on a generalized energy distance between the distributions of the generated and real audio. This spectral energy distance is a proper scoring rule with respect to the distribution over magnitude-spectrograms of the generated waveform audio and offers statistical consistency guarantees. The distance can be calculated from minibatches without bias, and does not involve adversarial learning, yielding a stable and consistent method for training implicit generative models. Empirically, we achieve state-of-the-art generation quality among implicit generative models, as judged by the recently-proposed cFDSD metric. When combining our method with adversarial techniques, we also improve upon the recently-proposed GAN-TTS model in terms of Mean Opinion Score as judged by trained human evaluators.
IDF++: Analyzing and Improving Integer Discrete Flows for Lossless Compression
Jun 22, 2020
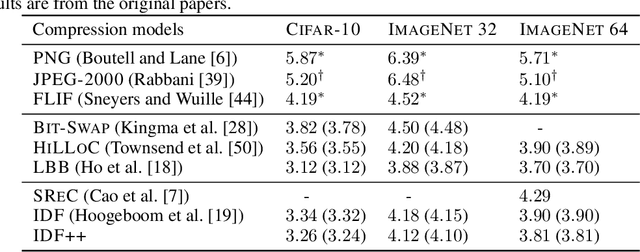


In this paper we analyse and improve integer discrete flows for lossless compression. Integer discrete flows are a recently proposed class of models that learn invertible transformations for integer-valued random variables. Due to its discrete nature, they can be combined in a straightforward manner with entropy coding schemes for lossless compression without the need for bits-back coding. We discuss the potential difference in flexibility between invertible flows for discrete random variables and flows for continuous random variables and show that (integer) discrete flows are more flexible than previously claimed. We furthermore investigate the influence of quantization operators on optimization and gradient bias in integer discrete flows. Finally, we introduce modifications to the architecture to improve the performance of this model class for lossless compression.
BriarPatches: Pixel-Space Interventions for Inducing Demographic Parity
Dec 17, 2018
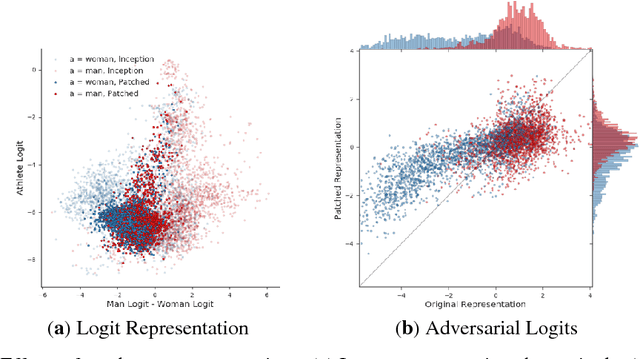
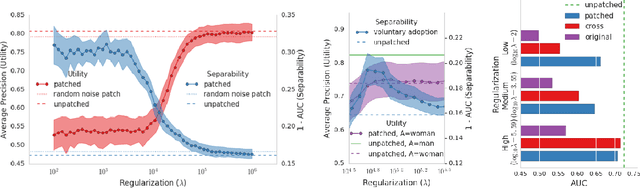
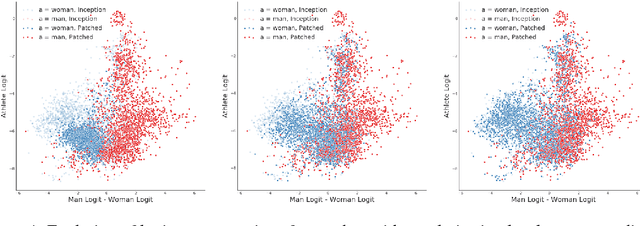
We introduce the BriarPatch, a pixel-space intervention that obscures sensitive attributes from representations encoded in pre-trained classifiers. The patches encourage internal model representations not to encode sensitive information, which has the effect of pushing downstream predictors towards exhibiting demographic parity with respect to the sensitive information. The net result is that these BriarPatches provide an intervention mechanism available at user level, and complements prior research on fair representations that were previously only applicable by model developers and ML experts.