 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Model Dialog Games for Self-Improvement
Feb 04, 2025



The increasing demand for high-quality, diverse training data poses a significant bottleneck in advancing vision-language models (VLMs). This paper presents VLM Dialog Games, a novel and scalable self-improvement framework for VLMs. Our approach leverages self-play between two agents engaged in a goal-oriented play centered around image identification. By filtering for successful game interactions, we automatically curate a high-quality dataset of interleaved images and text. We demonstrate that fine-tuning on this synthetic data leads to performance gains on downstream tasks and generalises across datasets. Moreover, as the improvements in the model lead to better game play, this procedure can be applied iteratively. This work paves the way for self-improving VLMs, with potential applications in various real-world scenarios especially when the high-quality multimodal data is scarce.
Learning Successor Features the Simple Way
Oct 29, 2024



In Deep Reinforcement Learning (RL), it is a challenge to learn representations that do not exhibit catastrophic forgetting or interference in non-stationary environments. Successor Features (SFs) offer a potential solution to this challenge. However, canonical techniques for learning SFs from pixel-level observations often lead to representation collapse, wherein representations degenerate and fail to capture meaningful variations in the data. More recent methods for learning SFs can avoid representation collapse, but they often involve complex losses and multiple learning phases, reducing their efficiency. We introduce a novel, simple method for learning SFs directly from pixels. Our approach uses a combination of a Temporal-difference (TD) loss and a reward prediction loss, which together capture the basic mathematical definition of SFs. We show that our approach matches or outperforms existing SF learning techniques in both 2D (Minigrid), 3D (Miniworld) mazes and Mujoco, for both single and continual learning scenarios. As well, our technique is efficient, and can reach higher levels of performance in less time than other approaches. Our work provides a new, streamlined technique for learning SFs directly from pixel observations, with no pretraining required.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Mar 12, 2024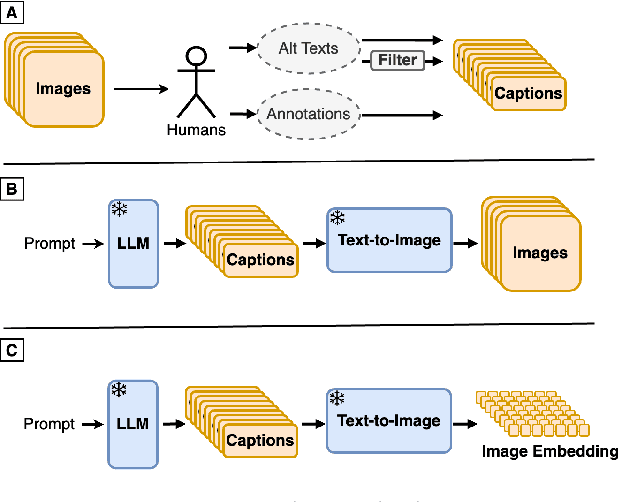
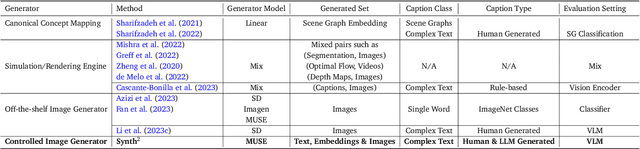


The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). We propose a novel approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs pretraining a text-to-image model to synthesize image embeddings starting from captions generated by an LLM. These synthetic pairs are then used to train a VLM. Extensive experiments demonstrate that the VLM trained with synthetic data exhibits comparable performance on image captioning, while requiring a fraction of the data used by models trained solely on human-annotated data. In particular, we outperform the baseline by 17% through augmentation with a synthetic dataset. Furthermore, we show that synthesizing in the image embedding space is 25% faster than in the pixel space. This research introduces a promising technique for generating large-scale, customizable image datasets, leading to enhanced VLM performance and wider applicability across various domains, all with improved data efficiency and resource utilization.
