 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving fine-grained understanding in image-text pre-training
Jan 18, 2024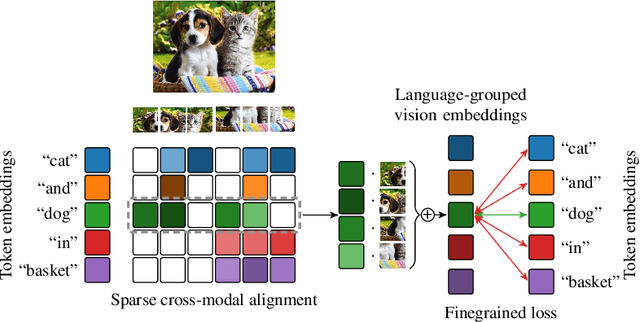
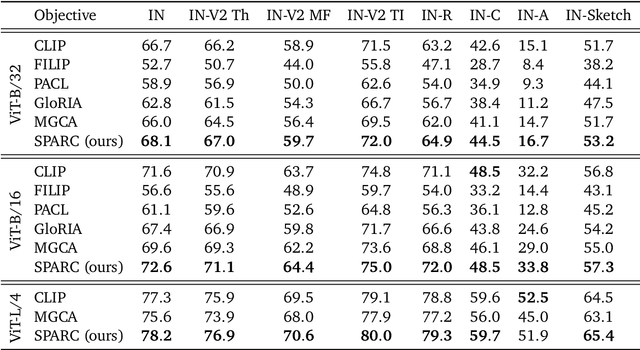
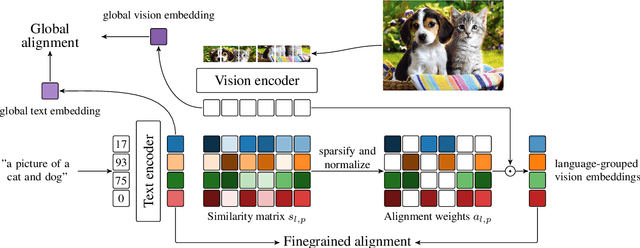
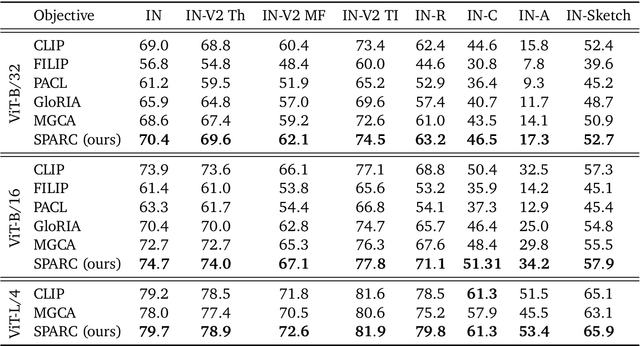
We introduce SPARse Fine-grained Contrastive Alignment (SPARC), a simple method for pretraining more fine-grained multimodal representations from image-text pairs. Given that multiple image patches often correspond to single words, we propose to learn a grouping of image patches for every token in the caption. To achieve this, we use a sparse similarity metric between image patches and language tokens and compute for each token a language-grouped vision embedding as the weighted average of patches. The token and language-grouped vision embeddings are then contrasted through a fine-grained sequence-wise loss that only depends on individual samples and does not require other batch samples as negatives. This enables more detailed information to be learned in a computationally inexpensive manner. SPARC combines this fine-grained loss with a contrastive loss between global image and text embeddings to learn representations that simultaneously encode global and local information. We thoroughly evaluate our proposed method and show improved performance over competing approaches both on image-level tasks relying on coarse-grained information, e.g. classification, as well as region-level tasks relying on fine-grained information, e.g. retrieval, object detection, and segmentation. Moreover, SPARC improves model faithfulness and captioning in foundational vision-language models.
Encoders and Ensembles for Task-Free Continual Learning
May 27, 2021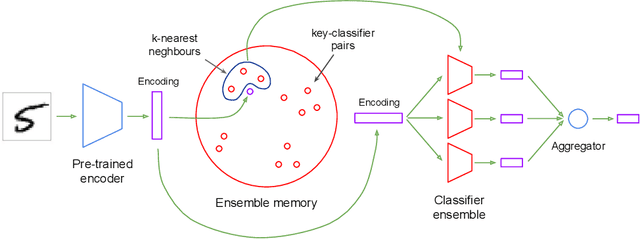
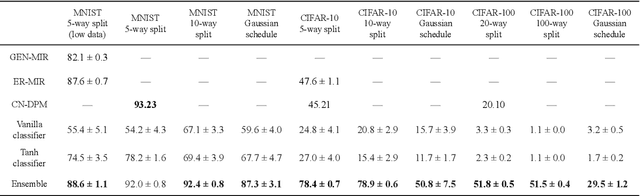

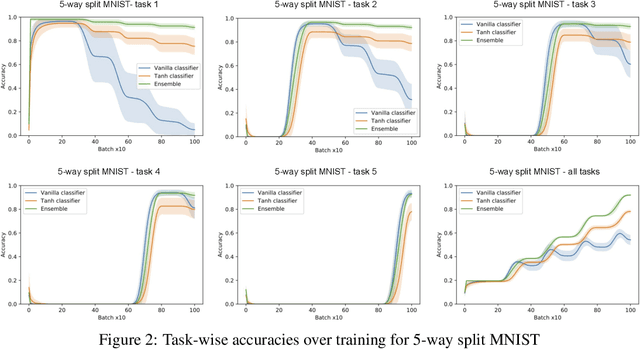
We present an architecture that is effective for continual learning in an especially demanding setting, where task boundaries do not exist or are unknown. Our architecture comprises an encoder, pre-trained on a separate dataset, and an ensemble of simple one-layer classifiers. Two main innovations are required to make this combination work. First, the provision of suitably generic pre-trained encoders has been made possible thanks to recent progress in self-supervised training methods. Second, pairing each classifier in the ensemble with a key, where the key-space is identical to the latent space of the encoder, allows them to be used collectively, yet selectively, via k-nearest neighbour lookup. We show that models trained with the encoders-and-ensembles architecture are state-of-the-art for the task-free setting on standard image classification continual learning benchmarks, and improve on prior state-of-the-art by a large margin in the most challenging cases. We also show that the architecture learns well in a fully incremental setting, where one class is learned at a time, and we demonstrate its effectiveness in this setting with up to 100 classes. Finally, we show that the architecture works in a task-free continual learning context where the data distribution changes gradually, and existing approaches requiring knowledge of task boundaries cannot be applied.