Improving fine-grained understanding in image-text pre-training
Jan 18, 2024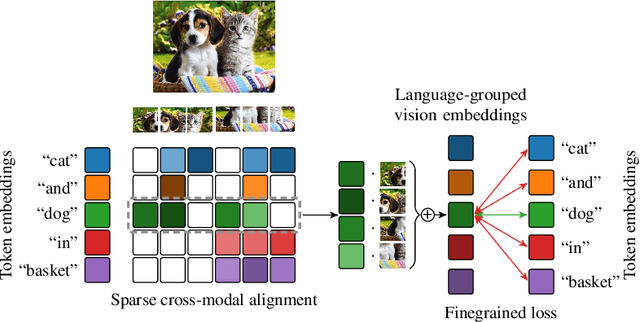
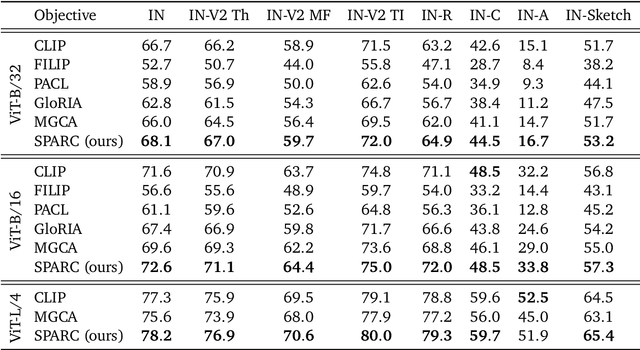
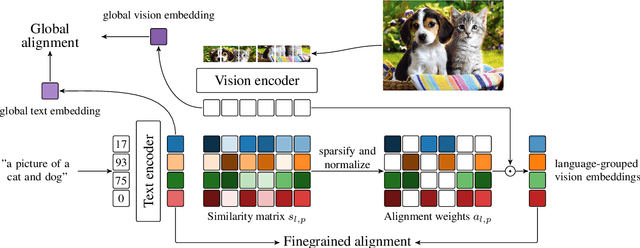
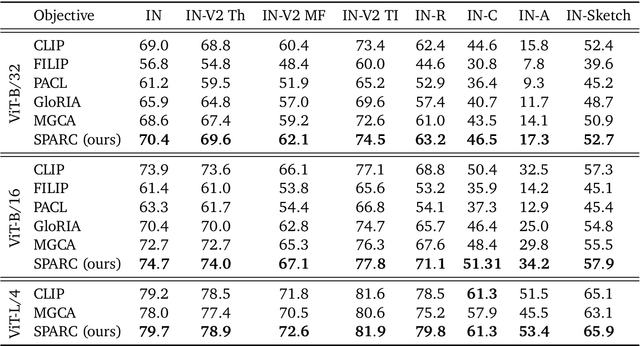
We introduce SPARse Fine-grained Contrastive Alignment (SPARC), a simple method for pretraining more fine-grained multimodal representations from image-text pairs. Given that multiple image patches often correspond to single words, we propose to learn a grouping of image patches for every token in the caption. To achieve this, we use a sparse similarity metric between image patches and language tokens and compute for each token a language-grouped vision embedding as the weighted average of patches. The token and language-grouped vision embeddings are then contrasted through a fine-grained sequence-wise loss that only depends on individual samples and does not require other batch samples as negatives. This enables more detailed information to be learned in a computationally inexpensive manner. SPARC combines this fine-grained loss with a contrastive loss between global image and text embeddings to learn representations that simultaneously encode global and local information. We thoroughly evaluate our proposed method and show improved performance over competing approaches both on image-level tasks relying on coarse-grained information, e.g. classification, as well as region-level tasks relying on fine-grained information, e.g. retrieval, object detection, and segmentation. Moreover, SPARC improves model faithfulness and captioning in foundational vision-language models.
Encoders and Ensembles for Task-Free Continual Learning
May 27, 2021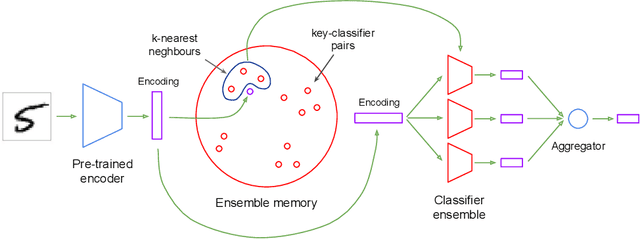
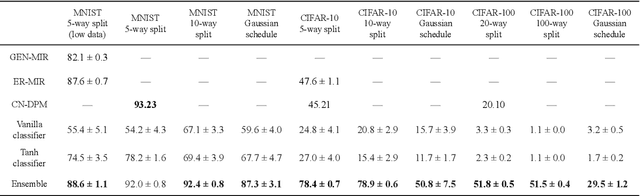

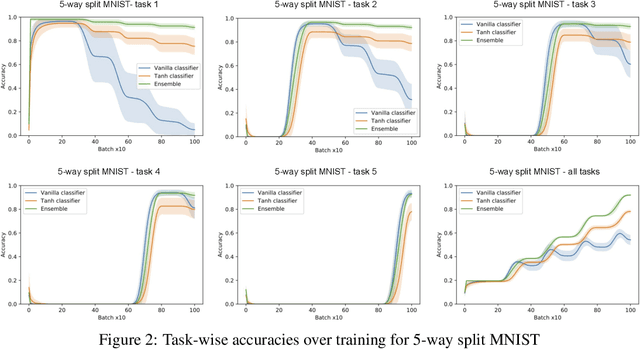
We present an architecture that is effective for continual learning in an especially demanding setting, where task boundaries do not exist or are unknown. Our architecture comprises an encoder, pre-trained on a separate dataset, and an ensemble of simple one-layer classifiers. Two main innovations are required to make this combination work. First, the provision of suitably generic pre-trained encoders has been made possible thanks to recent progress in self-supervised training methods. Second, pairing each classifier in the ensemble with a key, where the key-space is identical to the latent space of the encoder, allows them to be used collectively, yet selectively, via k-nearest neighbour lookup. We show that models trained with the encoders-and-ensembles architecture are state-of-the-art for the task-free setting on standard image classification continual learning benchmarks, and improve on prior state-of-the-art by a large margin in the most challenging cases. We also show that the architecture learns well in a fully incremental setting, where one class is learned at a time, and we demonstrate its effectiveness in this setting with up to 100 classes. Finally, we show that the architecture works in a task-free continual learning context where the data distribution changes gradually, and existing approaches requiring knowledge of task boundaries cannot be applied.
Continual Reinforcement Learning with Multi-Timescale Replay
Apr 16, 2020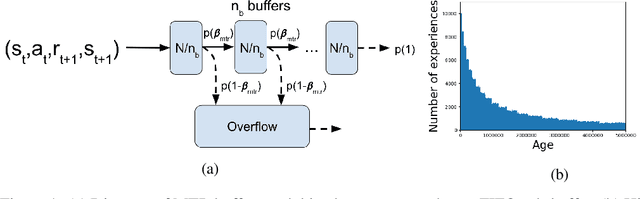

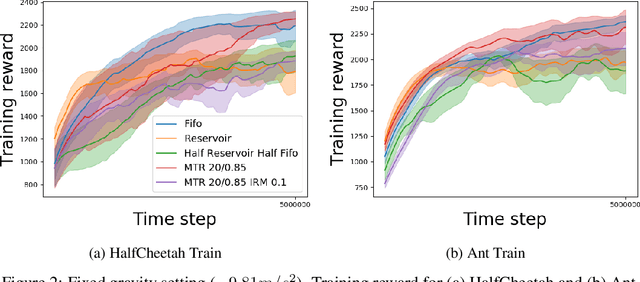
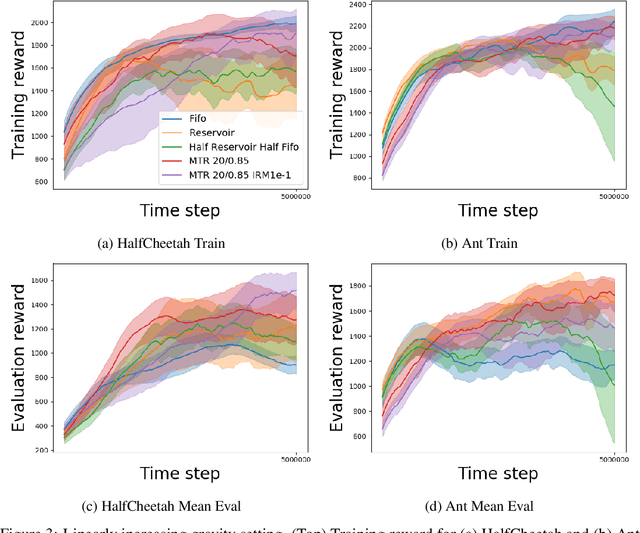
In this paper, we propose a multi-timescale replay (MTR) buffer for improving continual learning in RL agents faced with environments that are changing continuously over time at timescales that are unknown to the agent. The basic MTR buffer comprises a cascade of sub-buffers that accumulate experiences at different timescales, enabling the agent to improve the trade-off between adaptation to new data and retention of old knowledge. We also combine the MTR framework with invariant risk minimization, with the idea of encouraging the agent to learn a policy that is robust across the various environments it encounters over time. The MTR methods are evaluated in three different continual learning settings on two continuous control tasks and, in many cases, show improvement over the baselines.
An Explicitly Relational Neural Network Architecture
May 24, 2019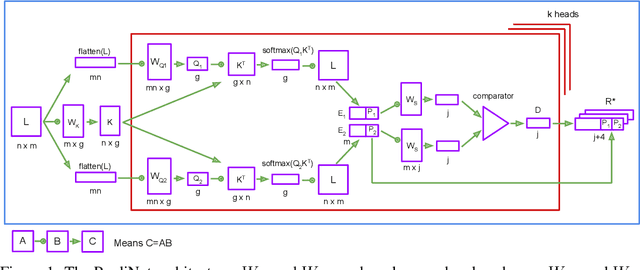
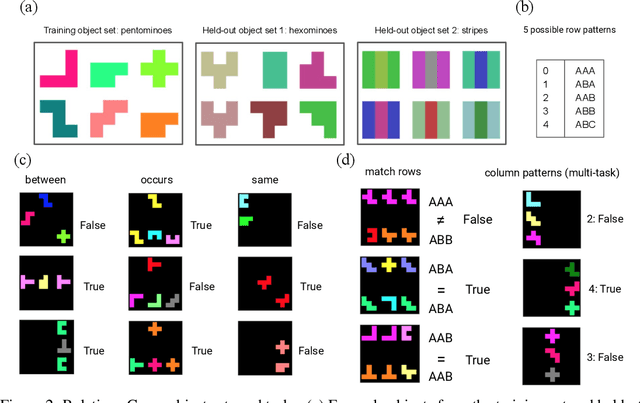
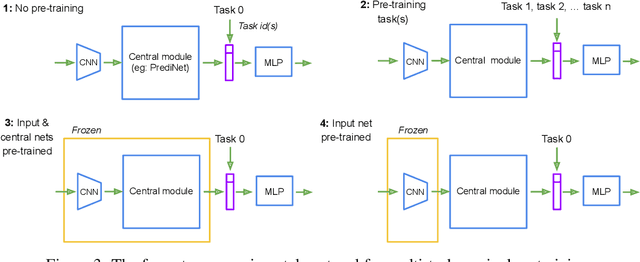
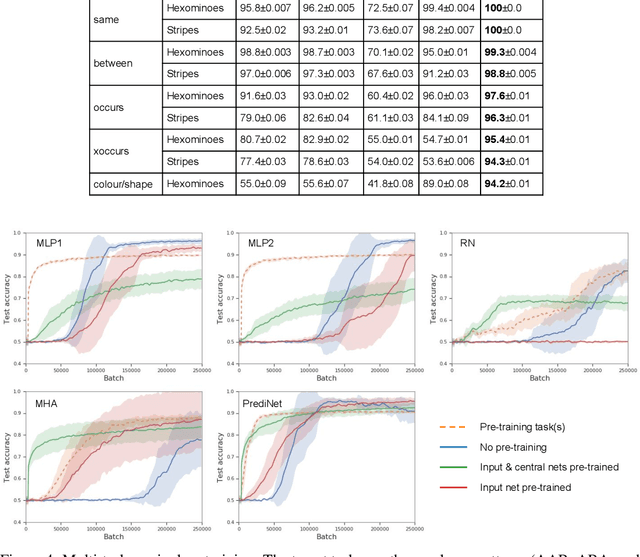
With a view to bridging the gap between deep learning and symbolic AI, we present a novel end-to-end neural network architecture that learns to form propositional representations with an explicitly relational structure from raw pixel data. In order to evaluate and analyse the architecture, we introduce a family of simple visual relational reasoning tasks of varying complexity. We show that the proposed architecture, when pre-trained on a curriculum of such tasks, learns to generate reusable representations that better facilitate subsequent learning on previously unseen tasks when compared to a number of baseline architectures. The workings of a successfully trained model are visualised to shed some light on how the architecture functions.
Policy Consolidation for Continual Reinforcement Learning
Feb 01, 2019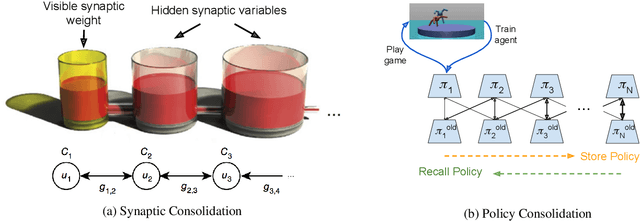
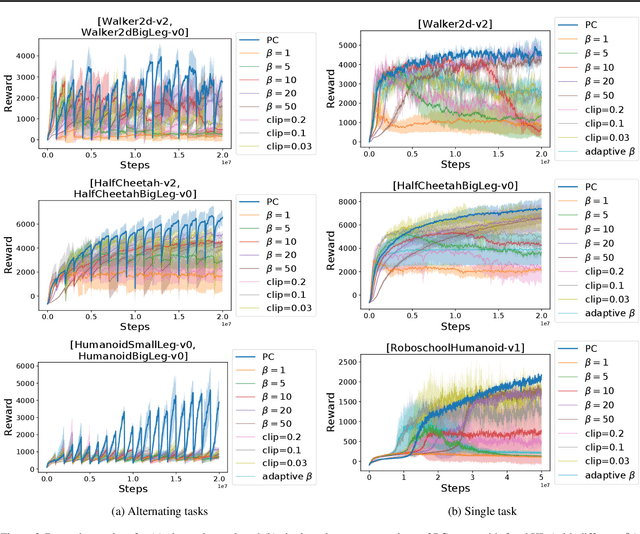
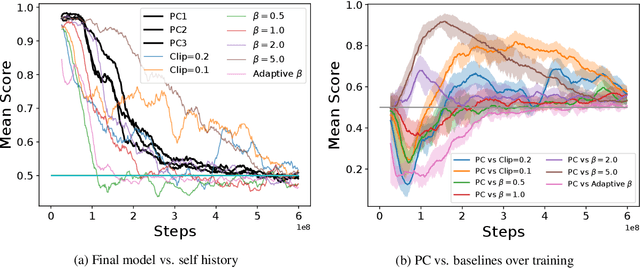
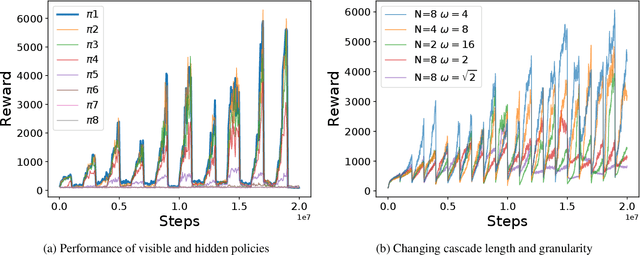
We propose a method for tackling catastrophic forgetting in deep reinforcement learning that is \textit{agnostic} to the timescale of changes in the distribution of experiences, does not require knowledge of task boundaries, and can adapt in \textit{continuously} changing environments. In our \textit{policy consolidation} model, the policy network interacts with a cascade of hidden networks that simultaneously remember the agent's policy at a range of timescales and regularise the current policy by its own history, thereby improving its ability to learn without forgetting. We find that the model improves continual learning relative to baselines on a number of continuous control tasks in single-task, alternating two-task, and multi-agent competitive self-play settings.
Continual Reinforcement Learning with Complex Synapses
Jun 19, 2018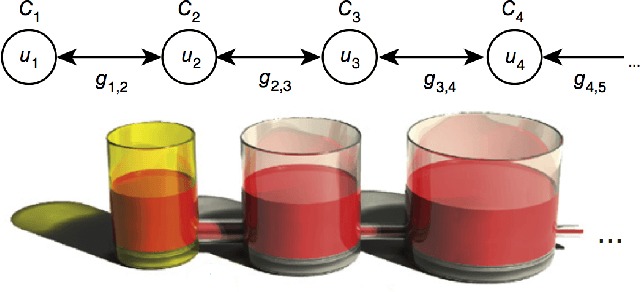
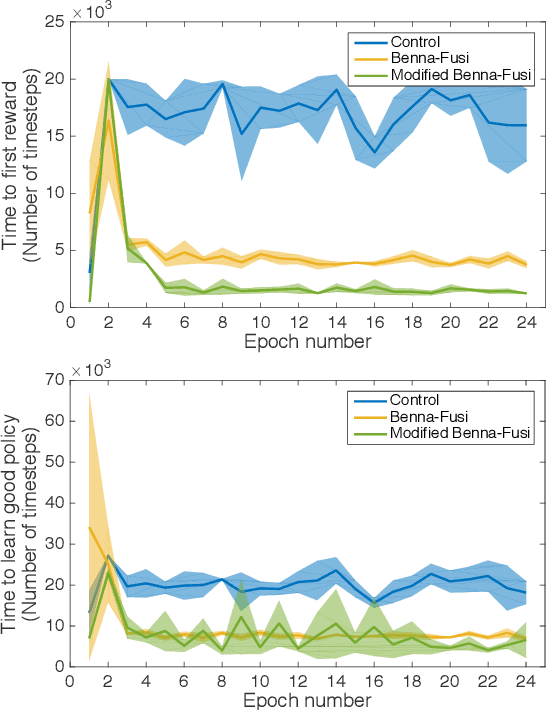
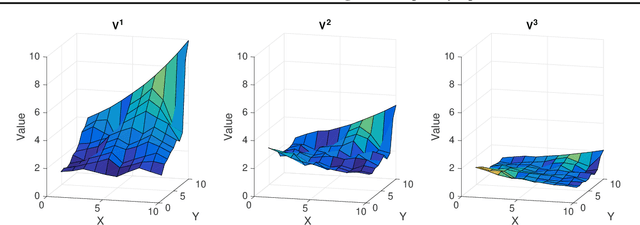
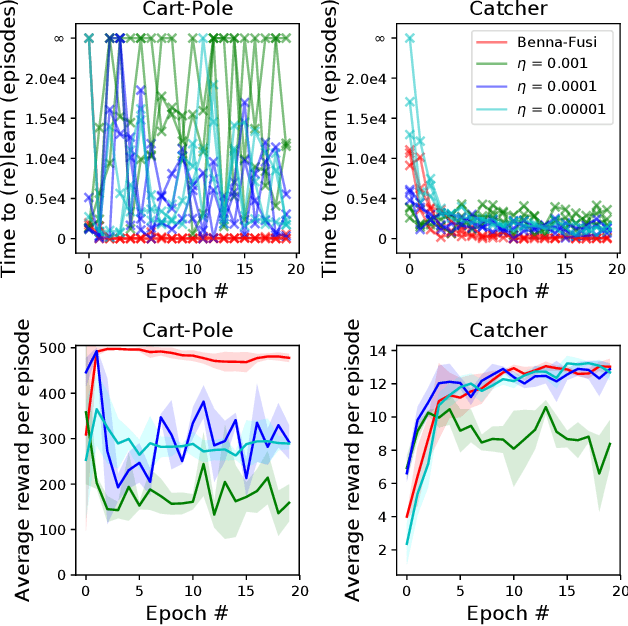
Unlike humans, who are capable of continual learning over their lifetimes, artificial neural networks have long been known to suffer from a phenomenon known as catastrophic forgetting, whereby new learning can lead to abrupt erasure of previously acquired knowledge. Whereas in a neural network the parameters are typically modelled as scalar values, an individual synapse in the brain comprises a complex network of interacting biochemical components that evolve at different timescales. In this paper, we show that by equipping tabular and deep reinforcement learning agents with a synaptic model that incorporates this biological complexity (Benna & Fusi, 2016), catastrophic forgetting can be mitigated at multiple timescales. In particular, we find that as well as enabling continual learning across sequential training of two simple tasks, it can also be used to overcome within-task forgetting by reducing the need for an experience replay database.